 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's LIT! Reliability-Optimized LLMs with Inspectable Tools
Nov 18, 2025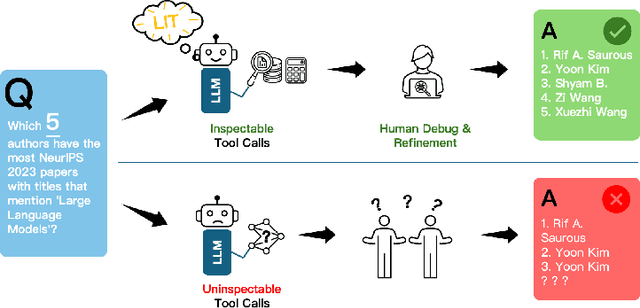
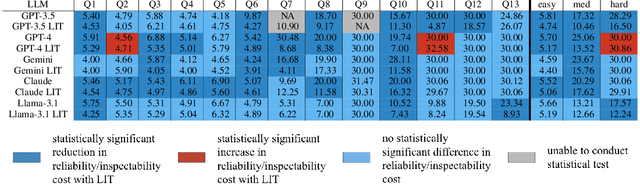
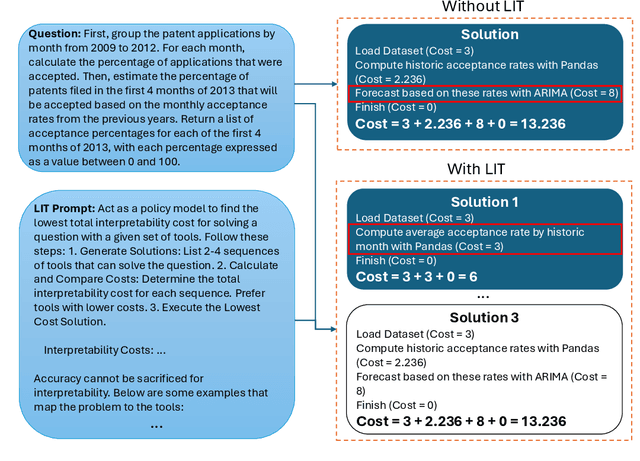
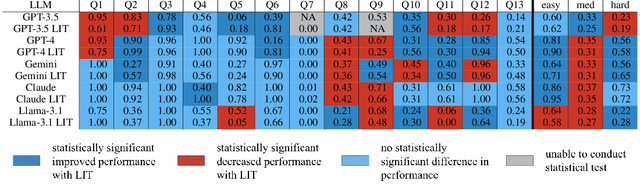
Large language models (LLMs) have exhibited remarkable capabilities across various domains. The ability to call external tools further expands their capability to handle real-world tasks. However, LLMs often follow an opaque reasoning process, which limits their usefulness in high-stakes domains where solutions need to be trustworthy to end users. LLMs can choose solutions that are unreliable and difficult to troubleshoot, even if better options are available. We address this issue by forcing LLMs to use external -- more reliable -- tools to solve problems when possible. We present a framework built on the tool-calling capabilities of existing LLMs to enable them to select the most reliable and easy-to-troubleshoot solution path, which may involve multiple sequential tool calls. We refer to this framework as LIT (LLMs with Inspectable Tools). In order to support LIT, we introduce a new and challenging benchmark dataset of 1,300 questions and a customizable set of reliability cost functions associated with a collection of specialized tools. These cost functions summarize how reliable each tool is and how easy it is to troubleshoot. For instance, a calculator is reliable across domains, whereas a linear prediction model is not reliable if there is distribution shift, but it is easy to troubleshoot. A tool that constructs a random forest is neither reliable nor easy to troubleshoot. These tools interact with the Harvard USPTO Patent Dataset and a new dataset of NeurIPS 2023 papers to solve mathematical, coding, and modeling problems of varying difficulty levels. We demonstrate that LLMs can achieve more reliable and informed problem-solving while maintaining task performance using our framework.
34 Examples of LLM Applications in Materials Science and Chemistry: Towards Automation, Assistants, Agents, and Accelerated Scientific Discovery
May 05, 2025
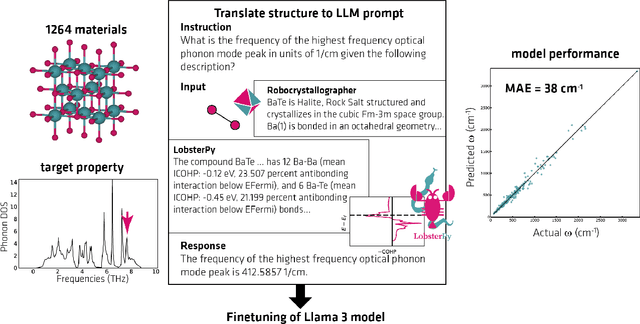
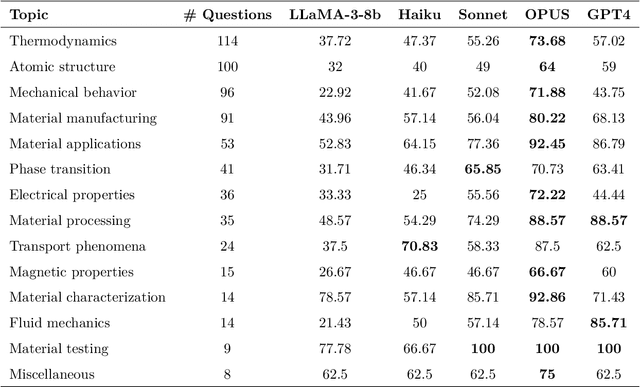
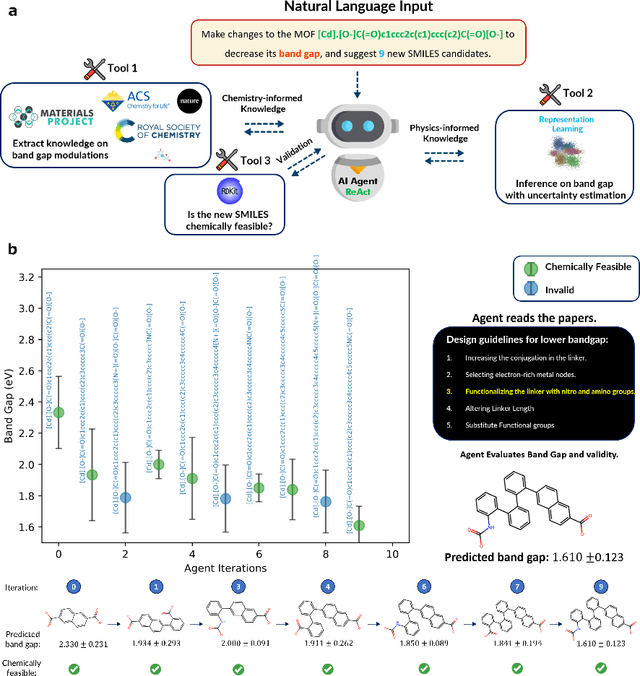
Large Language Models (LLMs) are reshaping many aspects of materials science and chemistry research, enabling advances in molecular property prediction, materials design, scientific automation, knowledge extraction, and more. Recent developments demonstrate that the latest class of models are able to integrate structured and unstructured data, assist in hypothesis generation, and streamline research workflows. To explore the frontier of LLM capabilities across the research lifecycle, we review applications of LLMs through 34 total projects developed during the second annual Large Language Model Hackathon for Applications in Materials Science and Chemistry, a global hybrid event. These projects spanned seven key research areas: (1) molecular and material property prediction, (2) molecular and material design, (3) automation and novel interfaces, (4) scientific communication and education, (5) research data management and automation, (6) hypothesis generation and evaluation, and (7) knowledge extraction and reasoning from the scientific literature. Collectively, these applications illustrate how LLMs serve as versatile predictive models, platforms for rapid prototyping of domain-specific tools, and much more. In particular, improvements in both open source and proprietary LLM performance through the addition of reasoning, additional training data, and new techniques have expanded effectiveness, particularly in low-data environments and interdisciplinary research. As LLMs continue to improve, their integration into scientific workflows presents both new opportunities and new challenges, requiring ongoing exploration, continued refinement, and further research to address reliability, interpretability, and reproducibility.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Training Neural Networks as Recognizers of Formal Languages
Nov 11, 2024Characterizing the computational power of neural network architectures in terms of formal language theory remains a crucial line of research, as it describes lower and upper bounds on the reasoning capabilities of modern AI. However, when empirically testing these bounds, existing work often leaves a discrepancy between experiments and the formal claims they are meant to support. The problem is that formal language theory pertains specifically to recognizers: machines that receive a string as input and classify whether it belongs to a language. On the other hand, it is common to instead use proxy tasks that are similar in only an informal sense, such as language modeling or sequence-to-sequence transduction. We correct this mismatch by training and evaluating neural networks directly as binary classifiers of strings, using a general method that can be applied to a wide variety of languages. As part of this, we extend an algorithm recently proposed by Sn{\ae}bjarnarson et al. (2024) to do length-controlled sampling of strings from regular languages, with much better asymptotic time complexity than previous methods. We provide results on a variety of languages across the Chomsky hierarchy for three neural architectures: a simple RNN, an LSTM, and a causally-masked transformer. We find that the RNN and LSTM often outperform the transformer, and that auxiliary training objectives such as language modeling can help, although no single objective uniformly improves performance across languages and architectures. Our contributions will facilitate theoretically sound empirical testing of language recognition claims in future work. We have released our datasets as a benchmark called FLaRe (Formal Language Recognition), along with our code.
MatViX: Multimodal Information Extraction from Visually Rich Articles
Oct 27, 2024Multimodal information extraction (MIE) is crucial for scientific literature, where valuable data is often spread across text, figures, and tables. In materials science, extracting structured information from research articles can accelerate the discovery of new materials. However, the multimodal nature and complex interconnections of scientific content present challenges for traditional text-based methods. We introduce \textsc{MatViX}, a benchmark consisting of $324$ full-length research articles and $1,688$ complex structured JSON files, carefully curated by domain experts. These JSON files are extracted from text, tables, and figures in full-length documents, providing a comprehensive challenge for MIE. We introduce an evaluation method to assess the accuracy of curve similarity and the alignment of hierarchical structures. Additionally, we benchmark vision-language models (VLMs) in a zero-shot manner, capable of processing long contexts and multimodal inputs, and show that using a specialized model (DePlot) can improve performance in extracting curves. Our results demonstrate significant room for improvement in current models. Our dataset and evaluation code are available\footnote{\url{https://matvix-bench.github.io/}}.
IsoBench: Benchmarking Multimodal Foundation Models on Isomorphic Representations
Apr 02, 2024
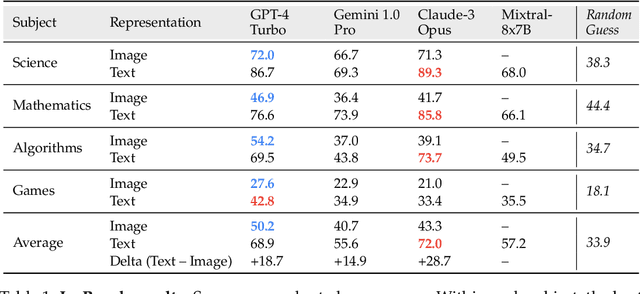
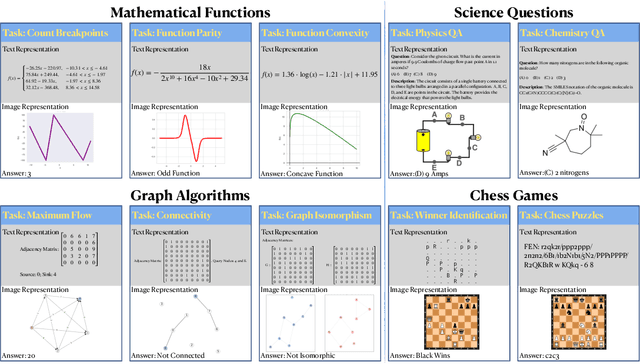
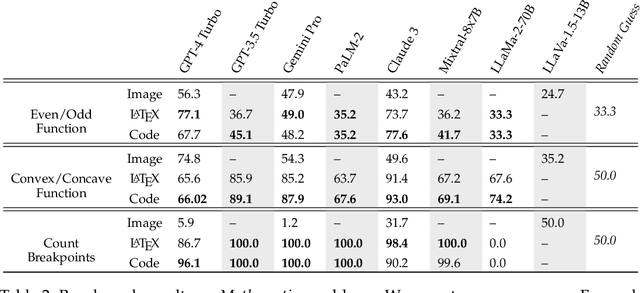
Current foundation models exhibit impressive capabilities when prompted either with text only or with both image and text inputs. But do their capabilities change depending on the input modality? In this work, we propose $\textbf{IsoBench}$, a benchmark dataset containing problems from four major areas: math, science, algorithms, and games. Each example is presented with multiple $\textbf{isomorphic representations}$ of inputs, such as visual, textual, and mathematical presentations. IsoBench provides fine-grained feedback to diagnose performance gaps caused by the form of the representation. Across various foundation models, we observe that on the same problem, models have a consistent preference towards textual representations. Most prominently, when evaluated on all IsoBench problems, Claude-3 Opus performs 28.7 points worse when provided with images instead of text; similarly, GPT-4 Turbo is 18.7 points worse and Gemini Pro is 14.9 points worse. Finally, we present two prompting techniques, $\textit{IsoCombination}$ and $\textit{IsoScratchPad}$, which improve model performance by considering combinations of, and translations between, different input representations.
Extracting Polymer Nanocomposite Samples from Full-Length Documents
Mar 01, 2024This paper investigates the use of large language models (LLMs) for extracting sample lists of polymer nanocomposites (PNCs) from full-length materials science research papers. The challenge lies in the complex nature of PNC samples, which have numerous attributes scattered throughout the text. The complexity of annotating detailed information on PNCs limits the availability of data, making conventional document-level relation extraction techniques impractical due to the challenge in creating comprehensive named entity span annotations. To address this, we introduce a new benchmark and an evaluation technique for this task and explore different prompting strategies in a zero-shot manner. We also incorporate self-consistency to improve the performance. Our findings show that even advanced LLMs struggle to extract all of the samples from an article. Finally, we analyze the errors encountered in this process, categorizing them into three main challenges, and discuss potential strategies for future research to overcome them.
Approximating CKY with Transformers
May 03, 2023



We investigate the ability of transformer models to approximate the CKY algorithm, using them to directly predict a parse and thus avoid the CKY algorithm's cubic dependence on sentence length. We find that on standard constituency parsing benchmarks this approach achieves competitive or better performance than comparable parsers that make use of CKY, while being faster. We also evaluate the viability of this approach for parsing under random PCFGs. Here we find that performance declines as the grammar becomes more ambiguous, suggesting that the transformer is not fully capturing the CKY computation. However, we also find that incorporating additional inductive bias is helpful, and we propose a novel approach that makes use of gradients with respect to chart representations in predicting the parse, in analogy with the CKY algorithm being the subgradient of a partition function variant with respect to the chart.