 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
YuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models
Jan 22, 2026As large language models (LLMs) are increasingly deployed in real-world applications, safety guardrails are required to go beyond coarse-grained filtering and support fine-grained, interpretable, and adaptable risk assessment. However, existing solutions often rely on rapid classification schemes or post-hoc rules, resulting in limited transparency, inflexible policies, or prohibitive inference costs. To this end, we present YuFeng-XGuard, a reasoning-centric guardrail model family designed to perform multi-dimensional risk perception for LLM interactions. Instead of producing opaque binary judgments, YuFeng-XGuard generates structured risk predictions, including explicit risk categories and configurable confidence scores, accompanied by natural language explanations that expose the underlying reasoning process. This formulation enables safety decisions that are both actionable and interpretable. To balance decision latency and explanatory depth, we adopt a tiered inference paradigm that performs an initial risk decision based on the first decoded token, while preserving ondemand explanatory reasoning when required. In addition, we introduce a dynamic policy mechanism that decouples risk perception from policy enforcement, allowing safety policies to be adjusted without model retraining. Extensive experiments on a diverse set of public safety benchmarks demonstrate that YuFeng-XGuard achieves stateof-the-art performance while maintaining strong efficiency-efficacy trade-offs. We release YuFeng-XGuard as an open model family, including both a full-capacity variant and a lightweight version, to support a wide range of deployment scenarios.
UmniBench: Unified Understand and Generation Model Oriented Omni-dimensional Benchmark
Dec 19, 2025Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. However, evaluations of unified multimodal models (UMMs) remain decoupled, assessing their understanding and generation abilities separately with corresponding datasets. To address this, we propose UmniBench, a benchmark tailored for UMMs with omni-dimensional evaluation. First, UmniBench can assess the understanding, generation, and editing ability within a single evaluation process. Based on human-examined prompts and QA pairs, UmniBench leverages UMM itself to evaluate its generation and editing ability with its understanding ability. This simple but effective paradigm allows comprehensive evaluation of UMMs. Second, UmniBench covers 13 major domains and more than 200 concepts, ensuring a thorough inspection of UMMs. Moreover, UmniBench can also decouple and separately evaluate understanding, generation, and editing abilities, providing a fine-grained assessment. Based on UmniBench, we benchmark 24 popular models, including both UMMs and single-ability large models. We hope this benchmark provides a more comprehensive and objective view of unified models and logistical support for improving the performance of the community model.
Unveiling Mode Connectivity in Graph Neural Networks
Feb 18, 2025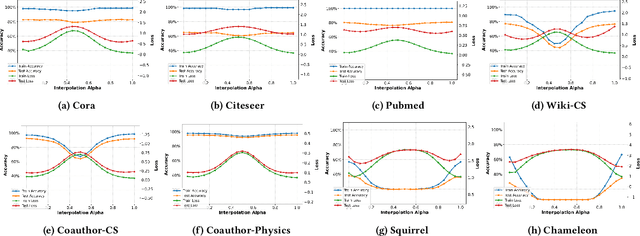
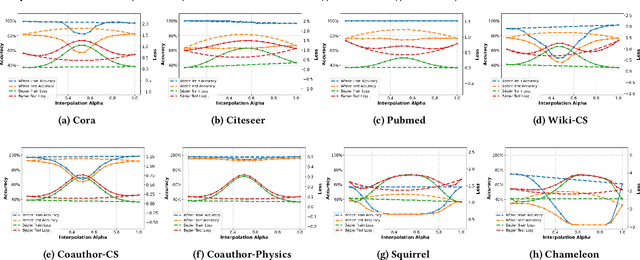
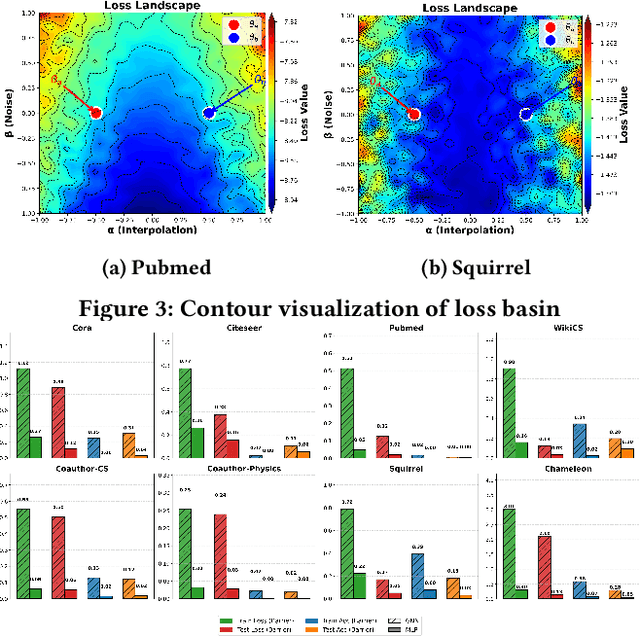
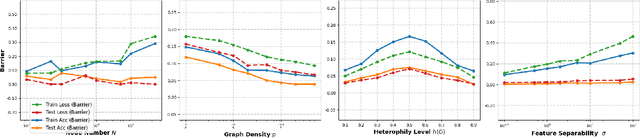
A fundamental challenge in understanding graph neural networks (GNNs) lies in characterizing their optimization dynamics and loss landscape geometry, critical for improving interpretability and robustness. While mode connectivity, a lens for analyzing geometric properties of loss landscapes has proven insightful for other deep learning architectures, its implications for GNNs remain unexplored. This work presents the first investigation of mode connectivity in GNNs. We uncover that GNNs exhibit distinct non-linear mode connectivity, diverging from patterns observed in fully-connected networks or CNNs. Crucially, we demonstrate that graph structure, rather than model architecture, dominates this behavior, with graph properties like homophily correlating with mode connectivity patterns. We further establish a link between mode connectivity and generalization, proposing a generalization bound based on loss barriers and revealing its utility as a diagnostic tool. Our findings further bridge theoretical insights with practical implications: they rationalize domain alignment strategies in graph learning and provide a foundation for refining GNN training paradigms.
AutoG: Towards automatic graph construction from tabular data
Jan 25, 2025



Recent years have witnessed significant advancements in graph machine learning (GML), with its applications spanning numerous domains. However, the focus of GML has predominantly been on developing powerful models, often overlooking a crucial initial step: constructing suitable graphs from common data formats, such as tabular data. This construction process is fundamental to applying graphbased models, yet it remains largely understudied and lacks formalization. Our research aims to address this gap by formalizing the graph construction problem and proposing an effective solution. We identify two critical challenges to achieve this goal: 1. The absence of dedicated datasets to formalize and evaluate the effectiveness of graph construction methods, and 2. Existing automatic construction methods can only be applied to some specific cases, while tedious human engineering is required to generate high-quality graphs. To tackle these challenges, we present a two-fold contribution. First, we introduce a set of datasets to formalize and evaluate graph construction methods. Second, we propose an LLM-based solution, AutoG, automatically generating high-quality graph schemas without human intervention. The experimental results demonstrate that the quality of constructed graphs is critical to downstream task performance, and AutoG can generate high-quality graphs that rival those produced by human experts.
One Model for One Graph: A New Perspective for Pretraining with Cross-domain Graphs
Nov 30, 2024



Graph Neural Networks (GNNs) have emerged as a powerful tool to capture intricate network patterns, achieving success across different domains. However, existing GNNs require careful domain-specific architecture designs and training from scratch on each dataset, leading to an expertise-intensive process with difficulty in generalizing across graphs from different domains. Therefore, it can be hard for practitioners to infer which GNN model can generalize well to graphs from their domains. To address this challenge, we propose a novel cross-domain pretraining framework, "one model for one graph," which overcomes the limitations of previous approaches that failed to use a single GNN to capture diverse graph patterns across domains with significant gaps. Specifically, we pretrain a bank of expert models, with each one corresponding to a specific dataset. When inferring to a new graph, gating functions choose a subset of experts to effectively integrate prior model knowledge while avoiding negative transfer. Extensive experiments consistently demonstrate the superiority of our proposed method on both link prediction and node classification tasks.
Improving Causal Reasoning in Large Language Models: A Survey
Oct 22, 2024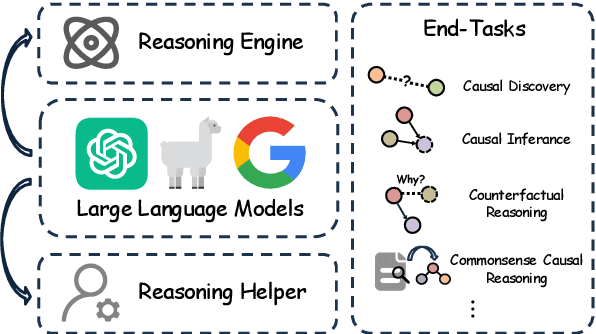
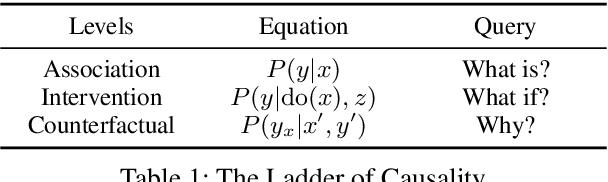


Causal reasoning (CR) is a crucial aspect of intelligence, essential for problem-solving, decision-making, and understanding the world. While large language models (LLMs) can generate rationales for their outputs, their ability to reliably perform causal reasoning remains uncertain, often falling short in tasks requiring a deep understanding of causality. In this survey, we provide a comprehensive review of research aimed at enhancing LLMs for causal reasoning. We categorize existing methods based on the role of LLMs: either as reasoning engines or as helpers providing knowledge or data to traditional CR methods, followed by a detailed discussion of the methodologies in each category. We then evaluate the performance of LLMs on various causal reasoning tasks, providing key findings and in-depth analysis. Finally, we provide insights from current studies and highlight promising directions for future research. We aim for this work to serve as a comprehensive resource, fostering further advancements in causal reasoning with LLMs. Resources are available at https://github.com/chendl02/Awesome-LLM-causal-reasoning.
Learning on Graphs with Large Language Models(LLMs): A Deep Dive into Model Robustness
Jul 16, 2024



Large Language Models (LLMs) have demonstrated remarkable performance across various natural language processing tasks. Recently, several LLMs-based pipelines have been developed to enhance learning on graphs with text attributes, showcasing promising performance. However, graphs are well-known to be susceptible to adversarial attacks and it remains unclear whether LLMs exhibit robustness in learning on graphs. To address this gap, our work aims to explore the potential of LLMs in the context of adversarial attacks on graphs. Specifically, we investigate the robustness against graph structural and textual perturbations in terms of two dimensions: LLMs-as-Enhancers and LLMs-as-Predictors. Through extensive experiments, we find that, compared to shallow models, both LLMs-as-Enhancers and LLMs-as-Predictors offer superior robustness against structural and textual attacks.Based on these findings, we carried out additional analyses to investigate the underlying causes. Furthermore, we have made our benchmark library openly available to facilitate quick and fair evaluations, and to encourage ongoing innovative research in this field.
A Pure Transformer Pretraining Framework on Text-attributed Graphs
Jun 19, 2024



Pretraining plays a pivotal role in acquiring generalized knowledge from large-scale data, achieving remarkable successes as evidenced by large models in CV and NLP. However, progress in the graph domain remains limited due to fundamental challenges such as feature heterogeneity and structural heterogeneity. Recently, increasing efforts have been made to enhance node feature quality with Large Language Models (LLMs) on text-attributed graphs (TAGs), demonstrating superiority to traditional bag-of-words or word2vec techniques. These high-quality node features reduce the previously critical role of graph structure, resulting in a modest performance gap between Graph Neural Networks (GNNs) and structure-agnostic Multi-Layer Perceptrons (MLPs). Motivated by this, we introduce a feature-centric pretraining perspective by treating graph structure as a prior and leveraging the rich, unified feature space to learn refined interaction patterns that generalizes across graphs. Our framework, Graph Sequence Pretraining with Transformer (GSPT), samples node contexts through random walks and employs masked feature reconstruction to capture pairwise proximity in the LLM-unified feature space using a standard Transformer. By utilizing unified text representations rather than varying structures, our framework achieves significantly better transferability among graphs within the same domain. GSPT can be easily adapted to both node classification and link prediction, demonstrating promising empirical success on various datasets.
Text-space Graph Foundation Models: Comprehensive Benchmarks and New Insights
Jun 15, 2024



Given the ubiquity of graph data and its applications in diverse domains, building a Graph Foundation Model (GFM) that can work well across different graphs and tasks with a unified backbone has recently garnered significant interests. A major obstacle to achieving this goal stems from the fact that graphs from different domains often exhibit diverse node features. Inspired by multi-modal models that align different modalities with natural language, the text has recently been adopted to provide a unified feature space for diverse graphs. Despite the great potential of these text-space GFMs, current research in this field is hampered by two problems. First, the absence of a comprehensive benchmark with unified problem settings hinders a clear understanding of the comparative effectiveness and practical value of different text-space GFMs. Second, there is a lack of sufficient datasets to thoroughly explore the methods' full potential and verify their effectiveness across diverse settings. To address these issues, we conduct a comprehensive benchmark providing novel text-space datasets and comprehensive evaluation under unified problem settings. Empirical results provide new insights and inspire future research directions. Our code and data are publicly available from \url{https://github.com/CurryTang/TSGFM}.