 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Efficacy of Sampling Adapters
Jul 07, 2023Sampling is a common strategy for generating text from probabilistic models, yet standard ancestral sampling often results in text that is incoherent or ungrammatical. To alleviate this issue, various modifications to a model's sampling distribution, such as nucleus or top-k sampling, have been introduced and are now ubiquitously used in language generation systems. We propose a unified framework for understanding these techniques, which we term sampling adapters. Sampling adapters often lead to qualitatively better text, which raises the question: From a formal perspective, how are they changing the (sub)word-level distributions of language generation models? And why do these local changes lead to higher-quality text? We argue that the shift they enforce can be viewed as a trade-off between precision and recall: while the model loses its ability to produce certain strings, its precision rate on desirable text increases. While this trade-off is not reflected in standard metrics of distribution quality (such as perplexity), we find that several precision-emphasizing measures indeed indicate that sampling adapters can lead to probability distributions more aligned with the true distribution. Further, these measures correlate with higher sequence-level quality scores, specifically, Mauve.
On the Effect of Anticipation on Reading Times
Nov 25, 2022Over the past two decades, numerous studies have demonstrated how less predictable (i.e. higher surprisal) words take more time to read. In general, these previous studies implicitly assumed the reading process to be purely responsive: readers observe a new word and allocate time to read it as required. These results, however, are also compatible with a reading time that is anticipatory: readers could, e.g., allocate time to a future word based on their expectation about it. In this work, we examine the anticipatory nature of reading by looking at how people's predictions about upcoming material influence reading times. Specifically, we test anticipation by looking at the effects of surprisal and contextual entropy on four reading-time datasets: two self-paced and two eye-tracking. In three of four datasets tested, we find that the entropy predicts reading times as well as (or better than) the surprisal. We then hypothesise four cognitive mechanisms through which the contextual entropy could impact RTs -- three of which we design experiments to analyse. Overall, our results support a view of reading that is both anticipatory and responsive.
Exhaustivity and anti-exhaustivity in the RSA framework: Testing the effect of prior beliefs
Feb 14, 2022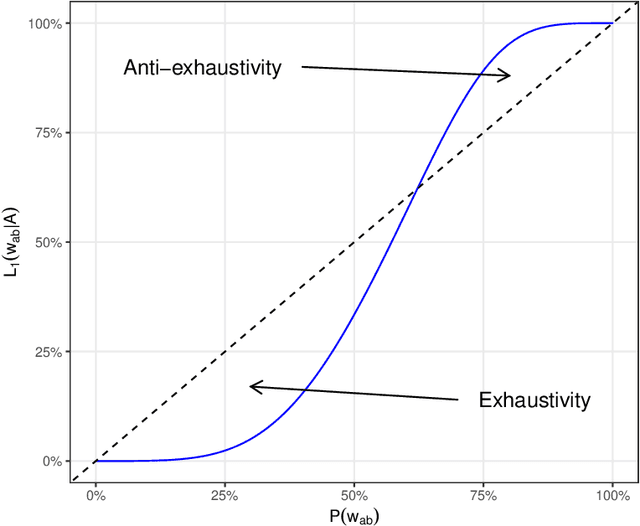
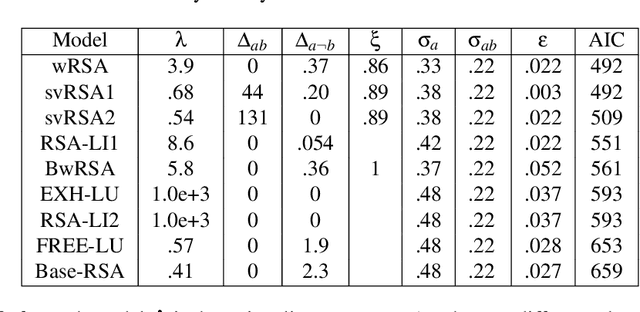

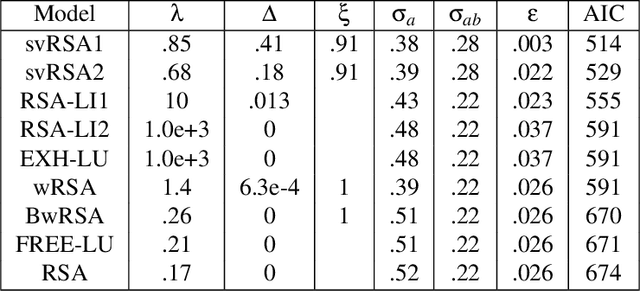
During communication, the interpretation of utterances is sensitive to a listener's probabilistic prior beliefs, something which is captured by one currently influential model of pragmatics, the Rational Speech Act (RSA) framework. In this paper we focus on cases when this sensitivity to priors leads to counterintuitive predictions of the framework. Our domain of interest is exhaustivity effects, whereby a sentence such as "Mary came" is understood to mean that only Mary came. We show that in the baseline RSA model, under certain conditions, anti-exhaustive readings are predicted (e.g., "Mary came" would be used to convey that both Mary and Peter came). The specific question we ask is the following: should exhaustive interpretations be derived as purely pragmatic inferences (as in the classical Gricean view, endorsed in the baseline RSA model), or should they rather be generated by an encapsulated semantic mechanism (as argued in some of the recent formal literature)? To answer this question, we provide a detailed theoretical analysis of different RSA models and evaluate them against data obtained in a new study which tested the effects of prior beliefs on both production and comprehension, improving on previous empirical work. We found no anti-exhaustivity effects, but observed that message choice is sensitive to priors, as predicted by the RSA framework overall. The best models turn out to be those which include an encapsulated exhaustivity mechanism (as other studies concluded on the basis of very different data). We conclude that, on the one hand, in the division of labor between semantics and pragmatics, semantics plays a larger role than is often thought, but, on the other hand, the tradeoff between informativity and cost which characterizes all RSA models does play a central role for genuine pragmatic effects.