 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperlocal disaster damage assessment using bi-temporal street-view imagery and pre-trained vision models
Apr 12, 2025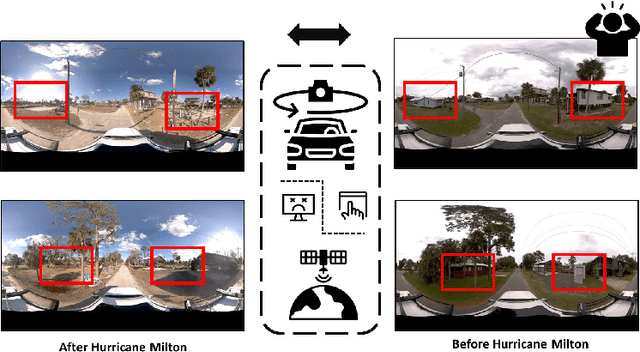
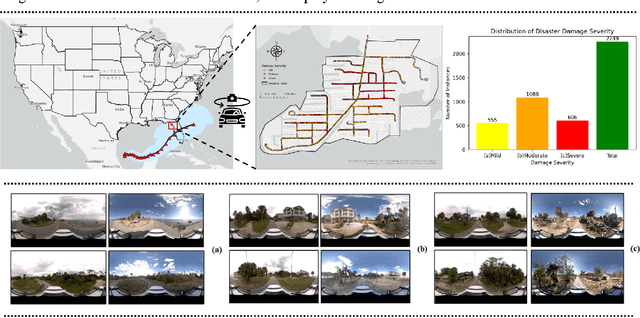
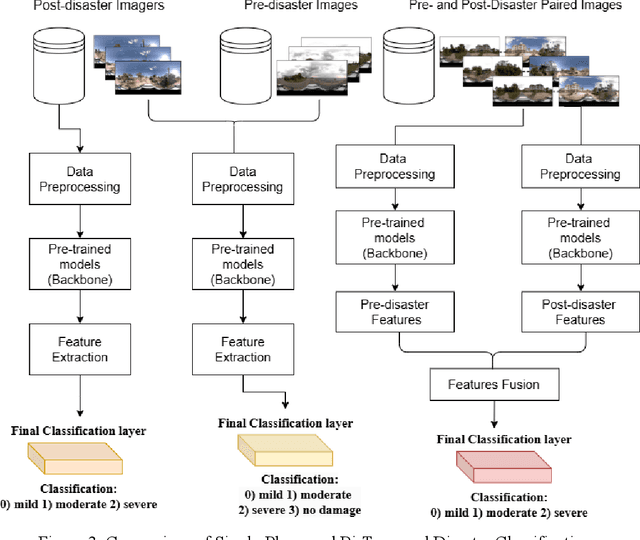
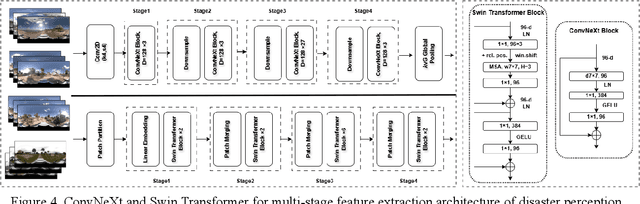
Street-view images offer unique advantages for disaster damage estimation as they capture impacts from a visual perspective and provide detailed, on-the-ground insights. Despite several investigations attempting to analyze street-view images for damage estimation, they mainly focus on post-disaster images. The potential of time-series street-view images remains underexplored. Pre-disaster images provide valuable benchmarks for accurate damage estimations at building and street levels. These images could aid annotators in objectively labeling post-disaster impacts, improving the reliability of labeled data sets for model training, and potentially enhancing the model performance in damage evaluation. The goal of this study is to estimate hyperlocal, on-the-ground disaster damages using bi-temporal street-view images and advanced pre-trained vision models. Street-view images before and after 2024 Hurricane Milton in Horseshoe Beach, Florida, were collected for experiments. The objectives are: (1) to assess the performance gains of incorporating pre-disaster street-view images as a no-damage category in fine-tuning pre-trained models, including Swin Transformer and ConvNeXt, for damage level classification; (2) to design and evaluate a dual-channel algorithm that reads pair-wise pre- and post-disaster street-view images for hyperlocal damage assessment. The results indicate that incorporating pre-disaster street-view images and employing a dual-channel processing framework can significantly enhance damage assessment accuracy. The accuracy improves from 66.14% with the Swin Transformer baseline to 77.11% with the dual-channel Feature-Fusion ConvNeXt model. This research enables rapid, operational damage assessments at hyperlocal spatial resolutions, providing valuable insights to support effective decision-making in disaster management and resilience planning.
Exploring Multilingual Probing in Large Language Models: A Cross-Language Analysis
Sep 22, 2024



Probing techniques for large language models (LLMs) have primarily focused on English, overlooking the vast majority of the world's languages. In this paper, we extend these probing methods to a multilingual context, investigating the behaviors of LLMs across diverse languages. We conduct experiments on several open-source LLM models, analyzing probing accuracy, trends across layers, and similarities between probing vectors for multiple languages. Our key findings reveal: (1) a consistent performance gap between high-resource and low-resource languages, with high-resource languages achieving significantly higher probing accuracy; (2) divergent layer-wise accuracy trends, where high-resource languages show substantial improvement in deeper layers similar to English; and (3) higher representational similarities among high-resource languages, with low-resource languages demonstrating lower similarities both among themselves and with high-resource languages. These results highlight significant disparities in LLMs' multilingual capabilities and emphasize the need for improved modeling of low-resource languages.
Attention: Large Multimodal Model is Watching your Geo-privacy
Nov 21, 2023
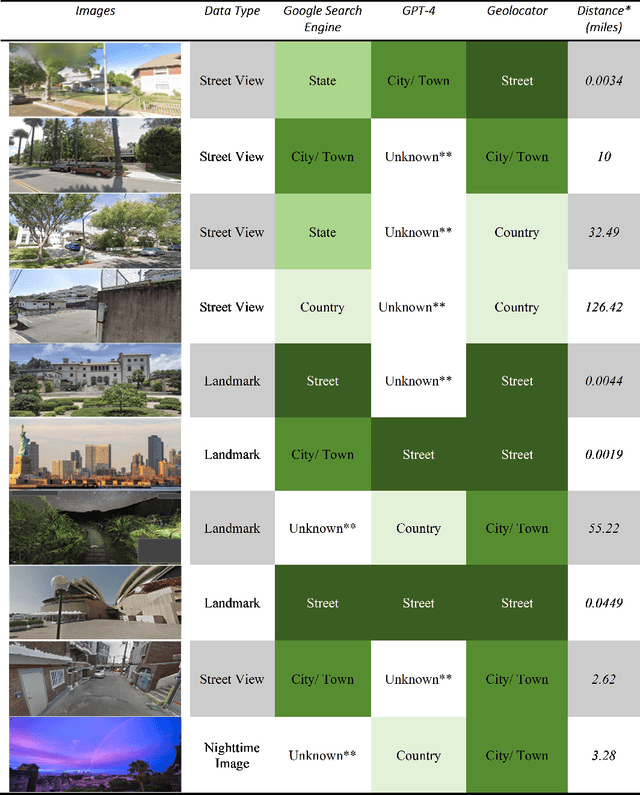
Geographic privacy, a crucial aspect of personal security, often goes unnoticed in daily activities. This paper addresses the underestimation of this privacy in the context of increasing online data sharing and the advancements in information gathering technologies. With the surge in the use of Large Multimodal Models, such as GPT-4, for Open Source Intelligence (OSINT), the potential risks associated with geographic privacy breaches have intensified. This study highlights the criticality of these developments, focusing on their implications for individual privacy. The primary objective is to demonstrate the capabilities of advanced AI tools, specifically a GPT-4 based model named "Dr. Watson," in identifying and potentially compromising geographic privacy through online shared content. We developed "Dr. Watson" to analyze and extract geographic information from publicly available data sources. The study involved five experimental cases, each offering different perspectives on the tool's application in extracting precise location data from partial images and social media content. The experiments revealed that "Dr. Watson" could successfully identify specific geographic details, thereby exposing the vulnerabilities in current geo-privacy measures. These findings underscore the ease with which geographic information can be unintentionally disclosed. The paper concludes with a discussion on the broader implications of these findings for individuals and the community at large. It emphasizes the urgency for enhanced awareness and protective measures against geo-privacy leakage in the era of advanced AI and widespread social media usage.