 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoding Agents are Effective Long-Context Processors
Mar 20, 2026Large Language Models (LLMs) have demonstrated remarkable progress in scaling to access massive contexts. However, the access is via the latent and uninterpretable attention mechanisms, and LLMs fail to effective process long context, exhibiting significant performance degradation as context length increases. In this work, we study whether long-context processing can be externalized from latent attention into explicit, executable interactions, by allowing coding agents to organize text in file systems and manipulate it using its native tools. We evaluate off-the-shelf frontier coding agents as the general interface for tasks that require processing long contexts, including long-context reasoning, retrieval-augmented generation, and open-domain question answering with large-scale corpus contains up to three trillion tokens. Across multiple benchmarks, these agents outperform published state-of-the-art by 17.3% on average. We attribute this efficacy to two key factors: native tool proficiency, which enables agents to leverage executable code and terminal commands rather than passive semantic queries, and file system familiarity, which allows them to navigate massive text corpora as directory structures. These findings suggest that delegating long-context processing to coding agents offers an effective alternative to semantic search or context window scaling, opening new directions for long-context processing in LLMs.
InData: Towards Secure Multi-Step, Tool-Based Data Analysis
Nov 14, 2025Large language model agents for data analysis typically generate and execute code directly on databases. However, when applied to sensitive data, this approach poses significant security risks. To address this issue, we propose a security-motivated alternative: restrict LLMs from direct code generation and data access, and require them to interact with data exclusively through a predefined set of secure, verified tools. Although recent tool-use benchmarks exist, they primarily target tool selection and simple execution rather than the compositional, multi-step reasoning needed for complex data analysis. To reduce this gap, we introduce Indirect Data Engagement (InData), a dataset designed to assess LLMs' multi-step tool-based reasoning ability. InData includes data analysis questions at three difficulty levels--Easy, Medium, and Hard--capturing increasing reasoning complexity. We benchmark 15 open-source LLMs on InData and find that while large models (e.g., gpt-oss-120b) achieve high accuracy on Easy tasks (97.3%), performance drops sharply on Hard tasks (69.6%). These results show that current LLMs still lack robust multi-step tool-based reasoning ability. With InData, we take a step toward enabling the development and evaluation of LLMs with stronger multi-step tool-use capabilities. We will publicly release the dataset and code.
Staircase Streaming for Low-Latency Multi-Agent Inference
Oct 06, 2025



Recent advances in large language models (LLMs) opened up new directions for leveraging the collective expertise of multiple LLMs. These methods, such as Mixture-of-Agents, typically employ additional inference steps to generate intermediate outputs, which are then used to produce the final response. While multi-agent inference can enhance response quality, it can significantly increase the time to first token (TTFT), posing a challenge for latency-sensitive applications and hurting user experience. To address this issue, we propose staircase streaming for low-latency multi-agent inference. Instead of waiting for the complete intermediate outputs from previous steps, we begin generating the final response as soon as we receive partial outputs from these steps. Experimental results demonstrate that staircase streaming reduces TTFT by up to 93% while maintaining response quality.
How Much Backtracking is Enough? Exploring the Interplay of SFT and RL in Enhancing LLM Reasoning
May 30, 2025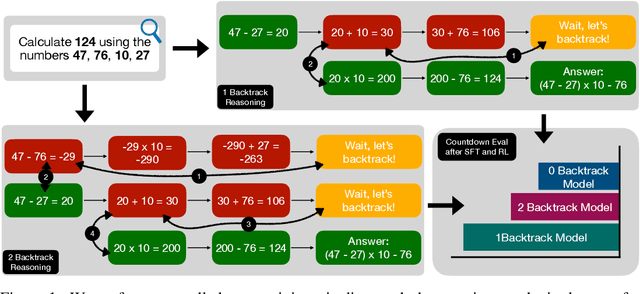


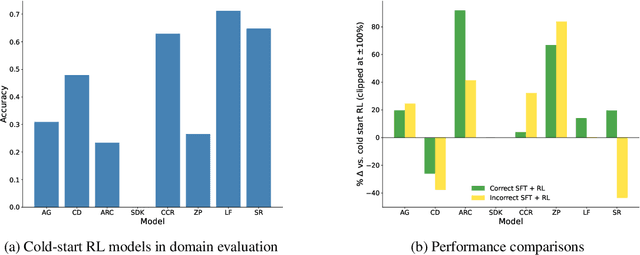
Recent breakthroughs in large language models (LLMs) have effectively improved their reasoning abilities, particularly on mathematical and logical problems that have verifiable answers, through techniques such as supervised finetuning (SFT) and reinforcement learning (RL). Prior research indicates that RL effectively internalizes search strategies, enabling long chain-of-thought (CoT) reasoning, with backtracking emerging naturally as a learned capability. However, the precise benefits of backtracking, specifically, how significantly it contributes to reasoning improvements and the optimal extent of its use, remain poorly understood. In this work, we systematically investigate the dynamics between SFT and RL on eight reasoning tasks: Countdown, Sudoku, Arc 1D, Geometry, Color Cube Rotation, List Functions, Zebra Puzzles, and Self Reference. Our findings highlight that short CoT sequences used in SFT as a warm-up do have moderate contribution to RL training, compared with cold-start RL; however such contribution diminishes when tasks become increasingly difficult. Motivated by this observation, we construct synthetic datasets varying systematically in the number of backtracking steps and conduct controlled experiments to isolate the influence of either the correctness (content) or the structure (i.e., backtrack frequency). We find that (1) longer CoT with backtracks generally induce better and more stable RL training, (2) more challenging problems with larger search space tend to need higher numbers of backtracks during the SFT stage. Additionally, we demonstrate through experiments on distilled data that RL training is largely unaffected by the correctness of long CoT sequences, suggesting that RL prioritizes structural patterns over content correctness. Collectively, our results offer practical insights into designing optimal training strategies to effectively scale reasoning in LLMs.
Interleaved Reasoning for Large Language Models via Reinforcement Learning
May 26, 2025Long chain-of-thought (CoT) significantly enhances large language models' (LLM) reasoning capabilities. However, the extensive reasoning traces lead to inefficiencies and an increased time-to-first-token (TTFT). We propose a novel training paradigm that uses reinforcement learning (RL) to guide reasoning LLMs to interleave thinking and answering for multi-hop questions. We observe that models inherently possess the ability to perform interleaved reasoning, which can be further enhanced through RL. We introduce a simple yet effective rule-based reward to incentivize correct intermediate steps, which guides the policy model toward correct reasoning paths by leveraging intermediate signals generated during interleaved reasoning. Extensive experiments conducted across five diverse datasets and three RL algorithms (PPO, GRPO, and REINFORCE++) demonstrate consistent improvements over traditional think-answer reasoning, without requiring external tools. Specifically, our approach reduces TTFT by over 80% on average and improves up to 19.3% in Pass@1 accuracy. Furthermore, our method, trained solely on question answering and logical reasoning datasets, exhibits strong generalization ability to complex reasoning datasets such as MATH, GPQA, and MMLU. Additionally, we conduct in-depth analysis to reveal several valuable insights into conditional reward modeling.
Breaking the Batch Barrier (B3) of Contrastive Learning via Smart Batch Mining
May 16, 2025Contrastive learning (CL) is a prevalent technique for training embedding models, which pulls semantically similar examples (positives) closer in the representation space while pushing dissimilar ones (negatives) further apart. A key source of negatives are 'in-batch' examples, i.e., positives from other examples in the batch. Effectiveness of such models is hence strongly influenced by the size and quality of training batches. In this work, we propose 'Breaking the Batch Barrier' (B3), a novel batch construction strategy designed to curate high-quality batches for CL. Our approach begins by using a pretrained teacher embedding model to rank all examples in the dataset, from which a sparse similarity graph is constructed. A community detection algorithm is then applied to this graph to identify clusters of examples that serve as strong negatives for one another. The clusters are then used to construct batches that are rich in in-batch negatives. Empirical results on the MMEB multimodal embedding benchmark (36 tasks) demonstrate that our method sets a new state of the art, outperforming previous best methods by +1.3 and +2.9 points at the 7B and 2B model scales, respectively. Notably, models trained with B3 surpass existing state-of-the-art results even with a batch size as small as 64, which is 4-16x smaller than that required by other methods.
Atomic Consistency Preference Optimization for Long-Form Question Answering
May 14, 2025Large Language Models (LLMs) frequently produce factoid hallucinations - plausible yet incorrect answers. A common mitigation strategy is model alignment, which improves factual accuracy by training on curated factual and non-factual pairs. However, this approach often relies on a stronger model (e.g., GPT-4) or an external knowledge base to assess factual correctness, which may not always be accessible. To address this, we propose Atomic Consistency Preference Optimization (ACPO), a self-supervised preference-tuning method that enhances factual accuracy without external supervision. ACPO leverages atomic consistency signals, i.e., the agreement of individual facts across multiple stochastic responses, to identify high- and low-quality data pairs for model alignment. By eliminating the need for costly GPT calls, ACPO provides a scalable and efficient approach to improving factoid question-answering. Despite being self-supervised, empirical results demonstrate that ACPO outperforms FactAlign, a strong supervised alignment baseline, by 1.95 points on the LongFact and BioGen datasets, highlighting its effectiveness in enhancing factual reliability without relying on external models or knowledge bases.
Improving Model Alignment Through Collective Intelligence of Open-Source LLMS
May 05, 2025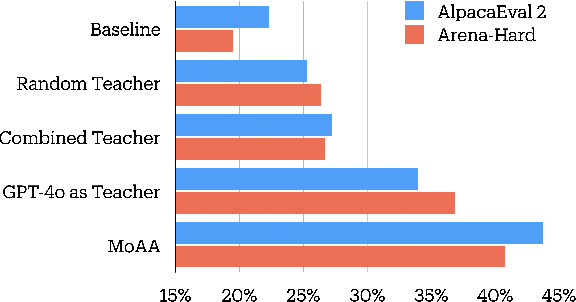
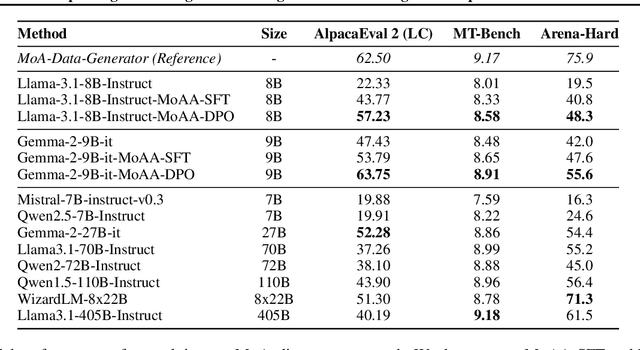
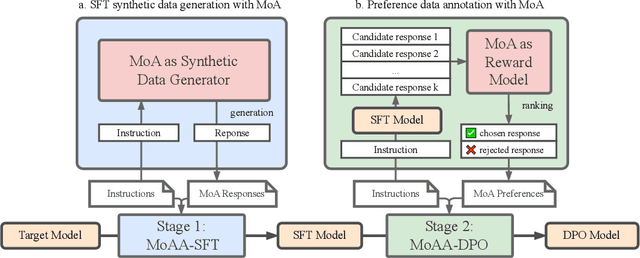
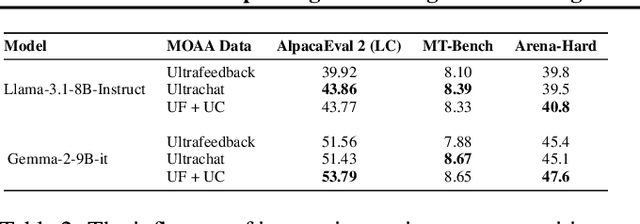
Building helpful and harmless large language models (LLMs) requires effective model alignment approach based on human instructions and feedback, which necessitates high-quality human-labeled data. Constructing such datasets is often expensive and hard to scale, and may face potential limitations on diversity and generalization. To address these challenges, we introduce Mixture of Agents Alignment (MoAA), that leverages the collective strengths of various language models to provide high-quality data for model alignment. By employing MoAA, we enhance both supervised fine-tuning and preference optimization, leading to improved performance compared to using a single model alone to generate alignment data (e.g. using GPT-4o alone). Evaluation results show that our approach can improve win rate of LLaMA-3.1-8B-Instruct from 19.5 to 48.3 on Arena-Hard and from 22.33 to 57.23 on AlpacaEval2, highlighting a promising direction for model alignment through this new scalable and diverse synthetic data recipe. Furthermore, we demonstrate that MoAA enables a self-improvement pipeline, where models finetuned on MoA-generated data surpass their own initial capabilities, providing evidence that our approach can push the frontier of open-source LLMs without reliance on stronger external supervision. Data and code will be released.
Think Deep, Think Fast: Investigating Efficiency of Verifier-free Inference-time-scaling Methods
Apr 18, 2025There is intense interest in investigating how inference time compute (ITC) (e.g. repeated sampling, refinements, etc) can improve large language model (LLM) capabilities. At the same time, recent breakthroughs in reasoning models, such as Deepseek-R1, unlock the opportunity for reinforcement learning to improve LLM reasoning skills. An in-depth understanding of how ITC interacts with reasoning across different models could provide important guidance on how to further advance the LLM frontier. This work conducts a comprehensive analysis of inference-time scaling methods for both reasoning and non-reasoning models on challenging reasoning tasks. Specifically, we focus our research on verifier-free inference time-scaling methods due to its generalizability without needing a reward model. We construct the Pareto frontier of quality and efficiency. We find that non-reasoning models, even with an extremely high inference budget, still fall substantially behind reasoning models. For reasoning models, majority voting proves to be a robust inference strategy, generally competitive or outperforming other more sophisticated ITC methods like best-of-N and sequential revisions, while the additional inference compute offers minimal improvements. We further perform in-depth analyses of the association of key response features (length and linguistic markers) with response quality, with which we can improve the existing ITC methods. We find that correct responses from reasoning models are typically shorter and have fewer hedging and thinking markers (but more discourse markers) than the incorrect responses.
Fuzzy Speculative Decoding for a Tunable Accuracy-Runtime Tradeoff
Feb 28, 2025



Speculative Decoding (SD) enforces strict distributional equivalence to the target model, limiting potential speed ups as distributions of near-equivalence achieve comparable outcomes in many cases. Furthermore, enforcing distributional equivalence means that users are unable to trade deviations from the target model distribution for further inference speed gains. To address these limitations, we introduce Fuzzy Speculative Decoding (FSD) - a decoding algorithm that generalizes SD by accepting candidate tokens purely based on the divergences between the target and draft model distributions. By allowing for controlled divergence from the target model, FSD enables users to flexibly trade generation quality for inference speed. Across several benchmarks, our method is able to achieve significant runtime improvements of over 5 tokens per second faster than SD at only an approximate 2% absolute reduction in benchmark accuracy. In many cases, FSD is even able to match SD benchmark accuracy at over 2 tokens per second faster, demonstrating that distributional equivalence is not necessary to maintain target model performance.