 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenRFM: Dissecting Relational In-Context Learning
Jun 03, 2026Relational Foundation Models (RFMs) promise a single pre-trained predictor that, given any relational database, returns predictions in one forward pass via relational in-context learning (ICL). Yet a substantial gap separates open RFMs from their commercial counterparts, and the origin of this gap has not been systematically understood. We dissect a representative framework, the Relational Transformer (RT), from two perspectives. Model side: we show that RT performs relation-level ICL, and a kernel regression view shows it fails when sparse label-cell coverage yields an underdetermined regression. Data side: we ablate RT's pre-training source and find that existing synthetic-only pre-training and in-distribution pre-training drive the same architecture into different regimes, lazy vs. feature-learning. Probing this gap reveals that the missing ingredient is a support-identifiable relational latent in the label-generation process. These two diagnoses translate into (1) a dual-stage ICL architecture that combines the relational backbone with a batch-level ICL layer lifted from a pre-trained tabular foundation model to overcome relation-level label scarcity, and (2) a homophily-aware synthetic plus continual real-data pre-training mixture, augmented with a prototype-based regularization. These choices define OpenRFM, a simple yet effective RFM that improves average task performance by approximately 30% over the RT backbone and surpasses the commercial model KumoRFMv1 on a large set of evaluation tasks.
DSL-LLaDA: Scaling Continuous Denoising to 8B Masked Diffusion LMs
May 31, 2026Discrete Masked diffusion language models generate text by iterative parallel decoding, but few-step decoding suffers from a tradeoff between length and quality: with a fixed step budget, standard methods can generate a short, high-quality output, or they can produce long but repetitive text. Continuous denoising can sidestep this tradeoff by evolving all positions jointly in embedding space, but building such a model from scratch at scale remains an open problem. We show that a pretrained masked DLM can instead be lightly adapted to support continuous embedding-space denoising. Starting from LLaDA-8B-Instruct, we continue-pretrain for only 1,000 steps with Discrete Stochastic Localization (DSL), replacing binary masking with continuous per-token Gaussian noise as a soft mask. The adapted model supports continuous inference that evolves all positions jointly in embedding space and defers hard token commitment to the final step. On zero-shot summarization at low step budgets (<=16 forward passes), DSL-LLaDA-SDE achieves the best ROUGE-1 on all four benchmarks and largely avoids the premature-termination / repetition tradeoff of iterative unmasking. The same adaptation also yields selective noisy-state robustness: the model corrects corrupted tokens while preserving clean ones. Control experiments using standard masked diffusion training with the same compute demonstrate neither behavior.
Do Proactive Agents Really Need an LLM to Decide When to Wake and What to Anchor?
May 28, 2026Proactive agents read user activity as text and call an LLM on every event to decide whether to act. But user activity is not natively text: it is a structured event stream of (actor, verb, object, timestamp) tuples that the operating system already maintains in graph form. Rendering the structure as text and asking an LLM to recover it is a round-trip the system never had to take. We treat the always-on signal as graph updates rather than text and use a small temporal-graph-learning (TGL) model as the encoder: one forward pass yields a per-event trigger probability and a per-entity routing score, and only the downstream agent (turning a small structured handoff into a fluent user-facing sentence) is an LLM call, invoked only when the trigger fires. TGL improves F1 on each of 14 backbones (mean +16.7, up to +46.0); in trigger-architecture comparisons, one TGL checkpoint gives the strongest trigger AUCs and the most stable deployed threshold. It runs at 11.13 ms per event on a GPU server and 13.99 ms on a consumer laptop, approximately 4--7x and 12--83x faster than every single-forward LLM-as-trigger configuration tested in each regime, with an approximately 220 MiB BF16 resident footprint deployable on-device alongside the privacy-sensitive activity stream it consumes.
The Vision Wormhole: Latent-Space Communication in Heterogeneous Multi-Agent Systems
Feb 17, 2026Multi-Agent Systems (MAS) powered by Large Language Models have unlocked advanced collaborative reasoning, yet they remain shackled by the inefficiency of discrete text communication, which imposes significant runtime overhead and information quantization loss. While latent state transfer offers a high-bandwidth alternative, existing approaches either assume homogeneous sender-receiver architectures or rely on pair-specific learned translators, limiting scalability and modularity across diverse model families with disjoint manifolds. In this work, we propose the Vision Wormhole, a novel framework that repurposes the visual interface of Vision-Language Models (VLMs) to enable model-agnostic, text-free communication. By introducing a Universal Visual Codec, we map heterogeneous reasoning traces into a shared continuous latent space and inject them directly into the receiver's visual pathway, effectively treating the vision encoder as a universal port for inter-agent telepathy. Our framework adopts a hub-and-spoke topology to reduce pairwise alignment complexity from O(N^2) to O(N) and leverages a label-free, teacher-student distillation objective to align the high-speed visual channel with the robust reasoning patterns of the text pathway. Extensive experiments across heterogeneous model families (e.g., Qwen-VL, Gemma) demonstrate that the Vision Wormhole reduces end-to-end wall-clock time in controlled comparisons while maintaining reasoning fidelity comparable to standard text-based MAS. Code is available at https://github.com/xz-liu/heterogeneous-latent-mas
Scaling Search-Augmented LLM Reasoning via Adaptive Information Control
Feb 02, 2026Search-augmented reasoning agents interleave multi-step reasoning with external information retrieval, but uncontrolled retrieval often leads to redundant evidence, context saturation, and unstable learning. Existing approaches rely on outcome-based reinforcement learning (RL), which provides limited guidance for regulating information acquisition. We propose DeepControl, a framework for adaptive information control based on a formal notion of information utility, which measures the marginal value of retrieved evidence under a given reasoning state. Building on this utility, we introduce retrieval continuation and granularity control mechanisms that selectively regulate when to continue and stop retrieval, and how much information to expand. An annealed control strategy enables the agent to internalize effective information acquisition behaviors during training. Extensive experiments across seven benchmarks demonstrate that our method consistently outperforms strong baselines. In particular, our approach achieves average performance improvements of 9.4% and 8.6% on Qwen2.5-7B and Qwen2.5-3B, respectively, over strong outcome-based RL baselines, and consistently outperforms both retrieval-free and retrieval-based reasoning methods without explicit information control. These results highlight the importance of adaptive information control for scaling search-augmented reasoning agents to complex, real-world information environments.
PathWise: Planning through World Model for Automated Heuristic Design via Self-Evolving LLMs
Jan 29, 2026Large Language Models (LLMs) have enabled automated heuristic design (AHD) for combinatorial optimization problems (COPs), but existing frameworks' reliance on fixed evolutionary rules and static prompt templates often leads to myopic heuristic generation, redundant evaluations, and limited reasoning about how new heuristics should be derived. We propose a novel multi-agent reasoning framework, referred to as Planning through World Model for Automated Heuristic Design via Self-Evolving LLMs (PathWise), which formulates heuristic generation as a sequential decision process over an entailment graph serving as a compact, stateful memory of the search trajectory. This approach allows the system to carry forward past decisions and reuse or avoid derivation information across generations. A policy agent plans evolutionary actions, a world model agent generates heuristic rollouts conditioned on those actions, and critic agents provide routed reflections summarizing lessons from prior steps, shifting LLM-based AHD from trial-and-error evolution toward state-aware planning through reasoning. Experiments across diverse COPs show that PathWise converges faster to better heuristics, generalizes across different LLM backbones, and scales to larger problem sizes.
Automated Sentiment Classification and Topic Discovery in Large-Scale Social Media Streams
May 03, 2025We present a framework for large-scale sentiment and topic analysis of Twitter discourse. Our pipeline begins with targeted data collection using conflict-specific keywords, followed by automated sentiment labeling via multiple pre-trained models to improve annotation robustness. We examine the relationship between sentiment and contextual features such as timestamp, geolocation, and lexical content. To identify latent themes, we apply Latent Dirichlet Allocation (LDA) on partitioned subsets grouped by sentiment and metadata attributes. Finally, we develop an interactive visualization interface to support exploration of sentiment trends and topic distributions across time and regions. This work contributes a scalable methodology for social media analysis in dynamic geopolitical contexts.
Positional Attention for Efficient BERT-Based Named Entity Recognition
May 03, 2025



This paper presents a framework for Named Entity Recognition (NER) leveraging the Bidirectional Encoder Representations from Transformers (BERT) model in natural language processing (NLP). NER is a fundamental task in NLP with broad applicability across downstream applications. While BERT has established itself as a state-of-the-art model for entity recognition, fine-tuning it from scratch for each new application is computationally expensive and time-consuming. To address this, we propose a cost-efficient approach that integrates positional attention mechanisms into the entity recognition process and enables effective customization using pre-trained parameters. The framework is evaluated on a Kaggle dataset derived from the Groningen Meaning Bank corpus and achieves strong performance with fewer training epochs. This work contributes to the field by offering a practical solution for reducing the training cost of BERT-based NER systems while maintaining high accuracy.
SymPlanner: Deliberate Planning in Language Models with Symbolic Representation
May 02, 2025Planning remains a core challenge for language models (LMs), particularly in domains that require coherent multi-step action sequences grounded in external constraints. We introduce SymPlanner, a novel framework that equips LMs with structured planning capabilities by interfacing them with a symbolic environment that serves as an explicit world model. Rather than relying purely on natural language reasoning, SymPlanner grounds the planning process in a symbolic state space, where a policy model proposes actions and a symbolic environment deterministically executes and verifies their effects. To enhance exploration and improve robustness, we introduce Iterative Correction (IC), which refines previously proposed actions by leveraging feedback from the symbolic environment to eliminate invalid decisions and guide the model toward valid alternatives. Additionally, Contrastive Ranking (CR) enables fine-grained comparison of candidate plans by evaluating them jointly. We evaluate SymPlanner on PlanBench, demonstrating that it produces more coherent, diverse, and verifiable plans than pure natural language baselines.
Improving Causal Reasoning in Large Language Models: A Survey
Oct 22, 2024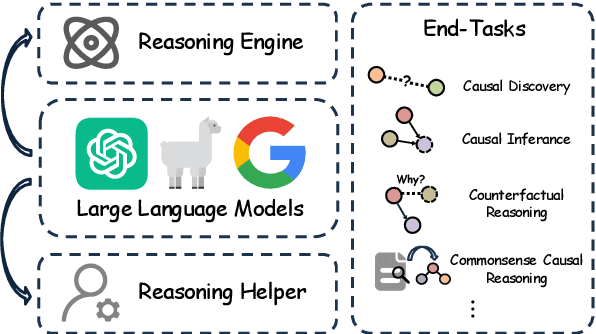
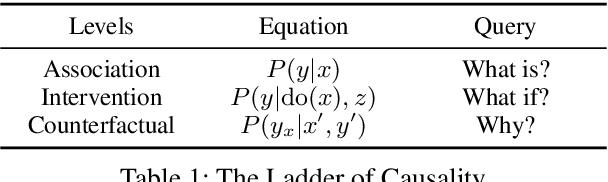


Causal reasoning (CR) is a crucial aspect of intelligence, essential for problem-solving, decision-making, and understanding the world. While large language models (LLMs) can generate rationales for their outputs, their ability to reliably perform causal reasoning remains uncertain, often falling short in tasks requiring a deep understanding of causality. In this survey, we provide a comprehensive review of research aimed at enhancing LLMs for causal reasoning. We categorize existing methods based on the role of LLMs: either as reasoning engines or as helpers providing knowledge or data to traditional CR methods, followed by a detailed discussion of the methodologies in each category. We then evaluate the performance of LLMs on various causal reasoning tasks, providing key findings and in-depth analysis. Finally, we provide insights from current studies and highlight promising directions for future research. We aim for this work to serve as a comprehensive resource, fostering further advancements in causal reasoning with LLMs. Resources are available at https://github.com/chendl02/Awesome-LLM-causal-reasoning.