 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSGym: A Holistic Framework for Evaluating and Training Data Science Agents
Jan 22, 2026Data science agents promise to accelerate discovery and insight-generation by turning data into executable analyses and findings. Yet existing data science benchmarks fall short due to fragmented evaluation interfaces that make cross-benchmark comparison difficult, narrow task coverage and a lack of rigorous data grounding. In particular, we show that a substantial portion of tasks in current benchmarks can be solved without using the actual data. To address these limitations, we introduce DSGym, a standardized framework for evaluating and training data science agents in self-contained execution environments. Unlike static benchmarks, DSGym provides a modular architecture that makes it easy to add tasks, agent scaffolds, and tools, positioning it as a live, extensible testbed. We curate DSGym-Tasks, a holistic task suite that standardizes and refines existing benchmarks via quality and shortcut solvability filtering. We further expand coverage with (1) DSBio: expert-derived bioinformatics tasks grounded in literature and (2) DSPredict: challenging prediction tasks spanning domains such as computer vision, molecular prediction, and single-cell perturbation. Beyond evaluation, DSGym enables agent training via execution-verified data synthesis pipeline. As a case study, we build a 2,000-example training set and trained a 4B model in DSGym that outperforms GPT-4o on standardized analysis benchmarks. Overall, DSGym enables rigorous end-to-end measurement of whether agents can plan, implement, and validate data analyses in realistic scientific context.
Intelligence per Watt: Measuring Intelligence Efficiency of Local AI
Nov 14, 2025Large language model (LLM) queries are predominantly processed by frontier models in centralized cloud infrastructure. Rapidly growing demand strains this paradigm, and cloud providers struggle to scale infrastructure at pace. Two advances enable us to rethink this paradigm: small LMs (<=20B active parameters) now achieve competitive performance to frontier models on many tasks, and local accelerators (e.g., Apple M4 Max) run these models at interactive latencies. This raises the question: can local inference viably redistribute demand from centralized infrastructure? Answering this requires measuring whether local LMs can accurately answer real-world queries and whether they can do so efficiently enough to be practical on power-constrained devices (i.e., laptops). We propose intelligence per watt (IPW), task accuracy divided by unit of power, as a metric for assessing capability and efficiency of local inference across model-accelerator pairs. We conduct a large-scale empirical study across 20+ state-of-the-art local LMs, 8 accelerators, and a representative subset of LLM traffic: 1M real-world single-turn chat and reasoning queries. For each query, we measure accuracy, energy, latency, and power. Our analysis reveals $3$ findings. First, local LMs can accurately answer 88.7% of single-turn chat and reasoning queries with accuracy varying by domain. Second, from 2023-2025, IPW improved 5.3x and local query coverage rose from 23.2% to 71.3%. Third, local accelerators achieve at least 1.4x lower IPW than cloud accelerators running identical models, revealing significant headroom for optimization. These findings demonstrate that local inference can meaningfully redistribute demand from centralized infrastructure, with IPW serving as the critical metric for tracking this transition. We release our IPW profiling harness for systematic intelligence-per-watt benchmarking.
Improving Model Alignment Through Collective Intelligence of Open-Source LLMS
May 05, 2025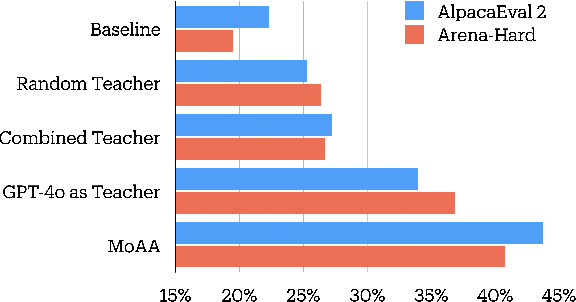
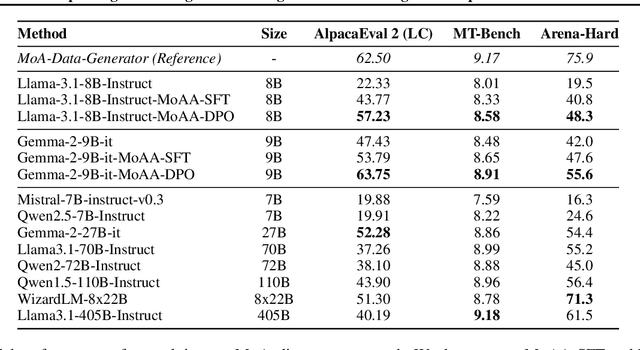
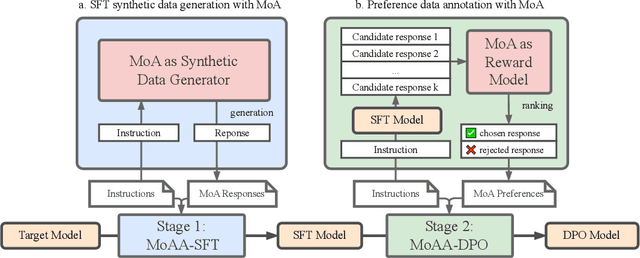
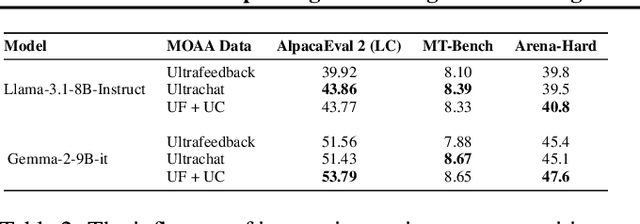
Building helpful and harmless large language models (LLMs) requires effective model alignment approach based on human instructions and feedback, which necessitates high-quality human-labeled data. Constructing such datasets is often expensive and hard to scale, and may face potential limitations on diversity and generalization. To address these challenges, we introduce Mixture of Agents Alignment (MoAA), that leverages the collective strengths of various language models to provide high-quality data for model alignment. By employing MoAA, we enhance both supervised fine-tuning and preference optimization, leading to improved performance compared to using a single model alone to generate alignment data (e.g. using GPT-4o alone). Evaluation results show that our approach can improve win rate of LLaMA-3.1-8B-Instruct from 19.5 to 48.3 on Arena-Hard and from 22.33 to 57.23 on AlpacaEval2, highlighting a promising direction for model alignment through this new scalable and diverse synthetic data recipe. Furthermore, we demonstrate that MoAA enables a self-improvement pipeline, where models finetuned on MoA-generated data surpass their own initial capabilities, providing evidence that our approach can push the frontier of open-source LLMs without reliance on stronger external supervision. Data and code will be released.
34 Examples of LLM Applications in Materials Science and Chemistry: Towards Automation, Assistants, Agents, and Accelerated Scientific Discovery
May 05, 2025
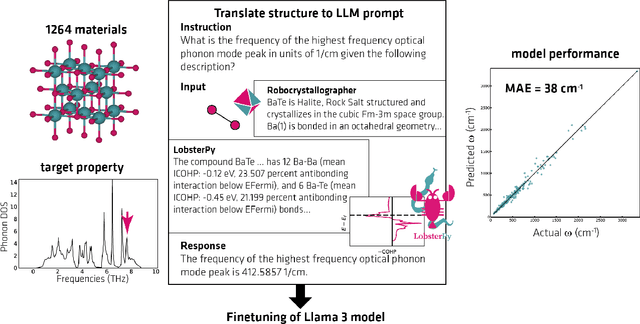
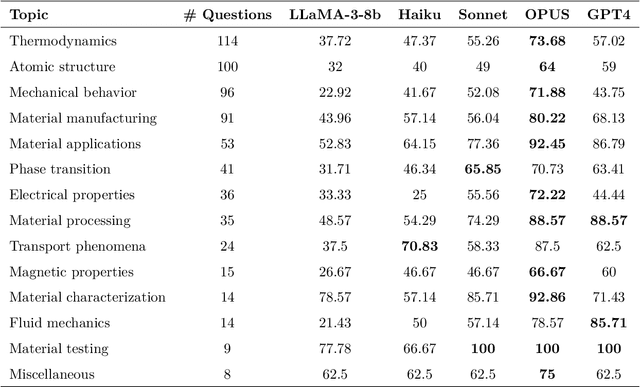
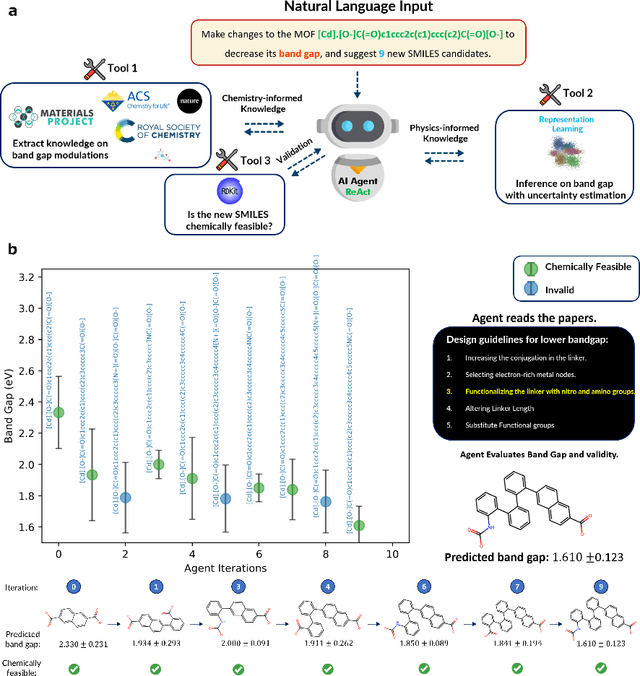
Large Language Models (LLMs) are reshaping many aspects of materials science and chemistry research, enabling advances in molecular property prediction, materials design, scientific automation, knowledge extraction, and more. Recent developments demonstrate that the latest class of models are able to integrate structured and unstructured data, assist in hypothesis generation, and streamline research workflows. To explore the frontier of LLM capabilities across the research lifecycle, we review applications of LLMs through 34 total projects developed during the second annual Large Language Model Hackathon for Applications in Materials Science and Chemistry, a global hybrid event. These projects spanned seven key research areas: (1) molecular and material property prediction, (2) molecular and material design, (3) automation and novel interfaces, (4) scientific communication and education, (5) research data management and automation, (6) hypothesis generation and evaluation, and (7) knowledge extraction and reasoning from the scientific literature. Collectively, these applications illustrate how LLMs serve as versatile predictive models, platforms for rapid prototyping of domain-specific tools, and much more. In particular, improvements in both open source and proprietary LLM performance through the addition of reasoning, additional training data, and new techniques have expanded effectiveness, particularly in low-data environments and interdisciplinary research. As LLMs continue to improve, their integration into scientific workflows presents both new opportunities and new challenges, requiring ongoing exploration, continued refinement, and further research to address reliability, interpretability, and reproducibility.
Think Deep, Think Fast: Investigating Efficiency of Verifier-free Inference-time-scaling Methods
Apr 18, 2025There is intense interest in investigating how inference time compute (ITC) (e.g. repeated sampling, refinements, etc) can improve large language model (LLM) capabilities. At the same time, recent breakthroughs in reasoning models, such as Deepseek-R1, unlock the opportunity for reinforcement learning to improve LLM reasoning skills. An in-depth understanding of how ITC interacts with reasoning across different models could provide important guidance on how to further advance the LLM frontier. This work conducts a comprehensive analysis of inference-time scaling methods for both reasoning and non-reasoning models on challenging reasoning tasks. Specifically, we focus our research on verifier-free inference time-scaling methods due to its generalizability without needing a reward model. We construct the Pareto frontier of quality and efficiency. We find that non-reasoning models, even with an extremely high inference budget, still fall substantially behind reasoning models. For reasoning models, majority voting proves to be a robust inference strategy, generally competitive or outperforming other more sophisticated ITC methods like best-of-N and sequential revisions, while the additional inference compute offers minimal improvements. We further perform in-depth analyses of the association of key response features (length and linguistic markers) with response quality, with which we can improve the existing ITC methods. We find that correct responses from reasoning models are typically shorter and have fewer hedging and thinking markers (but more discourse markers) than the incorrect responses.
Scaling Instruction-Tuned LLMs to Million-Token Contexts via Hierarchical Synthetic Data Generation
Apr 17, 2025Large Language Models (LLMs) struggle with long-context reasoning, not only due to the quadratic scaling of computational complexity with sequence length but also because of the scarcity and expense of annotating long-context data. There has been barely any open-source work that systematically ablates long-context data, nor is there any openly available instruction tuning dataset with contexts surpassing 100K tokens. To bridge this gap, we introduce a novel post-training synthetic data generation strategy designed to efficiently extend the context window of LLMs while preserving their general task performance. Our approach scalably extends to arbitrarily long context lengths, unconstrained by the length of available real-world data, which effectively addresses the scarcity of raw long-context data. Through a step-by-step rotary position embedding (RoPE) scaling training strategy, we demonstrate that our model, with a context length of up to 1M tokens, performs well on the RULER benchmark and InfiniteBench and maintains robust performance on general language tasks.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Open-Source Fermionic Neural Networks with Ionic Charge Initialization
Jan 16, 2024Finding accurate solutions to the electronic Schr\"odinger equation plays an important role in discovering important molecular and material energies and characteristics. Consequently, solving systems with large numbers of electrons has become increasingly important. Variational Monte Carlo (VMC) methods, especially those approximated through deep neural networks, are promising in this regard. In this paper, we aim to integrate one such model called the FermiNet, a post-Hartree-Fock (HF) Deep Neural Network (DNN) model, into a standard and widely used open source library, DeepChem. We also propose novel initialization techniques to overcome the difficulties associated with the assignment of excess or lack of electrons for ions.
Differentiable Chemical Physics by Geometric Deep Learning for Gradient-based Property Optimization of Mixtures
Oct 03, 2023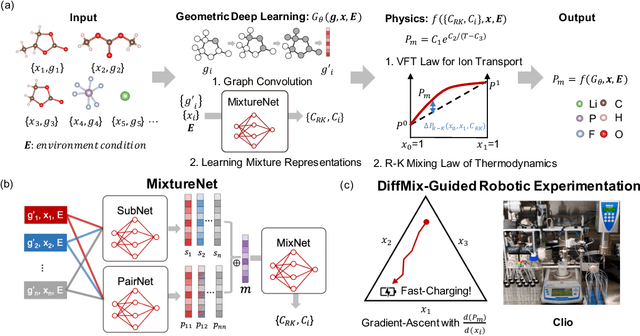
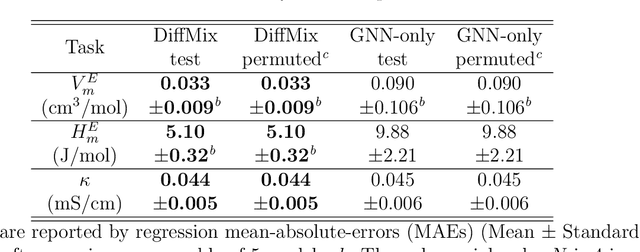
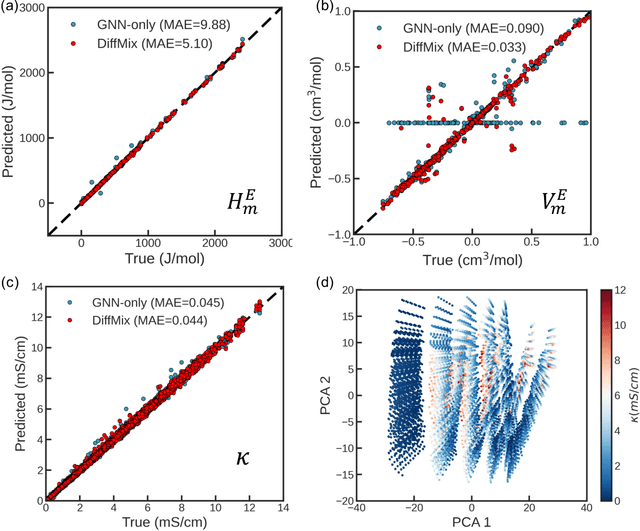
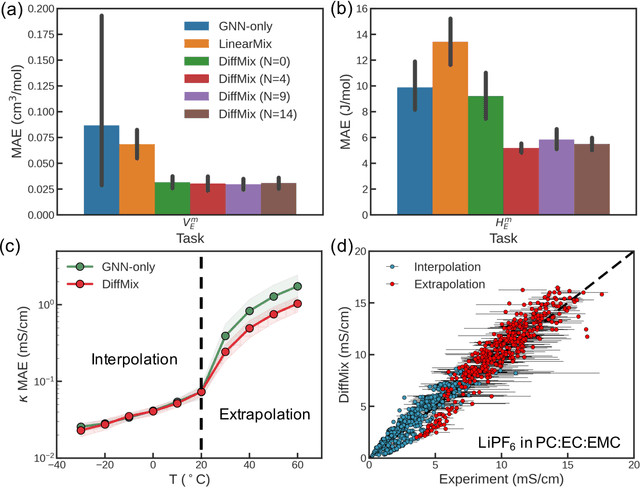
Chemical mixtures, satisfying multi-objective performance metrics and constraints, enable their use in chemical processes and electrochemical devices. In this work, we develop a differentiable chemical-physics framework for modeling chemical mixtures, DiffMix, where geometric deep learning (GDL) is leveraged to map from molecular species, compositions and environment conditions, to physical coefficients in the mixture physics laws. In particular, we extend mixture thermodynamic and transport laws by creating learnable physical coefficients, where we use graph neural networks as the molecule encoder and enforce component-wise permutation-invariance. We start our model evaluations with thermodynamics of binary mixtures, and further benchmarked multicomponent electrolyte mixtures on their transport properties, in order to test the model generalizability. We show improved prediction accuracy and model robustness of DiffMix than its purely data-driven variants. Furthermore, we demonstrate the efficient optimization of electrolyte transport properties, built on the gradient obtained using DiffMix auto-differentiation. Our simulation runs are then backed up by the data generated by a robotic experimentation setup, Clio. By combining mixture physics and GDL, DiffMix expands the predictive modeling methods for chemical mixtures and provides low-cost optimization approaches in large chemical spaces.
Open Source Infrastructure for Differentiable Density Functional Theory
Sep 27, 2023



Learning exchange correlation functionals, used in quantum chemistry calculations, from data has become increasingly important in recent years, but training such a functional requires sophisticated software infrastructure. For this reason, we build open source infrastructure to train neural exchange correlation functionals. We aim to standardize the processing pipeline by adapting state-of-the-art techniques from work done by multiple groups. We have open sourced the model in the DeepChem library to provide a platform for additional research on differentiable quantum chemistry methods.