 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Class of Dual-Frame Passively-Tilting Fully-Actuated Hexacopter
Nov 19, 2025



This paper proposed a novel fully-actuated hexacopter. It features a dual-frame passive tilting structure and achieves independent control of translational motion and attitude with minimal actuators. Compared to previous fully-actuated UAVs, it liminates internal force cancellation, resulting in higher flight efficiency and endurance under equivalent payload conditions. Based on the dynamic model of fully-actuated hexacopter, a full-actuation controller is designed to achieve efficient and stable control. Finally, simulation is conducted, validating the superior fully-actuated motion capability of fully-actuated hexacopter and the effectiveness of the proposed control strategy.
Fine-Grained Iterative Adversarial Attacks with Limited Computation Budget
Oct 30, 2025This work tackles a critical challenge in AI safety research under limited compute: given a fixed computation budget, how can one maximize the strength of iterative adversarial attacks? Coarsely reducing the number of attack iterations lowers cost but substantially weakens effectiveness. To fulfill the attainable attack efficacy within a constrained budget, we propose a fine-grained control mechanism that selectively recomputes layer activations across both iteration-wise and layer-wise levels. Extensive experiments show that our method consistently outperforms existing baselines at equal cost. Moreover, when integrated into adversarial training, it attains comparable performance with only 30% of the original budget.
Decoding Memories: An Efficient Pipeline for Self-Consistency Hallucination Detection
Aug 28, 2025Large language models (LLMs) have demonstrated impressive performance in both research and real-world applications, but they still struggle with hallucination. Existing hallucination detection methods often perform poorly on sentence-level generation or rely heavily on domain-specific knowledge. While self-consistency approaches help address these limitations, they incur high computational costs due to repeated generation. In this paper, we conduct the first study on identifying redundancy in self-consistency methods, manifested as shared prefix tokens across generations, and observe that non-exact-answer tokens contribute minimally to the semantic content. Based on these insights, we propose a novel Decoding Memory Pipeline (DMP) that accelerates generation through selective inference and annealed decoding. Being orthogonal to the model, dataset, decoding strategy, and self-consistency baseline, our DMP consistently improves the efficiency of multi-response generation and holds promise for extension to alignment and reasoning tasks. Extensive experiments show that our method achieves up to a 3x speedup without sacrificing AUROC performance.
Traffic Engineering in Large-scale Networks with Generalizable Graph Neural Networks
Mar 31, 2025



Traffic engineering (TE) in large-scale computer networks has become a fundamental yet challenging problem, owing to the swift growth of global-scale cloud wide-area networks or backbone low-Earth-orbit satellite constellations. To address the scalability issue of traditional TE algorithms, learning-based approaches have been proposed, showing potential of significant efficiency improvement over state-of-the-art methods. Nevertheless, the intrinsic limitations of existing learning-based methods hinder their practical application: they are not generalizable across diverse topologies and network conditions, incur excessive training overhead, and do not respect link capacities by default. This paper proposes TELGEN, a novel TE algorithm that learns to solve TE problems efficiently in large-scale networks, while achieving superior generalizability across diverse network conditions. TELGEN is based on the novel idea of transforming the problem of "predicting the optimal TE solution" into "predicting the optimal TE algorithm", which enables TELGEN to learn and efficiently approximate the end-to-end solving process of classical optimal TE algorithms. The learned algorithm is agnostic to the exact network topology or traffic patterns, and can efficiently solve TE problems given arbitrary inputs and generalize well to unseen topologies and demands. We trained and evaluated TELGEN on random and real-world networks with up to 5000 nodes and 106 links. TELGEN achieved less than 3% optimality gap while ensuring feasibility in all cases, even when the test network had up to 20x more nodes than the largest in training. It also saved up to 84% solving time than classical optimal solver, and could reduce training time per epoch and solving time by 2-4 orders of magnitude than latest learning algorithms on the largest networks.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025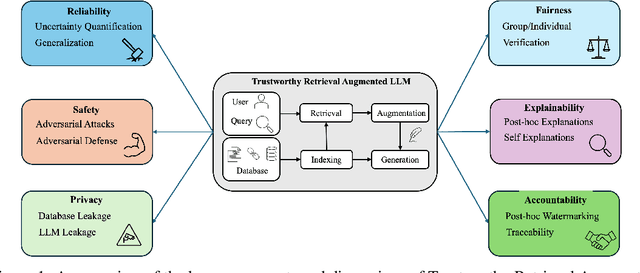
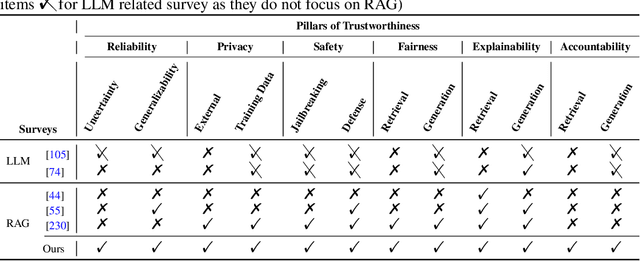


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Online Robot Motion Planning Methodology Guided by Group Social Proxemics Feature
Feb 07, 2025



Nowadays robot is supposed to demonstrate human-like perception, reasoning and behavior pattern in social or service application. However, most of the existing motion planning methods are incompatible with above requirement. A potential reason is that the existing navigation algorithms usually intend to treat people as another kind of obstacle, and hardly take the social principle or awareness into consideration. In this paper, we attempt to model the proxemics of group and blend it into the scenario perception and navigation of robot. For this purpose, a group clustering method considering both social relevance and spatial confidence is introduced. It can enable robot to identify individuals and divide them into groups. Next, we propose defining the individual proxemics within magnetic dipole model, and further established the group proxemics and scenario map through vector-field superposition. On the basis of the group clustering and proxemics modeling, we present the method to obtain the optimal observation positions (OOPs) of group. Once the OOPs grid and scenario map are established, a heuristic path is employed to generate path that guide robot cruising among the groups for interactive purpose. A series of experiments are conducted to validate the proposed methodology on the practical robot, the results have demonstrated that our methodology has achieved promising performance on group recognition accuracy and path-generation efficiency. This concludes that the group awareness evolved as an important module to make robot socially behave in the practical scenario.
Boosting Adversarial Robustness and Generalization with Structural Prior
Feb 02, 2025



This work investigates a novel approach to boost adversarial robustness and generalization by incorporating structural prior into the design of deep learning models. Specifically, our study surprisingly reveals that existing dictionary learning-inspired convolutional neural networks (CNNs) provide a false sense of security against adversarial attacks. To address this, we propose Elastic Dictionary Learning Networks (EDLNets), a novel ResNet architecture that significantly enhances adversarial robustness and generalization. This novel and effective approach is supported by a theoretical robustness analysis using influence functions. Moreover, extensive and reliable experiments demonstrate consistent and significant performance improvement on open robustness leaderboards such as RobustBench, surpassing state-of-the-art baselines. To the best of our knowledge, this is the first work to discover and validate that structural prior can reliably enhance deep learning robustness under strong adaptive attacks, unveiling a promising direction for future research.
Certified Robustness for Deep Equilibrium Models via Serialized Random Smoothing
Nov 01, 2024



Implicit models such as Deep Equilibrium Models (DEQs) have emerged as promising alternative approaches for building deep neural networks. Their certified robustness has gained increasing research attention due to security concerns. Existing certified defenses for DEQs employing deterministic certification methods such as interval bound propagation and Lipschitz-bounds can not certify on large-scale datasets. Besides, they are also restricted to specific forms of DEQs. In this paper, we provide the first randomized smoothing certified defense for DEQs to solve these limitations. Our study reveals that simply applying randomized smoothing to certify DEQs provides certified robustness generalized to large-scale datasets but incurs extremely expensive computation costs. To reduce computational redundancy, we propose a novel Serialized Randomized Smoothing (SRS) approach that leverages historical information. Additionally, we derive a new certified radius estimation for SRS to theoretically ensure the correctness of our algorithm. Extensive experiments and ablation studies on image recognition demonstrate that our algorithm can significantly accelerate the certification of DEQs by up to 7x almost without sacrificing the certified accuracy. Our code is available at https://github.com/WeizhiGao/Serialized-Randomized-Smoothing.
ProTransformer: Robustify Transformers via Plug-and-Play Paradigm
Oct 30, 2024



Transformer-based architectures have dominated various areas of machine learning in recent years. In this paper, we introduce a novel robust attention mechanism designed to enhance the resilience of transformer-based architectures. Crucially, this technique can be integrated into existing transformers as a plug-and-play layer, improving their robustness without the need for additional training or fine-tuning. Through comprehensive experiments and ablation studies, we demonstrate that our ProTransformer significantly enhances the robustness of transformer models across a variety of prediction tasks, attack mechanisms, backbone architectures, and data domains. Notably, without further fine-tuning, the ProTransformer consistently improves the performance of vanilla transformers by 19.5%, 28.3%, 16.1%, and 11.4% for BERT, ALBERT, DistilBERT, and RoBERTa, respectively, under the classical TextFooler attack. Furthermore, ProTransformer shows promising resilience in large language models (LLMs) against prompting-based attacks, improving the performance of T5 and LLaMA by 24.8% and 17.8%, respectively, and enhancing Vicuna by an average of 10.4% against the Jailbreaking attack. Beyond the language domain, ProTransformer also demonstrates outstanding robustness in both vision and graph domains.
Haste Makes Waste: A Simple Approach for Scaling Graph Neural Networks
Oct 07, 2024Graph neural networks (GNNs) have demonstrated remarkable success in graph representation learning, and various sampling approaches have been proposed to scale GNNs to applications with large-scale graphs. A class of promising GNN training algorithms take advantage of historical embeddings to reduce the computation and memory cost while maintaining the model expressiveness of GNNs. However, they incur significant computation bias due to the stale feature history. In this paper, we provide a comprehensive analysis of their staleness and inferior performance on large-scale problems. Motivated by our discoveries, we propose a simple yet highly effective training algorithm (REST) to effectively reduce feature staleness, which leads to significantly improved performance and convergence across varying batch sizes. The proposed algorithm seamlessly integrates with existing solutions, boasting easy implementation, while comprehensive experiments underscore its superior performance and efficiency on large-scale benchmarks. Specifically, our improvements to state-of-the-art historical embedding methods result in a 2.7% and 3.6% performance enhancement on the ogbn-papers100M and ogbn-products dataset respectively, accompanied by notably accelerated convergence.