 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing for Reading Times
Apr 20, 2026Probing has shown that language model representations encode rich linguistic information, but it remains unclear whether they also capture cognitive signals about human processing. In this work, we probe language model representations for human reading times. Using regularized linear regression on two eye-tracking corpora spanning five languages (English, Greek, Hebrew, Russian, and Turkish), we compare the representations from every model layer against scalar predictors -- surprisal, information value, and logit-lens surprisal. We find that the representations from early layers outperform surprisal in predicting early-pass measures such as first fixation and gaze duration. The concentration of predictive power in the early layers suggests that human-like processing signatures are captured by low-level structural or lexical representations, pointing to a functional alignment between model depth and the temporal stages of human reading. In contrast, for late-pass measures such as total reading time, scalar surprisal remains superior, despite its being a much more compressed representation. We also observe performance gains when using both surprisal and early-layer representations. Overall, we find that the best-performing predictor varies strongly depending on the language and eye-tracking measure.
Is Information Density Uniform when Utterances are Grounded on Perception and Discourse?
Feb 16, 2026The Uniform Information Density (UID) hypothesis posits that speakers are subject to a communicative pressure to distribute information evenly within utterances, minimising surprisal variance. While this hypothesis has been tested empirically, prior studies are limited exclusively to text-only inputs, abstracting away from the perceptual context in which utterances are produced. In this work, we present the first computational study of UID in visually grounded settings. We estimate surprisal using multilingual vision-and-language models over image-caption data in 30 languages and visual storytelling data in 13 languages, together spanning 11 families. We find that grounding on perception consistently smooths the distribution of information, increasing both global and local uniformity across typologically diverse languages compared to text-only settings. In visual narratives, grounding in both image and discourse contexts has additional effects, with the strongest surprisal reductions occurring at the onset of discourse units. Overall, this study takes a first step towards modelling the temporal dynamics of information flow in ecologically plausible, multimodal language use, and finds that grounded language exhibits greater information uniformity, supporting a context-sensitive formulation of UID.
Reasoning aligns language models to human cognition
Feb 09, 2026Do language models make decisions under uncertainty like humans do, and what role does chain-of-thought (CoT) reasoning play in the underlying decision process? We introduce an active probabilistic reasoning task that cleanly separates sampling (actively acquiring evidence) from inference (integrating evidence toward a decision). Benchmarking humans and a broad set of contemporary large language models against near-optimal reference policies reveals a consistent pattern: extended reasoning is the key determinant of strong performance, driving large gains in inference and producing belief trajectories that become strikingly human-like, while yielding only modest improvements in active sampling. To explain these differences, we fit a mechanistic model that captures systematic deviations from optimal behavior via four interpretable latent variables: memory, strategy, choice bias, and occlusion awareness. This model places humans and models in a shared low-dimensional cognitive space, reproduces behavioral signatures across agents, and shows how chain-of-thought shifts language models toward human-like regimes of evidence accumulation and belief-to-choice mapping, tightening alignment in inference while leaving a persistent gap in information acquisition.
A Behavioural and Representational Evaluation of Goal-Directedness in Language Model Agents
Feb 09, 2026Understanding an agent's goals helps explain and predict its behaviour, yet there is no established methodology for reliably attributing goals to agentic systems. We propose a framework for evaluating goal-directedness that integrates behavioural evaluation with interpretability-based analyses of models' internal representations. As a case study, we examine an LLM agent navigating a 2D grid world toward a goal state. Behaviourally, we evaluate the agent against an optimal policy across varying grid sizes, obstacle densities, and goal structures, finding that performance scales with task difficulty while remaining robust to difficulty-preserving transformations and complex goal structures. We then use probing methods to decode the agent's internal representations of the environment state and its multi-step action plans. We find that the LLM agent non-linearly encodes a coarse spatial map of the environment, preserving approximate task-relevant cues about its position and the goal location; that its actions are broadly consistent with these internal representations; and that reasoning reorganises them, shifting from broader environment structural cues toward information supporting immediate action selection. Our findings support the view that introspective examination is required beyond behavioural evaluations to characterise how agents represent and pursue their objectives.
Structure-Conditional Minimum Bayes Risk Decoding
Oct 23, 2025Minimum Bayes Risk (MBR) decoding has seen renewed interest as an alternative to traditional generation strategies. While MBR has proven effective in machine translation, where the variability of a language model's outcome space is naturally constrained, it may face challenges in more open-ended tasks such as dialogue or instruction-following. We hypothesise that in such settings, applying MBR with standard similarity-based utility functions may result in selecting responses that are broadly representative of the model's distribution, yet sub-optimal with respect to any particular grouping of generations that share an underlying latent structure. In this work, we introduce three lightweight adaptations to the utility function, designed to make MBR more sensitive to structural variability in the outcome space. To test our hypothesis, we curate a dataset capturing three representative types of latent structure: dialogue act, emotion, and response structure (e.g., a sentence, a paragraph, or a list). We further propose two metrics to evaluate the structural optimality of MBR. Our analysis demonstrates that common similarity-based utility functions fall short by these metrics. In contrast, our proposed adaptations considerably improve structural optimality. Finally, we evaluate our approaches on real-world instruction-following benchmarks, AlpacaEval and MT-Bench, and show that increased structural sensitivity improves generation quality by up to 13.7 percentage points in win rate.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025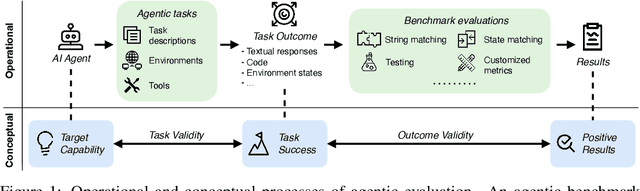
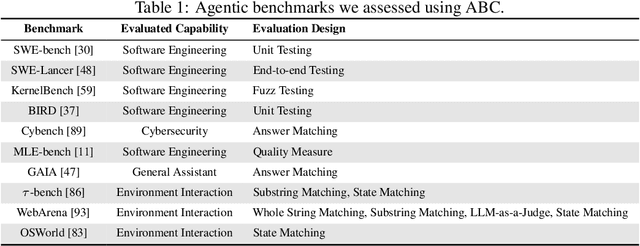
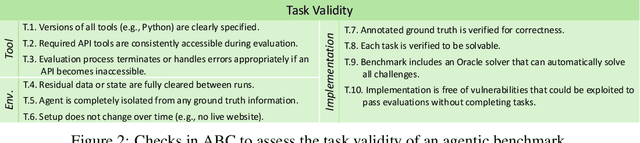
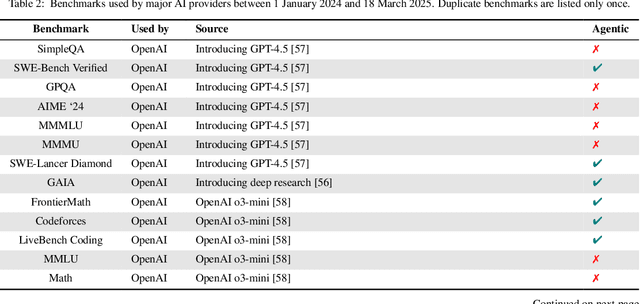
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
Language Models over Canonical Byte-Pair Encodings
Jun 09, 2025Modern language models represent probability distributions over character strings as distributions over (shorter) token strings derived via a deterministic tokenizer, such as byte-pair encoding. While this approach is highly effective at scaling up language models to large corpora, its current incarnations have a concerning property: the model assigns nonzero probability mass to an exponential number of $\it{noncanonical}$ token encodings of each character string -- these are token strings that decode to valid character strings but are impossible under the deterministic tokenizer (i.e., they will never be seen in any training corpus, no matter how large). This misallocation is both erroneous, as noncanonical strings never appear in training data, and wasteful, diverting probability mass away from plausible outputs. These are avoidable mistakes! In this work, we propose methods to enforce canonicality in token-level language models, ensuring that only canonical token strings are assigned positive probability. We present two approaches: (1) canonicality by conditioning, leveraging test-time inference strategies without additional training, and (2) canonicality by construction, a model parameterization that guarantees canonical outputs but requires training. We demonstrate that fixing canonicality mistakes improves the likelihood of held-out data for several models and corpora.
Information Locality as an Inductive Bias for Neural Language Models
Jun 05, 2025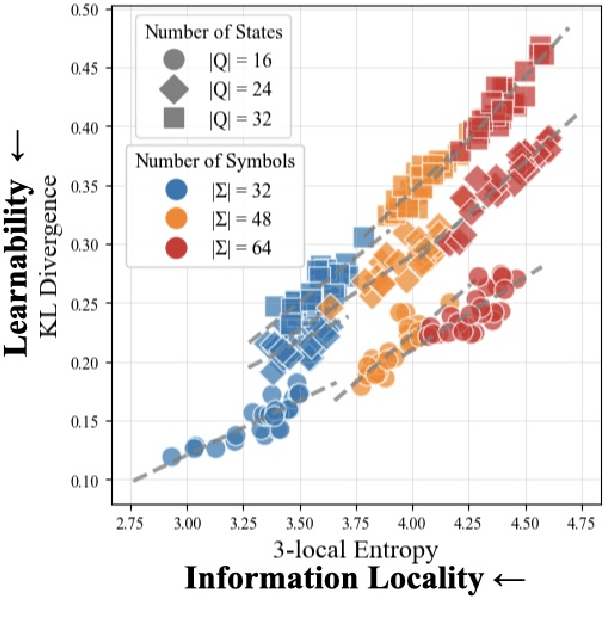
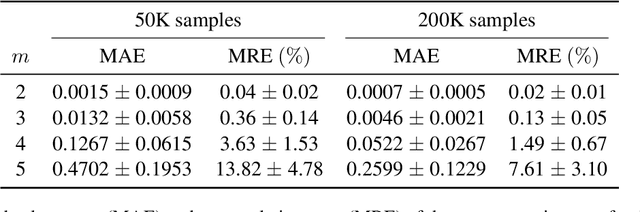
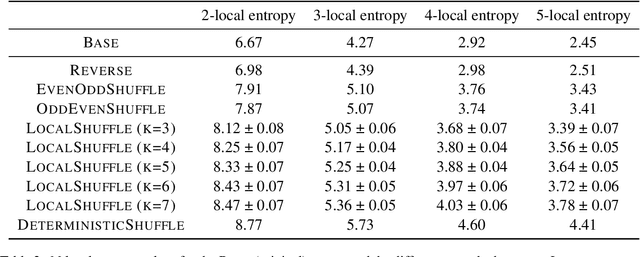
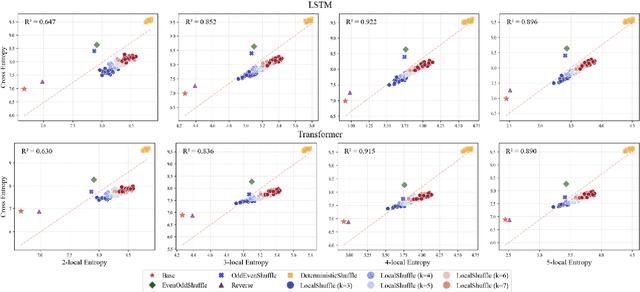
Inductive biases are inherent in every machine learning system, shaping how models generalize from finite data. In the case of neural language models (LMs), debates persist as to whether these biases align with or diverge from human processing constraints. To address this issue, we propose a quantitative framework that allows for controlled investigations into the nature of these biases. Within our framework, we introduce $m$-local entropy$\unicode{x2013}$an information-theoretic measure derived from average lossy-context surprisal$\unicode{x2013}$that captures the local uncertainty of a language by quantifying how effectively the $m-1$ preceding symbols disambiguate the next symbol. In experiments on both perturbed natural language corpora and languages defined by probabilistic finite-state automata (PFSAs), we show that languages with higher $m$-local entropy are more difficult for Transformer and LSTM LMs to learn. These results suggest that neural LMs, much like humans, are highly sensitive to the local statistical structure of a language.
The Harmonic Structure of Information Contours
Jun 04, 2025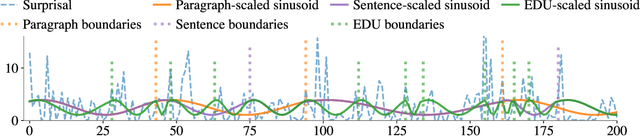
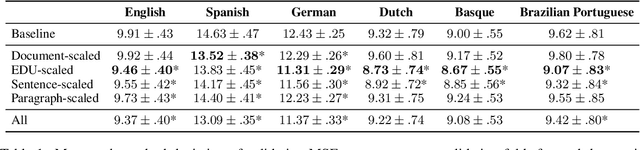
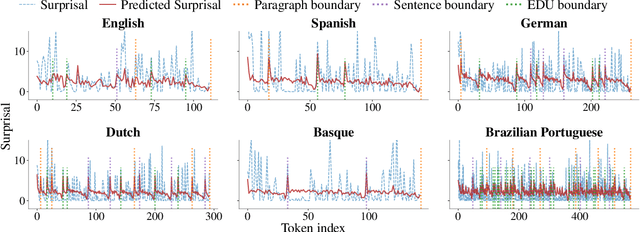
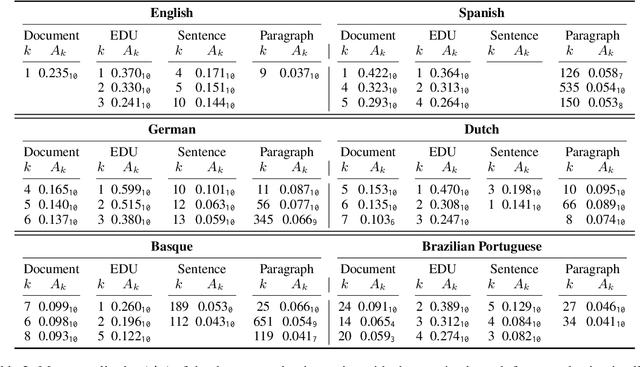
The uniform information density (UID) hypothesis proposes that speakers aim to distribute information evenly throughout a text, balancing production effort and listener comprehension difficulty. However, language typically does not maintain a strictly uniform information rate; instead, it fluctuates around a global average. These fluctuations are often explained by factors such as syntactic constraints, stylistic choices, or audience design. In this work, we explore an alternative perspective: that these fluctuations may be influenced by an implicit linguistic pressure towards periodicity, where the information rate oscillates at regular intervals, potentially across multiple frequencies simultaneously. We apply harmonic regression and introduce a novel extension called time scaling to detect and test for such periodicity in information contours. Analyzing texts in English, Spanish, German, Dutch, Basque, and Brazilian Portuguese, we find consistent evidence of periodic patterns in information rate. Many dominant frequencies align with discourse structure, suggesting these oscillations reflect meaningful linguistic organization. Beyond highlighting the connection between information rate and discourse structure, our approach offers a general framework for uncovering structural pressures at various levels of linguistic granularity.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025
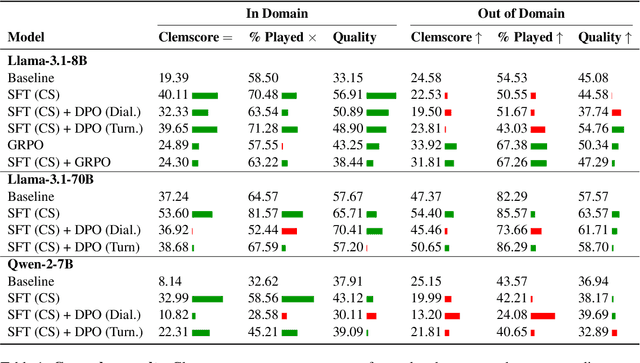


Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.