 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Distribution-Wise Control in Representation Space for Language Models
Jun 07, 2025Interventions in language models (LMs) are applied strategically to steer model behavior during the forward pass. Learnable interventions, also known as representation fine-tuning, aim to apply pointwise control within the concept subspace and have proven effective in altering high-level behaviors. In this work, we extend this approach to the distribution level, enabling the model to learn not only pointwise transformations but also the surrounding regions of the concept subspace. We demonstrate that these methods perform effectively in early layers, with larger standard deviations correlating strongly with improved performance. Across eight commonsense reasoning and seven arithmetic reasoning benchmarks, our distribution-wise interventions consistently outperform pointwise interventions in controllability and robustness. These results illustrate that distribution-wise interventions provide a more comprehensive method for steering model behavior and enabling finer-grained control over language models. The code is at: \href{https://github.com/chili-lab/D-Intervention}{https://github.com/chili-lab/D-Intervention}.
Rethinking Diverse Human Preference Learning through Principal Component Analysis
Feb 18, 2025Understanding human preferences is crucial for improving foundation models and building personalized AI systems. However, preferences are inherently diverse and complex, making it difficult for traditional reward models to capture their full range. While fine-grained preference data can help, collecting it is expensive and hard to scale. In this paper, we introduce Decomposed Reward Models (DRMs), a novel approach that extracts diverse human preferences from binary comparisons without requiring fine-grained annotations. Our key insight is to represent human preferences as vectors and analyze them using Principal Component Analysis (PCA). By constructing a dataset of embedding differences between preferred and rejected responses, DRMs identify orthogonal basis vectors that capture distinct aspects of preference. These decomposed rewards can be flexibly combined to align with different user needs, offering an interpretable and scalable alternative to traditional reward models. We demonstrate that DRMs effectively extract meaningful preference dimensions (e.g., helpfulness, safety, humor) and adapt to new users without additional training. Our results highlight DRMs as a powerful framework for personalized and interpretable LLM alignment.
Knowing When to Stop: Dynamic Context Cutoff for Large Language Models
Feb 03, 2025



Large language models (LLMs) process entire input contexts indiscriminately, which is inefficient in cases where the information required to answer a query is localized within the context. We present dynamic context cutoff, a human-inspired method enabling LLMs to self-terminate processing upon acquiring sufficient task-relevant information. Through analysis of model internals, we discover that specific attention heads inherently encode "sufficiency signals" - detectable through lightweight classifiers - that predict when critical information has been processed. This reveals a new efficiency paradigm: models' internal understanding naturally dictates processing needs rather than external compression heuristics. Comprehensive experiments across six QA datasets (up to 40K tokens) with three model families (LLaMA/Qwen/Mistral, 1B0-70B) demonstrate 1.33x average token reduction while improving accuracy by 1.3%. Furthermore, our method demonstrates better performance with the same rate of token reduction compared to other context efficiency methods. Additionally, we observe an emergent scaling phenomenon: while smaller models require require probing for sufficiency detection, larger models exhibit intrinsic self-assessment capabilities through prompting.
Language Models are Symbolic Learners in Arithmetic
Oct 21, 2024Large Language Models (LLMs) are thought to struggle with arithmetic learning due to the inherent differences between language modeling and numerical computation, but concrete evidence has been lacking. This work responds to this claim through a two-side experiment. We first investigate whether LLMs leverage partial products during arithmetic learning. We find that although LLMs can identify some partial products after learning, they fail to leverage them for arithmetic tasks, conversely. We then explore how LLMs approach arithmetic symbolically by breaking tasks into subgroups, hypothesizing that difficulties arise from subgroup complexity and selection. Our results show that when subgroup complexity is fixed, LLMs treat a collection of different arithmetic operations similarly. By analyzing position-level accuracy across different training sizes, we further observe that it follows a U-shaped pattern: LLMs quickly learn the easiest patterns at the first and last positions, while progressively learning the more difficult patterns in the middle positions. This suggests that LLMs select subgroup following an easy-to-hard paradigm during learning. Our work confirms that LLMs are pure symbolic learners in arithmetic tasks and underscores the importance of understanding them deeply through subgroup-level quantification.
Unveiling the Spectrum of Data Contamination in Language Models: A Survey from Detection to Remediation
Jun 20, 2024

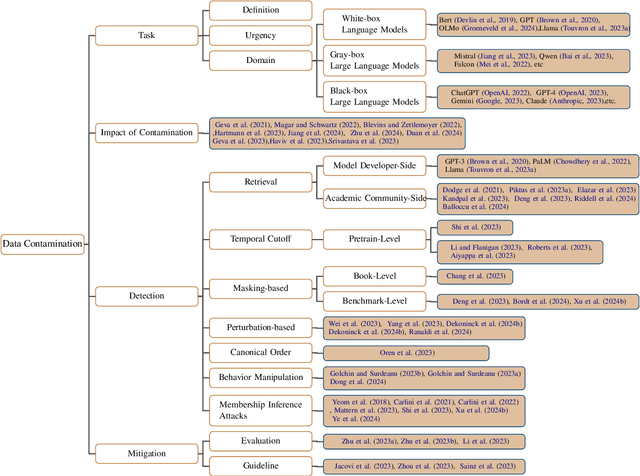
Data contamination has garnered increased attention in the era of large language models (LLMs) due to the reliance on extensive internet-derived training corpora. The issue of training corpus overlap with evaluation benchmarks--referred to as contamination--has been the focus of significant recent research. This body of work aims to identify contamination, understand its impacts, and explore mitigation strategies from diverse perspectives. However, comprehensive studies that provide a clear pathway from foundational concepts to advanced insights are lacking in this nascent field. Therefore, we present a comprehensive survey in the field of data contamination, laying out the key issues, methodologies, and findings to date, and highlighting areas in need of further research and development. In particular, we begin by examining the effects of data contamination across various stages and forms. We then provide a detailed analysis of current contamination detection methods, categorizing them to highlight their focus, assumptions, strengths, and limitations. We also discuss mitigation strategies, offering a clear guide for future research. This survey serves as a succinct overview of the most recent advancements in data contamination research, providing a straightforward guide for the benefit of future research endeavors.
Think Before You Act: A Two-Stage Framework for Mitigating Gender Bias Towards Vision-Language Tasks
May 27, 2024
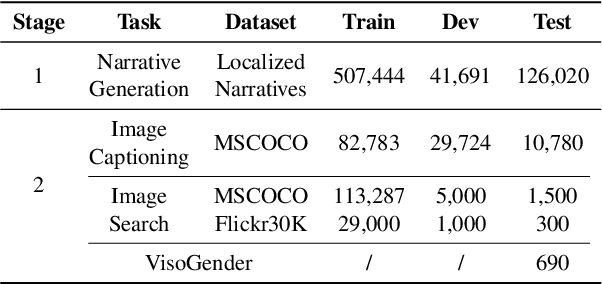
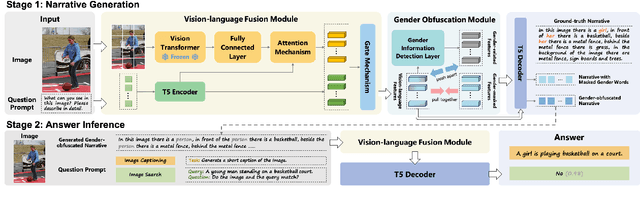
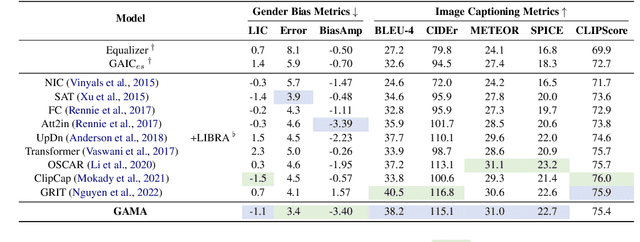
Gender bias in vision-language models (VLMs) can reinforce harmful stereotypes and discrimination. In this paper, we focus on mitigating gender bias towards vision-language tasks. We identify object hallucination as the essence of gender bias in VLMs. Existing VLMs tend to focus on salient or familiar attributes in images but ignore contextualized nuances. Moreover, most VLMs rely on the co-occurrence between specific objects and gender attributes to infer the ignored features, ultimately resulting in gender bias. We propose GAMA, a task-agnostic generation framework to mitigate gender bias. GAMA consists of two stages: narrative generation and answer inference. During narrative generation, GAMA yields all-sided but gender-obfuscated narratives, which prevents premature concentration on localized image features, especially gender attributes. During answer inference, GAMA integrates the image, generated narrative, and a task-specific question prompt to infer answers for different vision-language tasks. This approach allows the model to rethink gender attributes and answers. We conduct extensive experiments on GAMA, demonstrating its debiasing and generalization ability.
MIMIR: A Streamlined Platform for Personalized Agent Tuning in Domain Expertise
Apr 03, 2024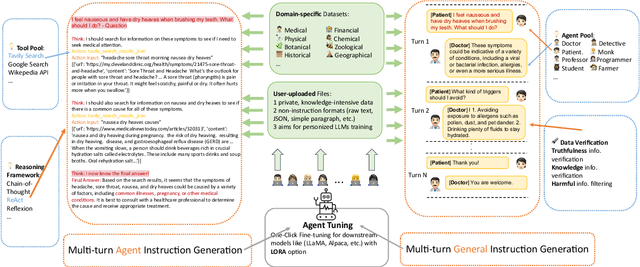
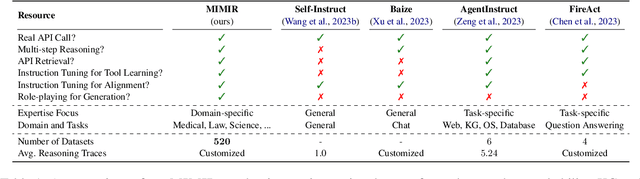

Recently, large language models (LLMs) have evolved into interactive agents, proficient in planning, tool use, and task execution across a wide variety of tasks. However, without specific agent tuning, open-source models like LLaMA currently struggle to match the efficiency of GPT- 4, particularly given the scarcity of agent-tuning datasets for fine-tuning. In response, we introduce \textsc{Mimir}: a streamlined platform offering a customizable pipeline that enables users to leverage both private knowledge and publicly available, legally compliant datasets at scale for \textbf{personalized agent tuning}. Additionally, \textsc{Mimir} supports the generation of general instruction-tuning datasets from the same input. This dual capability ensures that language agents developed through the platform possess both specific agent abilities and general competencies. \textsc{Mimir} integrates these features into a cohesive end-to-end platform, facilitating everything from the uploading of personalized files to one-click agent fine-tuning.
ProgGen: Generating Named Entity Recognition Datasets Step-by-step with Self-Reflexive Large Language Models
Mar 17, 2024Although Large Language Models (LLMs) exhibit remarkable adaptability across domains, these models often fall short in structured knowledge extraction tasks such as named entity recognition (NER). This paper explores an innovative, cost-efficient strategy to harness LLMs with modest NER capabilities for producing superior NER datasets. Our approach diverges from the basic class-conditional prompts by instructing LLMs to self-reflect on the specific domain, thereby generating domain-relevant attributes (such as category and emotions for movie reviews), which are utilized for creating attribute-rich training data. Furthermore, we preemptively generate entity terms and then develop NER context data around these entities, effectively bypassing the LLMs' challenges with complex structures. Our experiments across both general and niche domains reveal significant performance enhancements over conventional data generation methods while being more cost-effective than existing alternatives.
Investigating Data Contamination in Modern Benchmarks for Large Language Models
Nov 16, 2023Recent observations have underscored a disparity between the inflated benchmark scores and the actual performance of LLMs, raising concerns about potential contamination of evaluation benchmarks. This issue is especially critical for closed-source models and certain open-source models where training data transparency is lacking. In this paper we study data contamination by proposing two methods tailored for both open-source and proprietary LLMs. We first introduce a retrieval-based system to explore potential overlaps between evaluation benchmarks and pretraining corpora. We further present a novel investigation protocol named \textbf{T}estset \textbf{S}lot Guessing (\textit{TS-Guessing}), applicable to both open and proprietary models. This approach entails masking a wrong answer in a multiple-choice question and prompting the model to fill in the gap. Additionally, it involves obscuring an unlikely word in an evaluation example and asking the model to produce it. We find that certain commercial LLMs could surprisingly guess the missing option in various test sets. Specifically, in the TruthfulQA benchmark, we find that LLMs exhibit notable performance improvement when provided with additional metadata in the benchmark. Further, in the MMLU benchmark, ChatGPT and GPT-4 demonstrated an exact match rate of 52\% and 57\%, respectively, in guessing the missing options in benchmark test data. We hope these results underscore the need for more robust evaluation methodologies and benchmarks in the field.