 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Semi-Supervised Learning
Dec 17, 2025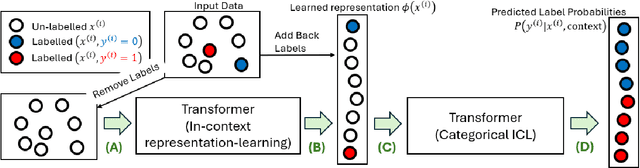

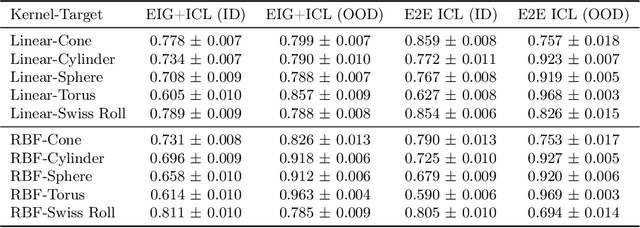
There has been significant recent interest in understanding the capacity of Transformers for in-context learning (ICL), yet most theory focuses on supervised settings with explicitly labeled pairs. In practice, Transformers often perform well even when labels are sparse or absent, suggesting crucial structure within unlabeled contextual demonstrations. We introduce and study in-context semi-supervised learning (IC-SSL), where a small set of labeled examples is accompanied by many unlabeled points, and show that Transformers can leverage the unlabeled context to learn a robust, context-dependent representation. This representation enables accurate predictions and markedly improves performance in low-label regimes, offering foundational insights into how Transformers exploit unlabeled context for representation learning within the ICL framework.
LITERA: An LLM Based Approach to Latin-to-English Translation
Apr 14, 2025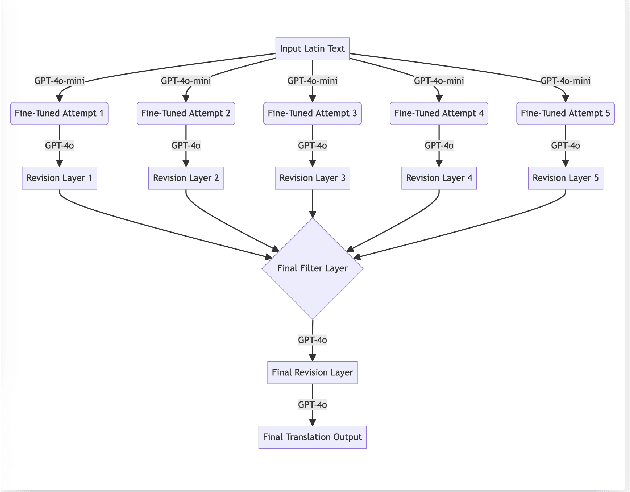

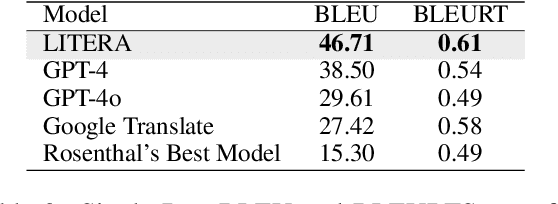

This paper introduces an LLM-based Latin-to-English translation platform designed to address the challenges of translating Latin texts. We named the model LITERA, which stands for Latin Interpretation and Translations into English for Research Assistance. Through a multi-layered translation process utilizing a fine-tuned version of GPT-4o-mini and GPT-4o, LITERA offers an unprecedented level of accuracy, showcased by greatly improved BLEU scores, particularly in classical Latin, along with improved BLEURT scores. The development of LITERA involved close collaboration with Duke University's Classical Studies Department, which was instrumental in creating a small, high-quality parallel Latin-English dataset. This paper details the architecture, fine-tuning methodology, and prompting strategies used in LITERA, emphasizing its ability to produce literal translations.
Knowing When to Stop: Dynamic Context Cutoff for Large Language Models
Feb 03, 2025



Large language models (LLMs) process entire input contexts indiscriminately, which is inefficient in cases where the information required to answer a query is localized within the context. We present dynamic context cutoff, a human-inspired method enabling LLMs to self-terminate processing upon acquiring sufficient task-relevant information. Through analysis of model internals, we discover that specific attention heads inherently encode "sufficiency signals" - detectable through lightweight classifiers - that predict when critical information has been processed. This reveals a new efficiency paradigm: models' internal understanding naturally dictates processing needs rather than external compression heuristics. Comprehensive experiments across six QA datasets (up to 40K tokens) with three model families (LLaMA/Qwen/Mistral, 1B0-70B) demonstrate 1.33x average token reduction while improving accuracy by 1.3%. Furthermore, our method demonstrates better performance with the same rate of token reduction compared to other context efficiency methods. Additionally, we observe an emergent scaling phenomenon: while smaller models require require probing for sufficiency detection, larger models exhibit intrinsic self-assessment capabilities through prompting.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.