 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Proper Treatment of Tokenization in Psycholinguistics
Oct 03, 2024
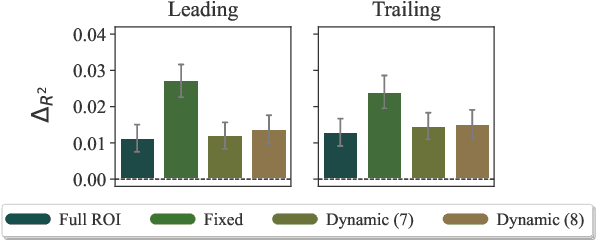

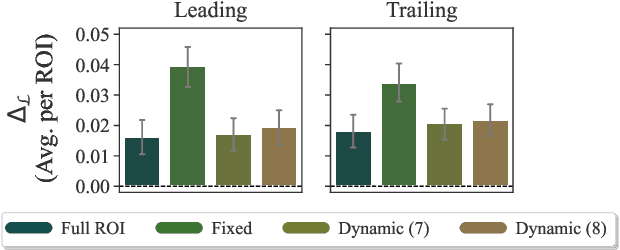
Language models are widely used in computational psycholinguistics to test theories that relate the negative log probability (the surprisal) of a region of interest (a substring of characters) under a language model to its cognitive cost experienced by readers, as operationalized, for example, by gaze duration on the region. However, the application of modern language models to psycholinguistic studies is complicated by the practice of using tokenization as an intermediate step in training a model. Doing so results in a language model over token strings rather than one over character strings. Vexingly, regions of interest are generally misaligned with these token strings. The paper argues that token-level language models should be (approximately) marginalized into character-level language models before they are used in psycholinguistic studies to compute the surprisal of a region of interest; then, the marginalized character-level language model can be used to compute the surprisal of an arbitrary character substring, which we term a focal area, that the experimenter may wish to use as a predictor. Our proposal of marginalizing a token-level model into a character-level one solves this misalignment issue independently of the tokenization scheme. Empirically, we discover various focal areas whose surprisal is a better psychometric predictor than the surprisal of the region of interest itself.
The Foundations of Tokenization: Statistical and Computational Concerns
Jul 16, 2024Tokenization - the practice of converting strings of characters over an alphabet into sequences of tokens over a vocabulary - is a critical yet under-theorized step in the NLP pipeline. Notably, it remains the only major step not fully integrated into widely used end-to-end neural models. This paper aims to address this theoretical gap by laying the foundations of tokenization from a formal perspective. By articulating and extending basic properties about the category of stochastic maps, we propose a unified framework for representing and analyzing tokenizer models. This framework allows us to establish general conditions for the use of tokenizers. In particular, we formally establish the necessary and sufficient conditions for a tokenizer model to preserve the consistency of statistical estimators. Additionally, we discuss statistical and computational concerns crucial for the design and implementation of tokenizer models. The framework and results advanced in this paper represent a step toward a robust theoretical foundation for neural language modeling.
The Role of $n$-gram Smoothing in the Age of Neural Networks
Mar 25, 2024For nearly three decades, language models derived from the $n$-gram assumption held the state of the art on the task. The key to their success lay in the application of various smoothing techniques that served to combat overfitting. However, when neural language models toppled $n$-gram models as the best performers, $n$-gram smoothing techniques became less relevant. Indeed, it would hardly be an understatement to suggest that the line of inquiry into $n$-gram smoothing techniques became dormant. This paper re-opens the role classical $n$-gram smoothing techniques may play in the age of neural language models. First, we draw a formal equivalence between label smoothing, a popular regularization technique for neural language models, and add-$\lambda$ smoothing. Second, we derive a generalized framework for converting \emph{any} $n$-gram smoothing technique into a regularizer compatible with neural language models. Our empirical results find that our novel regularizers are comparable to and, indeed, sometimes outperform label smoothing on language modeling and machine translation.
On the Efficacy of Sampling Adapters
Jul 07, 2023Sampling is a common strategy for generating text from probabilistic models, yet standard ancestral sampling often results in text that is incoherent or ungrammatical. To alleviate this issue, various modifications to a model's sampling distribution, such as nucleus or top-k sampling, have been introduced and are now ubiquitously used in language generation systems. We propose a unified framework for understanding these techniques, which we term sampling adapters. Sampling adapters often lead to qualitatively better text, which raises the question: From a formal perspective, how are they changing the (sub)word-level distributions of language generation models? And why do these local changes lead to higher-quality text? We argue that the shift they enforce can be viewed as a trade-off between precision and recall: while the model loses its ability to produce certain strings, its precision rate on desirable text increases. While this trade-off is not reflected in standard metrics of distribution quality (such as perplexity), we find that several precision-emphasizing measures indeed indicate that sampling adapters can lead to probability distributions more aligned with the true distribution. Further, these measures correlate with higher sequence-level quality scores, specifically, Mauve.
A Computed Tomography Vertebral Segmentation Dataset with Anatomical Variations and Multi-Vendor Scanner Data
Mar 10, 2021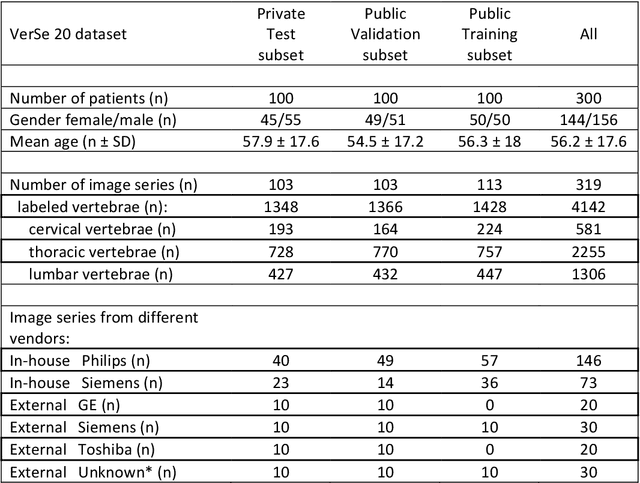
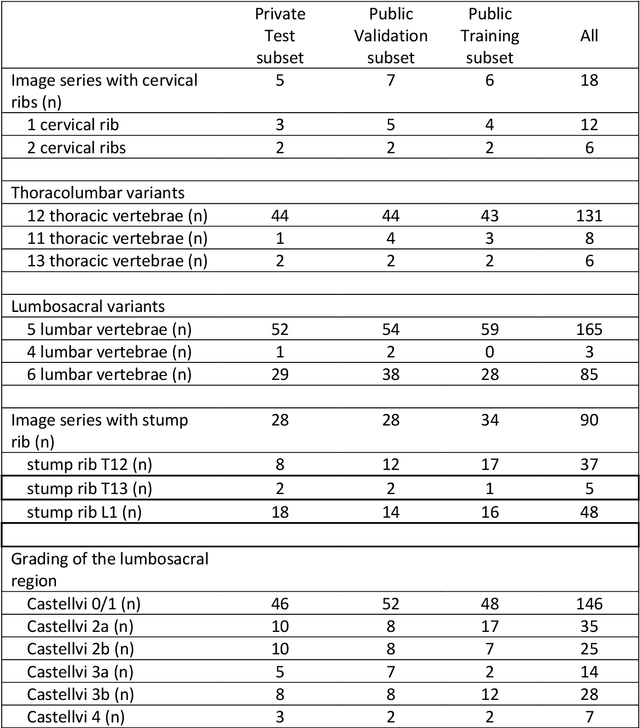
With the advent of deep learning algorithms, fully automated radiological image analysis is within reach. In spine imaging, several atlas- and shape-based as well as deep learning segmentation algorithms have been proposed, allowing for subsequent automated analysis of morphology and pathology. The first Large Scale Vertebrae Segmentation Challenge (VerSe 2019) showed that these perform well on normal anatomy, but fail in variants not frequently present in the training dataset. Building on that experience, we report on the largely increased VerSe 2020 dataset and results from the second iteration of the VerSe challenge (MICCAI 2020, Lima, Peru). VerSe 2020 comprises annotated spine computed tomography (CT) images from 300 subjects with 4142 fully visualized and annotated vertebrae, collected across multiple centres from four different scanner manufacturers, enriched with cases that exhibit anatomical variants such as enumeration abnormalities (n=77) and transitional vertebrae (n=161). Metadata includes vertebral labelling information, voxel-level segmentation masks obtained with a human-machine hybrid algorithm and anatomical ratings, to enable the development and benchmarking of robust and accurate segmentation algorithms.