 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Guided Action Diffusion via Sub-Frequency Manifold Traversal
May 27, 2026Learning visuomotor policies via behavior cloning typically involves mimicking expert demonstrations collected by human operators. However, natural human demonstrations inherently contain high-frequency noise, such as intermittent jerks, pauses, and action jitter. Training policies to directly imitate these raw trajectories inevitably causes the model to inherit these suboptimal behaviors. This pathology is particularly pronounced in diffusion-based policies, where iterative denoising steps can inadvertently amplify high-frequency artifacts at the expense of meaningful fine-grained details. To address these limitations, we present a novel frequency-based algorithm that enables implicit spectral maneuvering and smooth action generation. Our method, Frequency Guidance Operator (FGO), steers the generation process of diffusion polices by progressively driving the noisy samples through intermediate sub-frequency manifolds with expanding spectral bands. Validated on 15 robotic manipulation tasks from 5 benchmarks, FGO achieves superior performance in enhancing action smoothness and temporal consistency while preserving the details necessary for successful task execution. Project website: https://henrywjl.github.io/frequency-guidance-operator/
Automated Benchmark Auditing for AI Agents and Large Language Models
May 26, 2026Modern AI benchmarks operate at a complexity that outpaces traditional verification methods. Tasks authored by domain experts often contain implicit assumptions, incomplete environment specifications, and brittle evaluation logic that human annotation cannot reliably catch. We introduce Auto Benchmark Audit (ABA), an agentic framework that systematically audits individual benchmark tasks, uncovering issues such as hidden environment dependencies, specification gaps, and limited grading logic. We run ABA on a collection of frontier LLM benchmarks and previous NeurIPS publications, totaling 168 benchmarks across nine domains. Across this corpus, ABA identifies critical issues including ambiguous task design, execution environment conflicts, and incorrect ground truths in over 25.7% of the evaluated tasks. The precision of these automated audits is validated by expert review and independent third-party reports such as upstream PRs. Crucially, we demonstrate that these problematic tasks severely distorts capability assessments for agents and LLMs: filtering out these tasks with issues shifts model rankings and increases average performance on SWE-bench Verified and Terminal-Bench 2 by 9.9% and 9.6%, respectively. We release the agentic tool and all task annotations to support the future development of frontier benchmarks.
FSP-Diff: Full-Spectrum Prior-Enhanced DualDomain Latent Diffusion for Ultra-Low-Dose Spectral CT Reconstruction
Feb 08, 2026Spectral computed tomography (CT) with photon-counting detectors holds immense potential for material discrimination and tissue characterization. However, under ultra-low-dose conditions, the sharply degraded signal-to-noise ratio (SNR) in energy-specific projections poses a significant challenge, leading to severe artifacts and loss of structural details in reconstructed images. To address this, we propose FSP-Diff, a full-spectrum prior-enhanced dual-domain latent diffusion framework for ultra-low-dose spectral CT reconstruction. Our framework integrates three core strategies: 1) Complementary Feature Construction: We integrate direct image reconstructions with projection-domain denoised results. While the former preserves latent textural nuances amidst heavy noise, the latter provides a stable structural scaffold to balance detail fidelity and noise suppression. 2) Full-Spectrum Prior Integration: By fusing multi-energy projections into a high-SNR full-spectrum image, we establish a unified structural reference that guides the reconstruction across all energy bins. 3) Efficient Latent Diffusion Synthesis: To alleviate the high computational burden of high-dimensional spectral data, multi-path features are embedded into a compact latent space. This allows the diffusion process to facilitate interactive feature fusion in a lower-dimensional manifold, achieving accelerated reconstruction while maintaining fine-grained detail restoration. Extensive experiments on simulated and real-world datasets demonstrate that FSP-Diff significantly outperforms state-of-the-art methods in both image quality and computational efficiency, underscoring its potential for clinically viable ultra-low-dose spectral CT imaging.
Continuity-driven Synergistic Diffusion with Neural Priors for Ultra-Sparse-View CBCT Reconstruction
Feb 08, 2026The clinical application of cone-beam computed tomography (CBCT) is constrained by the inherent trade-off between radiation exposure and image quality. Ultra-sparse angular sampling, employed to reduce dose, introduces severe undersampling artifacts and inter-slice inconsistencies, compromising diagnostic reliability. Existing reconstruction methods often struggle to balance angular continuity with spatial detail fidelity. To address these challenges, we propose a Continuity-driven Synergistic Diffusion with Neural priors (CSDN) for ultra-sparse-view CBCT reconstruction. Neural priors are introduced as a structural foundation to encode a continuous threedimensional attenuation representation, enabling the synthesis of physically consistent dense projections from ultra-sparse measurements. Building upon this neural-prior-based initialization, a synergistic diffusion strategy is developed, consisting of two collaborative refinement paths: a Sinogram Refinement Diffusion (Sino-RD) process that restores angular continuity and a Digital Radiography Refinement Diffusion (DR-RD) process that enforces inter-slice consistency from the projection image perspective. The outputs of the two diffusion paths are adaptively fused by the Dual-Projection Reconstruction Fusion (DPRF) module to achieve coherent volumetric reconstruction. Extensive experiments demonstrate that the proposed CSDN effectively suppresses artifacts and recovers fine textures under ultra-sparse-view conditions, outperforming existing state-of-the-art techniques.
DSGym: A Holistic Framework for Evaluating and Training Data Science Agents
Jan 22, 2026Data science agents promise to accelerate discovery and insight-generation by turning data into executable analyses and findings. Yet existing data science benchmarks fall short due to fragmented evaluation interfaces that make cross-benchmark comparison difficult, narrow task coverage and a lack of rigorous data grounding. In particular, we show that a substantial portion of tasks in current benchmarks can be solved without using the actual data. To address these limitations, we introduce DSGym, a standardized framework for evaluating and training data science agents in self-contained execution environments. Unlike static benchmarks, DSGym provides a modular architecture that makes it easy to add tasks, agent scaffolds, and tools, positioning it as a live, extensible testbed. We curate DSGym-Tasks, a holistic task suite that standardizes and refines existing benchmarks via quality and shortcut solvability filtering. We further expand coverage with (1) DSBio: expert-derived bioinformatics tasks grounded in literature and (2) DSPredict: challenging prediction tasks spanning domains such as computer vision, molecular prediction, and single-cell perturbation. Beyond evaluation, DSGym enables agent training via execution-verified data synthesis pipeline. As a case study, we build a 2,000-example training set and trained a 4B model in DSGym that outperforms GPT-4o on standardized analysis benchmarks. Overall, DSGym enables rigorous end-to-end measurement of whether agents can plan, implement, and validate data analyses in realistic scientific context.
Iterative Diffusion-Refined Neural Attenuation Fields for Multi-Source Stationary CT Reconstruction: NAF Meets Diffusion Model
Nov 18, 2025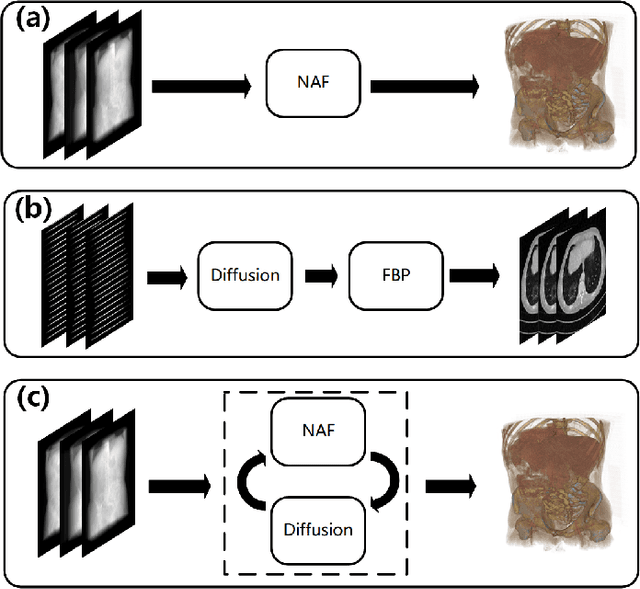
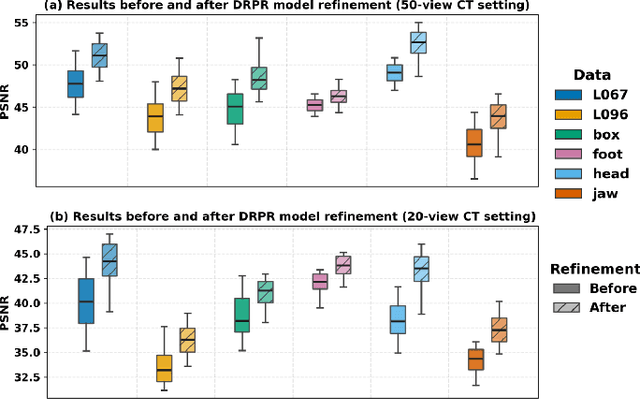
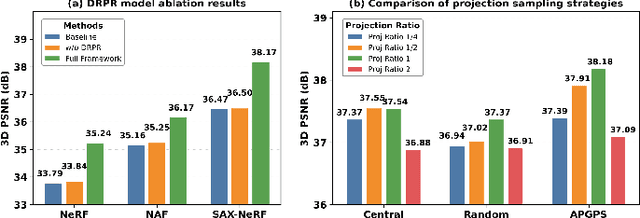
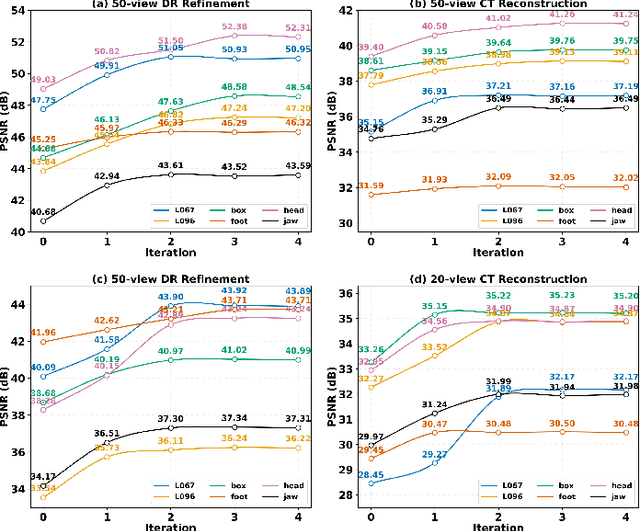
Multi-source stationary computed tomography (CT) has recently attracted attention for its ability to achieve rapid image reconstruction, making it suitable for time-sensitive clinical and industrial applications. However, practical systems are often constrained by ultra-sparse-view sampling, which significantly degrades reconstruction quality. Traditional methods struggle under ultra-sparse-view settings, where interpolation becomes inaccurate and the resulting reconstructions are unsatisfactory. To address this challenge, this study proposes Diffusion-Refined Neural Attenuation Fields (Diff-NAF), an iterative framework tailored for multi-source stationary CT under ultra-sparse-view conditions. Diff-NAF combines a Neural Attenuation Field representation with a dual-branch conditional diffusion model. The process begins by training an initial NAF using ultra-sparse-view projections. New projections are then generated through an Angle-Prior Guided Projection Synthesis strategy that exploits inter view priors, and are subsequently refined by a Diffusion-driven Reuse Projection Refinement Module. The refined projections are incorporated as pseudo-labels into the training set for the next iteration. Through iterative refinement, Diff-NAF progressively enhances projection completeness and reconstruction fidelity under ultra-sparse-view conditions, ultimately yielding high-quality CT reconstructions. Experimental results on multiple simulated 3D CT volumes and real projection data demonstrate that Diff-NAF achieves the best performance under ultra-sparse-view conditions.
Staircase Streaming for Low-Latency Multi-Agent Inference
Oct 06, 2025



Recent advances in large language models (LLMs) opened up new directions for leveraging the collective expertise of multiple LLMs. These methods, such as Mixture-of-Agents, typically employ additional inference steps to generate intermediate outputs, which are then used to produce the final response. While multi-agent inference can enhance response quality, it can significantly increase the time to first token (TTFT), posing a challenge for latency-sensitive applications and hurting user experience. To address this issue, we propose staircase streaming for low-latency multi-agent inference. Instead of waiting for the complete intermediate outputs from previous steps, we begin generating the final response as soon as we receive partial outputs from these steps. Experimental results demonstrate that staircase streaming reduces TTFT by up to 93% while maintaining response quality.
How Much Backtracking is Enough? Exploring the Interplay of SFT and RL in Enhancing LLM Reasoning
May 30, 2025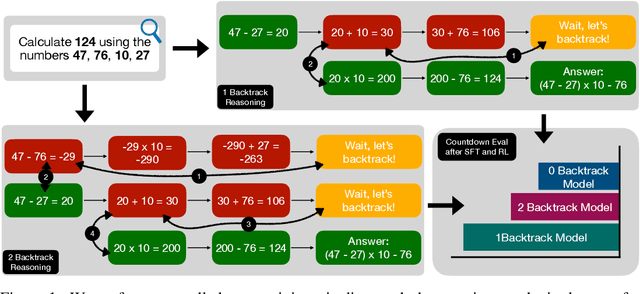


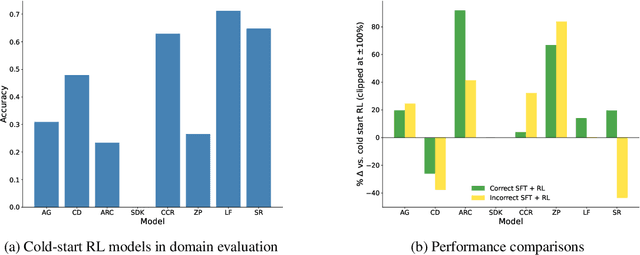
Recent breakthroughs in large language models (LLMs) have effectively improved their reasoning abilities, particularly on mathematical and logical problems that have verifiable answers, through techniques such as supervised finetuning (SFT) and reinforcement learning (RL). Prior research indicates that RL effectively internalizes search strategies, enabling long chain-of-thought (CoT) reasoning, with backtracking emerging naturally as a learned capability. However, the precise benefits of backtracking, specifically, how significantly it contributes to reasoning improvements and the optimal extent of its use, remain poorly understood. In this work, we systematically investigate the dynamics between SFT and RL on eight reasoning tasks: Countdown, Sudoku, Arc 1D, Geometry, Color Cube Rotation, List Functions, Zebra Puzzles, and Self Reference. Our findings highlight that short CoT sequences used in SFT as a warm-up do have moderate contribution to RL training, compared with cold-start RL; however such contribution diminishes when tasks become increasingly difficult. Motivated by this observation, we construct synthetic datasets varying systematically in the number of backtracking steps and conduct controlled experiments to isolate the influence of either the correctness (content) or the structure (i.e., backtrack frequency). We find that (1) longer CoT with backtracks generally induce better and more stable RL training, (2) more challenging problems with larger search space tend to need higher numbers of backtracks during the SFT stage. Additionally, we demonstrate through experiments on distilled data that RL training is largely unaffected by the correctness of long CoT sequences, suggesting that RL prioritizes structural patterns over content correctness. Collectively, our results offer practical insights into designing optimal training strategies to effectively scale reasoning in LLMs.
Grounding Bodily Awareness in Visual Representations for Efficient Policy Learning
May 24, 2025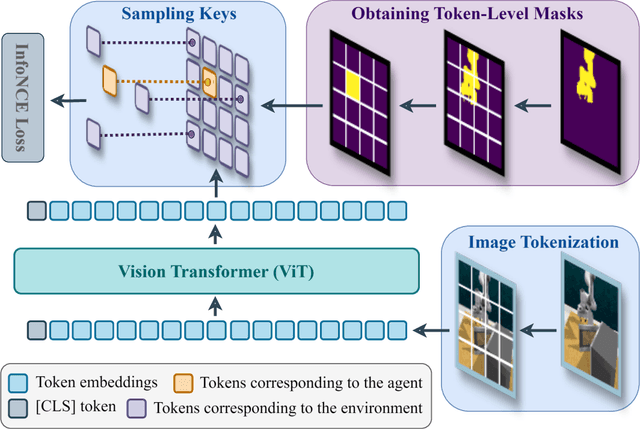
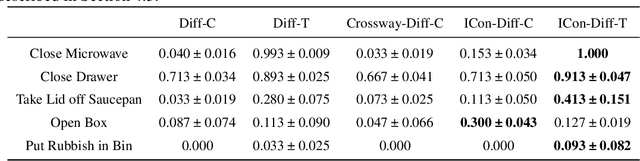
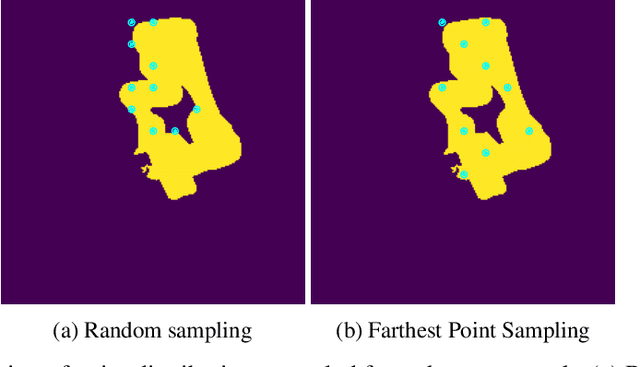
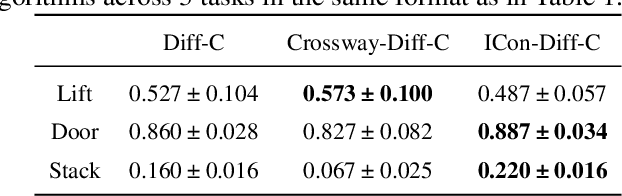
Learning effective visual representations for robotic manipulation remains a fundamental challenge due to the complex body dynamics involved in action execution. In this paper, we study how visual representations that carry body-relevant cues can enable efficient policy learning for downstream robotic manipulation tasks. We present $\textbf{I}$nter-token $\textbf{Con}$trast ($\textbf{ICon}$), a contrastive learning method applied to the token-level representations of Vision Transformers (ViTs). ICon enforces a separation in the feature space between agent-specific and environment-specific tokens, resulting in agent-centric visual representations that embed body-specific inductive biases. This framework can be seamlessly integrated into end-to-end policy learning by incorporating the contrastive loss as an auxiliary objective. Our experiments show that ICon not only improves policy performance across various manipulation tasks but also facilitates policy transfer across different robots. The project website: https://github.com/HenryWJL/icon
Atomic Consistency Preference Optimization for Long-Form Question Answering
May 14, 2025Large Language Models (LLMs) frequently produce factoid hallucinations - plausible yet incorrect answers. A common mitigation strategy is model alignment, which improves factual accuracy by training on curated factual and non-factual pairs. However, this approach often relies on a stronger model (e.g., GPT-4) or an external knowledge base to assess factual correctness, which may not always be accessible. To address this, we propose Atomic Consistency Preference Optimization (ACPO), a self-supervised preference-tuning method that enhances factual accuracy without external supervision. ACPO leverages atomic consistency signals, i.e., the agreement of individual facts across multiple stochastic responses, to identify high- and low-quality data pairs for model alignment. By eliminating the need for costly GPT calls, ACPO provides a scalable and efficient approach to improving factoid question-answering. Despite being self-supervised, empirical results demonstrate that ACPO outperforms FactAlign, a strong supervised alignment baseline, by 1.95 points on the LongFact and BioGen datasets, highlighting its effectiveness in enhancing factual reliability without relying on external models or knowledge bases.