 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time
Dec 31, 2025Large Language Models (LLMs) often rely on long chain-of-thought (CoT) reasoning to solve complex tasks. While effective, these trajectories are frequently inefficient, leading to high latency from excessive token generation, or unstable reasoning that alternates between underthinking (shallow, inconsistent steps) and overthinking (repetitive, verbose reasoning). In this work, we study the structure of reasoning trajectories and uncover specialized attention heads that correlate with distinct cognitive behaviors such as verification and backtracking. By lightly intervening on these heads at inference time, we can steer the model away from inefficient modes. Building on this insight, we propose CREST, a training-free method for Cognitive REasoning Steering at Test-time. CREST has two components: (1) an offline calibration step that identifies cognitive heads and derives head-specific steering vectors, and (2) an inference-time procedure that rotates hidden representations to suppress components along those vectors. CREST adaptively suppresses unproductive reasoning behaviors, yielding both higher accuracy and lower computational cost. Across diverse reasoning benchmarks and models, CREST improves accuracy by up to 17.5% while reducing token usage by 37.6%, offering a simple and effective pathway to faster, more reliable LLM reasoning.
Beat the long tail: Distribution-Aware Speculative Decoding for RL Training
Nov 17, 2025Reinforcement learning(RL) post-training has become essential for aligning large language models (LLMs), yet its efficiency is increasingly constrained by the rollout phase, where long trajectories are generated token by token. We identify a major bottleneck:the long-tail distribution of rollout lengths, where a small fraction of long generations dominates wall clock time and a complementary opportunity; the availability of historical rollouts that reveal stable prompt level patterns across training epochs. Motivated by these observations, we propose DAS, a Distribution Aware Speculative decoding framework that accelerates RL rollouts without altering model outputs. DAS integrates two key ideas: an adaptive, nonparametric drafter built from recent rollouts using an incrementally maintained suffix tree, and a length aware speculation policy that allocates more aggressive draft budgets to long trajectories that dominate makespan. This design exploits rollout history to sustain acceptance while balancing base and token level costs during decoding. Experiments on math and code reasoning tasks show that DAS reduces rollout time up to 50% while preserving identical training curves, demonstrating that distribution-aware speculative decoding can significantly accelerate RL post training without compromising learning quality.
Data Diversification Methods In Alignment Enhance Math Performance In LLMs
Jul 02, 2025



While recent advances in preference learning have enhanced alignment in human feedback, mathematical reasoning remains a persistent challenge. We investigate how data diversification strategies in preference optimization can improve the mathematical reasoning abilities of large language models (LLMs). We evaluate three common data generation methods: temperature sampling, Chain-of-Thought prompting, and Monte Carlo Tree Search (MCTS), and introduce Diversified-ThinkSolve (DTS), a novel structured approach that systematically decomposes problems into diverse reasoning paths. Our results show that with strategically diversified preference data, models can substantially improve mathematical reasoning performance, with the best approach yielding gains of 7.1% on GSM8K and 4.2% on MATH over the base model. Despite its strong performance, DTS incurs only a marginal computational overhead (1.03x) compared to the baseline, while MCTS is nearly five times more costly with lower returns. These findings demonstrate that structured exploration of diverse problem-solving methods creates more effective preference data for mathematical alignment than traditional approaches.
Disentangling Reasoning and Knowledge in Medical Large Language Models
May 16, 2025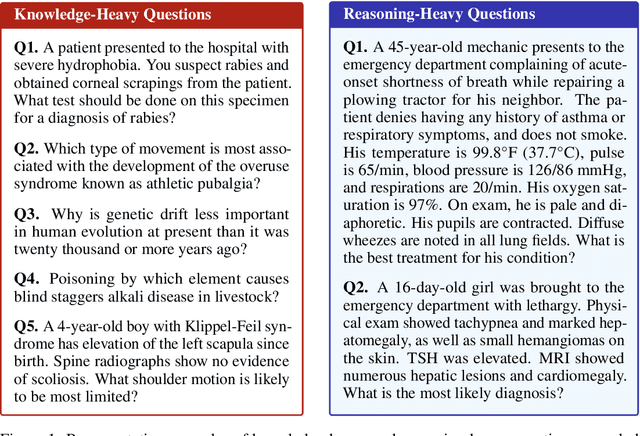
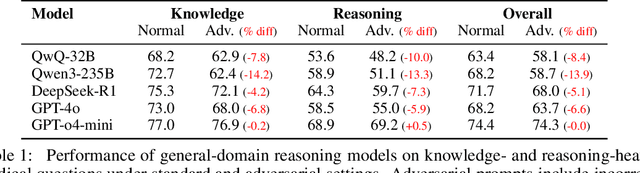
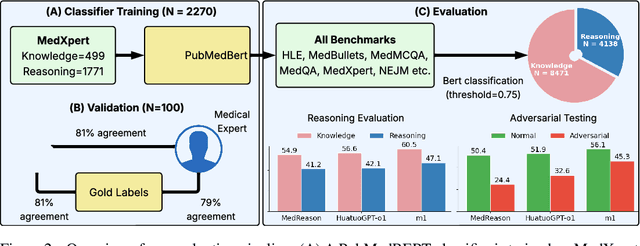
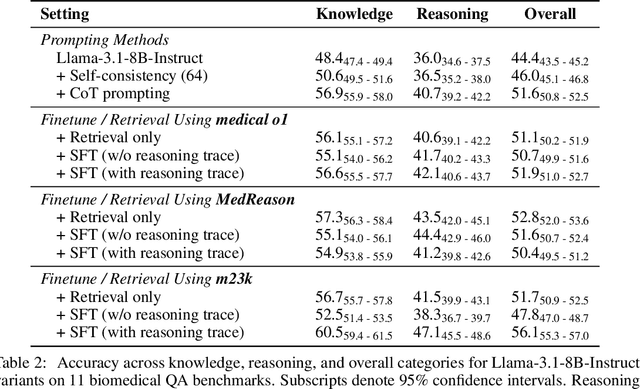
Medical reasoning in large language models (LLMs) aims to emulate clinicians' diagnostic thinking, but current benchmarks such as MedQA-USMLE, MedMCQA, and PubMedQA often mix reasoning with factual recall. We address this by separating 11 biomedical QA benchmarks into reasoning- and knowledge-focused subsets using a PubMedBERT classifier that reaches 81 percent accuracy, comparable to human performance. Our analysis shows that only 32.8 percent of questions require complex reasoning. We evaluate biomedical models (HuatuoGPT-o1, MedReason, m1) and general-domain models (DeepSeek-R1, o4-mini, Qwen3), finding consistent gaps between knowledge and reasoning performance. For example, m1 scores 60.5 on knowledge but only 47.1 on reasoning. In adversarial tests where models are misled with incorrect initial reasoning, biomedical models degrade sharply, while larger or RL-trained general models show more robustness. To address this, we train BioMed-R1 using fine-tuning and reinforcement learning on reasoning-heavy examples. It achieves the strongest performance among similarly sized models. Further gains may come from incorporating clinical case reports and training with adversarial and backtracking scenarios.
How Well Can General Vision-Language Models Learn Medicine By Watching Public Educational Videos?
Apr 19, 2025Publicly available biomedical videos, such as those on YouTube, serve as valuable educational resources for medical students. Unlike standard machine learning datasets, these videos are designed for human learners, often mixing medical imagery with narration, explanatory diagrams, and contextual framing. In this work, we investigate whether such pedagogically rich, yet non-standardized and heterogeneous videos can effectively teach general-domain vision-language models biomedical knowledge. To this end, we introduce OpenBiomedVi, a biomedical video instruction tuning dataset comprising 1031 hours of video-caption and Q/A pairs, curated through a multi-step human-in-the-loop pipeline. Diverse biomedical video datasets are rare, and OpenBiomedVid fills an important gap by providing instruction-style supervision grounded in real-world educational content. Surprisingly, despite the informal and heterogeneous nature of these videos, the fine-tuned Qwen-2-VL models exhibit substantial performance improvements across most benchmarks. The 2B model achieves gains of 98.7% on video tasks, 71.2% on image tasks, and 0.2% on text tasks. The 7B model shows improvements of 37.09% on video and 11.2% on image tasks, with a slight degradation of 2.7% on text tasks compared to their respective base models. To address the lack of standardized biomedical video evaluation datasets, we also introduce two new expert curated benchmarks, MIMICEchoQA and SurgeryVideoQA. On these benchmarks, the 2B model achieves gains of 99.1% and 98.1%, while the 7B model shows gains of 22.5% and 52.1%, respectively, demonstrating the models' ability to generalize and perform biomedical video understanding on cleaner and more standardized datasets than those seen during training. These results suggest that educational videos created for human learning offer a surprisingly effective training signal for biomedical VLMs.
Think Deep, Think Fast: Investigating Efficiency of Verifier-free Inference-time-scaling Methods
Apr 18, 2025There is intense interest in investigating how inference time compute (ITC) (e.g. repeated sampling, refinements, etc) can improve large language model (LLM) capabilities. At the same time, recent breakthroughs in reasoning models, such as Deepseek-R1, unlock the opportunity for reinforcement learning to improve LLM reasoning skills. An in-depth understanding of how ITC interacts with reasoning across different models could provide important guidance on how to further advance the LLM frontier. This work conducts a comprehensive analysis of inference-time scaling methods for both reasoning and non-reasoning models on challenging reasoning tasks. Specifically, we focus our research on verifier-free inference time-scaling methods due to its generalizability without needing a reward model. We construct the Pareto frontier of quality and efficiency. We find that non-reasoning models, even with an extremely high inference budget, still fall substantially behind reasoning models. For reasoning models, majority voting proves to be a robust inference strategy, generally competitive or outperforming other more sophisticated ITC methods like best-of-N and sequential revisions, while the additional inference compute offers minimal improvements. We further perform in-depth analyses of the association of key response features (length and linguistic markers) with response quality, with which we can improve the existing ITC methods. We find that correct responses from reasoning models are typically shorter and have fewer hedging and thinking markers (but more discourse markers) than the incorrect responses.
SMIR: Efficient Synthetic Data Pipeline To Improve Multi-Image Reasoning
Jan 07, 2025Vision-Language Models (VLMs) have shown strong performance in understanding single images, aided by numerous high-quality instruction datasets. However, multi-image reasoning tasks are still under-explored in the open-source community due to two main challenges: (1) scaling datasets with multiple correlated images and complex reasoning instructions is resource-intensive and maintaining quality is difficult, and (2) there is a lack of robust evaluation benchmarks for multi-image tasks. To address these issues, we introduce SMIR, an efficient synthetic data-generation pipeline for multi-image reasoning, and a high-quality dataset generated using this pipeline. Our pipeline efficiently extracts highly correlated images using multimodal embeddings, combining visual and descriptive information and leverages open-source LLMs to generate quality instructions. Using this pipeline, we generated 160K synthetic training samples, offering a cost-effective alternative to expensive closed-source solutions. Additionally, we present SMIR-BENCH, a novel multi-image reasoning evaluation benchmark comprising 200 diverse examples across 7 complex multi-image reasoning tasks. SMIR-BENCH is multi-turn and utilizes a VLM judge to evaluate free-form responses, providing a comprehensive assessment of model expressiveness and reasoning capability across modalities. We demonstrate the effectiveness of SMIR dataset by fine-tuning several open-source VLMs and evaluating their performance on SMIR-BENCH. Our results show that models trained on our dataset outperform baseline models in multi-image reasoning tasks up to 8% with a much more scalable data pipeline.
Improving Causal Reasoning in Large Language Models: A Survey
Oct 22, 2024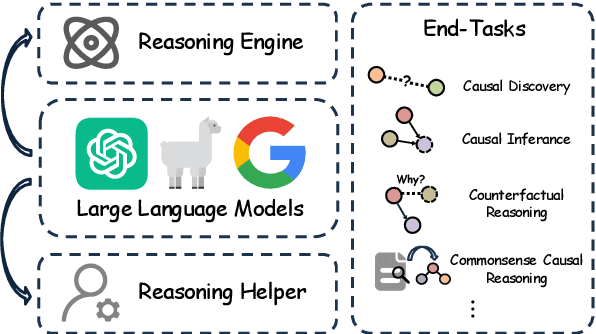
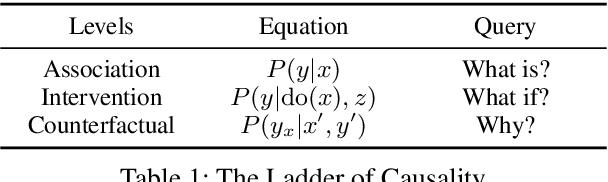


Causal reasoning (CR) is a crucial aspect of intelligence, essential for problem-solving, decision-making, and understanding the world. While large language models (LLMs) can generate rationales for their outputs, their ability to reliably perform causal reasoning remains uncertain, often falling short in tasks requiring a deep understanding of causality. In this survey, we provide a comprehensive review of research aimed at enhancing LLMs for causal reasoning. We categorize existing methods based on the role of LLMs: either as reasoning engines or as helpers providing knowledge or data to traditional CR methods, followed by a detailed discussion of the methodologies in each category. We then evaluate the performance of LLMs on various causal reasoning tasks, providing key findings and in-depth analysis. Finally, we provide insights from current studies and highlight promising directions for future research. We aim for this work to serve as a comprehensive resource, fostering further advancements in causal reasoning with LLMs. Resources are available at https://github.com/chendl02/Awesome-LLM-causal-reasoning.
Mamba-Enhanced Text-Audio-Video Alignment Network for Emotion Recognition in Conversations
Sep 08, 2024



Emotion Recognition in Conversations (ERCs) is a vital area within multimodal interaction research, dedicated to accurately identifying and classifying the emotions expressed by speakers throughout a conversation. Traditional ERC approaches predominantly rely on unimodal cues\-such as text, audio, or visual data\-leading to limitations in their effectiveness. These methods encounter two significant challenges: 1) Consistency in multimodal information. Before integrating various modalities, it is crucial to ensure that the data from different sources is aligned and coherent. 2) Contextual information capture. Successfully fusing multimodal features requires a keen understanding of the evolving emotional tone, especially in lengthy dialogues where emotions may shift and develop over time. To address these limitations, we propose a novel Mamba-enhanced Text-Audio-Video alignment network (MaTAV) for the ERC task. MaTAV is with the advantages of aligning unimodal features to ensure consistency across different modalities and handling long input sequences to better capture contextual multimodal information. The extensive experiments on the MELD and IEMOCAP datasets demonstrate that MaTAV significantly outperforms existing state-of-the-art methods on the ERC task with a big margin.
LIONs: An Empirically Optimized Approach to Align Language Models
Jul 09, 2024

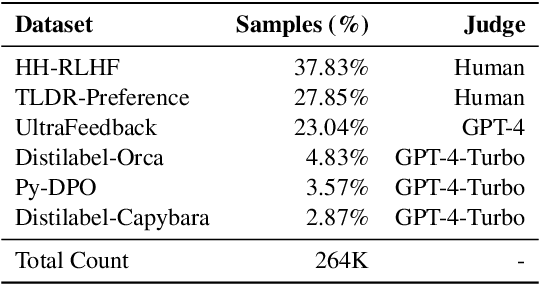

Alignment is a crucial step to enhance the instruction-following and conversational abilities of language models. Despite many recent work proposing new algorithms, datasets, and training pipelines, there is a lack of comprehensive studies measuring the impact of various design choices throughout the whole training process. We first conduct a rigorous analysis over a three-stage training pipeline consisting of supervised fine-tuning, offline preference learning, and online preference learning. We have found that using techniques like sequence packing, loss masking in SFT, increasing the preference dataset size in DPO, and online DPO training can significantly improve the performance of language models. We then train from Gemma-2b-base and LLama-3-8b-base, and find that our best models exceed the performance of the official instruct models tuned with closed-source data and algorithms. Our code and models can be found at https://github.com/Columbia-NLP-Lab/LionAlignment.