 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausally Evaluating the Learnability of Formal Language Tasks
Jun 08, 2026Language models, as multi-task learners, acquire a wide range of abilities during training. A fundamental question is how much task-specific data is needed to learn a given task. Answering this for natural language is difficult: tasks are hard to delineate and can confound one another. To rigorously investigate the relationship between data frequency and learnability, we turn to a controlled setting using formal languages induced from probabilistic finite automata. These serve as a methodological testbed to demonstrate that standard correlational evaluation practices are inherently flawed. To enable causal analysis, we introduce the binning semiring, an algebraic object that lets us control how often a targeted property occurs in a sampled corpus. We formulate the experimental pipeline as a causal graphical model and derive decomposed Kullback-Leibler divergence metrics to measure the learnability of specific sub-tasks. Our experiments show that evaluating learnability without causal intervention leads to incorrect conclusions due to confounders in correlational analysis, and serve as a warning about correlational pitfalls in natural-language settings.
Bearing Syntactic Fruit with Stack-Augmented Neural Networks
Nov 05, 2025Any finite set of training data is consistent with an infinite number of hypothetical algorithms that could have generated it. Studies have shown that when human children learn language, they consistently favor hypotheses based on hierarchical syntactic rules without ever encountering disambiguating examples. A recent line of work has inquired as to whether common neural network architectures share this bias, finding that they do so only under special conditions: when syntactically supervised, when pre-trained on massive corpora, or when trained long past convergence. In this paper, we demonstrate, for the first time, neural network architectures that are able to generalize in human-like fashion without any of the aforementioned requirements: stack-augmented neural networks. We test three base architectures (transformer, simple RNN, LSTM) augmented with two styles of stack: the superposition stack of Joulin & Mikolov (2015) and a nondeterministic generalization of it proposed by DuSell & Chiang (2023). We find that transformers with nondeterministic stacks generalize best out of these architectures on a classical question formation task. We also propose a modification to the stack RNN architecture that improves hierarchical generalization. These results suggest that stack-augmented neural networks may be more accurate models of human language acquisition than standard architectures, serving as useful objects of psycholinguistic study. Our code is publicly available.
Language Models over Canonical Byte-Pair Encodings
Jun 09, 2025Modern language models represent probability distributions over character strings as distributions over (shorter) token strings derived via a deterministic tokenizer, such as byte-pair encoding. While this approach is highly effective at scaling up language models to large corpora, its current incarnations have a concerning property: the model assigns nonzero probability mass to an exponential number of $\it{noncanonical}$ token encodings of each character string -- these are token strings that decode to valid character strings but are impossible under the deterministic tokenizer (i.e., they will never be seen in any training corpus, no matter how large). This misallocation is both erroneous, as noncanonical strings never appear in training data, and wasteful, diverting probability mass away from plausible outputs. These are avoidable mistakes! In this work, we propose methods to enforce canonicality in token-level language models, ensuring that only canonical token strings are assigned positive probability. We present two approaches: (1) canonicality by conditioning, leveraging test-time inference strategies without additional training, and (2) canonicality by construction, a model parameterization that guarantees canonical outputs but requires training. We demonstrate that fixing canonicality mistakes improves the likelihood of held-out data for several models and corpora.
Information Locality as an Inductive Bias for Neural Language Models
Jun 05, 2025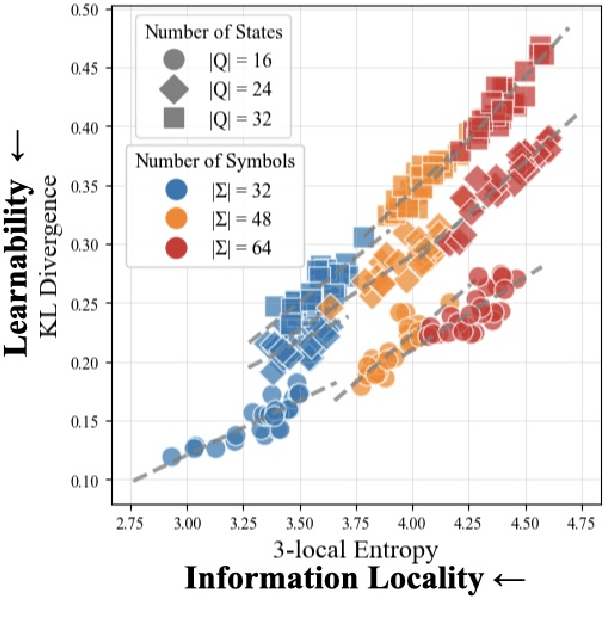
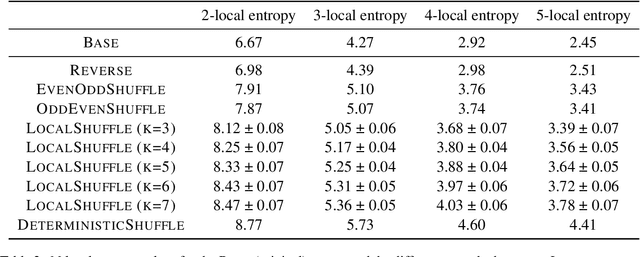
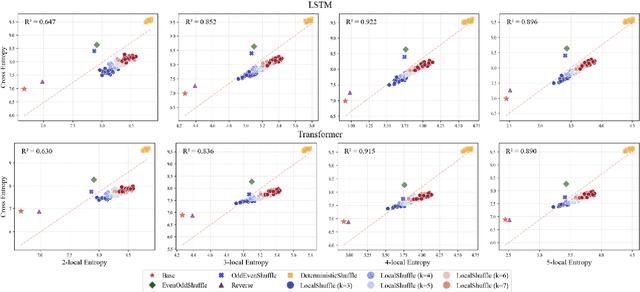
Inductive biases are inherent in every machine learning system, shaping how models generalize from finite data. In the case of neural language models (LMs), debates persist as to whether these biases align with or diverge from human processing constraints. To address this issue, we propose a quantitative framework that allows for controlled investigations into the nature of these biases. Within our framework, we introduce $m$-local entropy$\unicode{x2013}$an information-theoretic measure derived from average lossy-context surprisal$\unicode{x2013}$that captures the local uncertainty of a language by quantifying how effectively the $m-1$ preceding symbols disambiguate the next symbol. In experiments on both perturbed natural language corpora and languages defined by probabilistic finite-state automata (PFSAs), we show that languages with higher $m$-local entropy are more difficult for Transformer and LSTM LMs to learn. These results suggest that neural LMs, much like humans, are highly sensitive to the local statistical structure of a language.
From Language Models over Tokens to Language Models over Characters
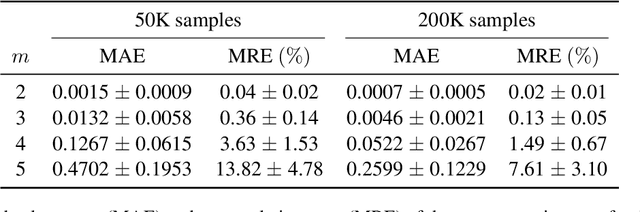
Dec 04, 2024Modern language models are internally -- and mathematically -- distributions over token strings rather than \emph{character} strings, posing numerous challenges for programmers building user applications on top of them. For example, if a prompt is specified as a character string, it must be tokenized before passing it to the token-level language model. Thus, the tokenizer and consequent analyses are very sensitive to the specification of the prompt (e.g., if the prompt ends with a space or not). This paper presents algorithms for converting token-level language models to character-level ones. We present both exact and approximate algorithms. In the empirical portion of the paper, we benchmark the practical runtime and approximation quality. We find that -- even with a small computation budget -- our method is able to accurately approximate the character-level distribution (less than 0.00021 excess bits / character) at reasonably fast speeds (46.3 characters / second) on the Llama 3.1 8B language model.
Training Neural Networks as Recognizers of Formal Languages
Nov 11, 2024Characterizing the computational power of neural network architectures in terms of formal language theory remains a crucial line of research, as it describes lower and upper bounds on the reasoning capabilities of modern AI. However, when empirically testing these bounds, existing work often leaves a discrepancy between experiments and the formal claims they are meant to support. The problem is that formal language theory pertains specifically to recognizers: machines that receive a string as input and classify whether it belongs to a language. On the other hand, it is common to instead use proxy tasks that are similar in only an informal sense, such as language modeling or sequence-to-sequence transduction. We correct this mismatch by training and evaluating neural networks directly as binary classifiers of strings, using a general method that can be applied to a wide variety of languages. As part of this, we extend an algorithm recently proposed by Sn{\ae}bjarnarson et al. (2024) to do length-controlled sampling of strings from regular languages, with much better asymptotic time complexity than previous methods. We provide results on a variety of languages across the Chomsky hierarchy for three neural architectures: a simple RNN, an LSTM, and a causally-masked transformer. We find that the RNN and LSTM often outperform the transformer, and that auxiliary training objectives such as language modeling can help, although no single objective uniformly improves performance across languages and architectures. Our contributions will facilitate theoretically sound empirical testing of language recognition claims in future work. We have released our datasets as a benchmark called FLaRe (Formal Language Recognition), along with our code.
On the Proper Treatment of Tokenization in Psycholinguistics
Oct 03, 2024
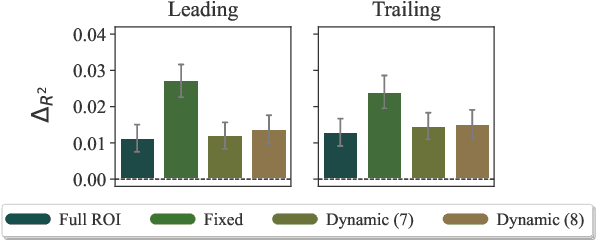

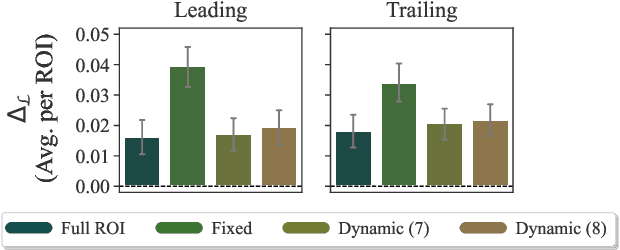
Language models are widely used in computational psycholinguistics to test theories that relate the negative log probability (the surprisal) of a region of interest (a substring of characters) under a language model to its cognitive cost experienced by readers, as operationalized, for example, by gaze duration on the region. However, the application of modern language models to psycholinguistic studies is complicated by the practice of using tokenization as an intermediate step in training a model. Doing so results in a language model over token strings rather than one over character strings. Vexingly, regions of interest are generally misaligned with these token strings. The paper argues that token-level language models should be (approximately) marginalized into character-level language models before they are used in psycholinguistic studies to compute the surprisal of a region of interest; then, the marginalized character-level language model can be used to compute the surprisal of an arbitrary character substring, which we term a focal area, that the experimenter may wish to use as a predictor. Our proposal of marginalizing a token-level model into a character-level one solves this misalignment issue independently of the tokenization scheme. Empirically, we discover various focal areas whose surprisal is a better psychometric predictor than the surprisal of the region of interest itself.
The Foundations of Tokenization: Statistical and Computational Concerns
Jul 16, 2024Tokenization - the practice of converting strings of characters over an alphabet into sequences of tokens over a vocabulary - is a critical yet under-theorized step in the NLP pipeline. Notably, it remains the only major step not fully integrated into widely used end-to-end neural models. This paper aims to address this theoretical gap by laying the foundations of tokenization from a formal perspective. By articulating and extending basic properties about the category of stochastic maps, we propose a unified framework for representing and analyzing tokenizer models. This framework allows us to establish general conditions for the use of tokenizers. In particular, we formally establish the necessary and sufficient conditions for a tokenizer model to preserve the consistency of statistical estimators. Additionally, we discuss statistical and computational concerns crucial for the design and implementation of tokenizer models. The framework and results advanced in this paper represent a step toward a robust theoretical foundation for neural language modeling.
PILA: A Historical-Linguistic Dataset of Proto-Italic and Latin
Apr 25, 2024Computational historical linguistics seeks to systematically understand processes of sound change, including during periods at which little to no formal recording of language is attested. At the same time, few computational resources exist which deeply explore phonological and morphological connections between proto-languages and their descendants. This is particularly true for the family of Italic languages. To assist historical linguists in the study of Italic sound change, we introduce the Proto-Italic to Latin (PILA) dataset, which consists of roughly 3,000 pairs of forms from Proto-Italic and Latin. We provide a detailed description of how our dataset was created and organized. Then, we exhibit PILA's value in two ways. First, we present baseline results for PILA on a pair of traditional computational historical linguistics tasks. Second, we demonstrate PILA's capability for enhancing other historical-linguistic datasets through a dataset compatibility study.
Stack Attention: Improving the Ability of Transformers to Model Hierarchical Patterns
Oct 03, 2023Attention, specifically scaled dot-product attention, has proven effective for natural language, but it does not have a mechanism for handling hierarchical patterns of arbitrary nesting depth, which limits its ability to recognize certain syntactic structures. To address this shortcoming, we propose stack attention: an attention operator that incorporates stacks, inspired by their theoretical connections to context-free languages (CFLs). We show that stack attention is analogous to standard attention, but with a latent model of syntax that requires no syntactic supervision. We propose two variants: one related to deterministic pushdown automata (PDAs) and one based on nondeterministic PDAs, which allows transformers to recognize arbitrary CFLs. We show that transformers with stack attention are very effective at learning CFLs that standard transformers struggle on, achieving strong results on a CFL with theoretically maximal parsing difficulty. We also show that stack attention is more effective at natural language modeling under a constrained parameter budget, and we include results on machine translation.