 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic Engineering in Large-scale Networks with Generalizable Graph Neural Networks
Mar 31, 2025



Traffic engineering (TE) in large-scale computer networks has become a fundamental yet challenging problem, owing to the swift growth of global-scale cloud wide-area networks or backbone low-Earth-orbit satellite constellations. To address the scalability issue of traditional TE algorithms, learning-based approaches have been proposed, showing potential of significant efficiency improvement over state-of-the-art methods. Nevertheless, the intrinsic limitations of existing learning-based methods hinder their practical application: they are not generalizable across diverse topologies and network conditions, incur excessive training overhead, and do not respect link capacities by default. This paper proposes TELGEN, a novel TE algorithm that learns to solve TE problems efficiently in large-scale networks, while achieving superior generalizability across diverse network conditions. TELGEN is based on the novel idea of transforming the problem of "predicting the optimal TE solution" into "predicting the optimal TE algorithm", which enables TELGEN to learn and efficiently approximate the end-to-end solving process of classical optimal TE algorithms. The learned algorithm is agnostic to the exact network topology or traffic patterns, and can efficiently solve TE problems given arbitrary inputs and generalize well to unseen topologies and demands. We trained and evaluated TELGEN on random and real-world networks with up to 5000 nodes and 106 links. TELGEN achieved less than 3% optimality gap while ensuring feasibility in all cases, even when the test network had up to 20x more nodes than the largest in training. It also saved up to 84% solving time than classical optimal solver, and could reduce training time per epoch and solving time by 2-4 orders of magnitude than latest learning algorithms on the largest networks.
Rank-Based Modeling for Universal Packets Compression in Multi-Modal Communications
Mar 24, 2025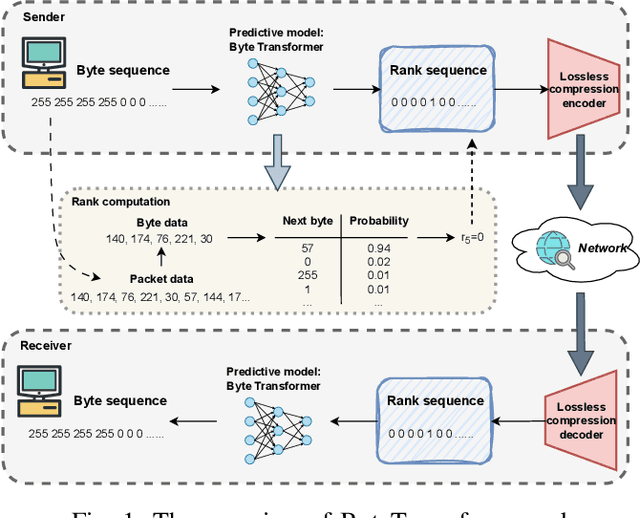
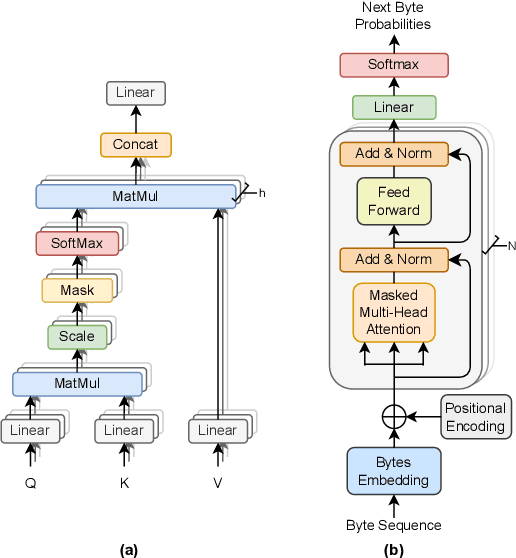
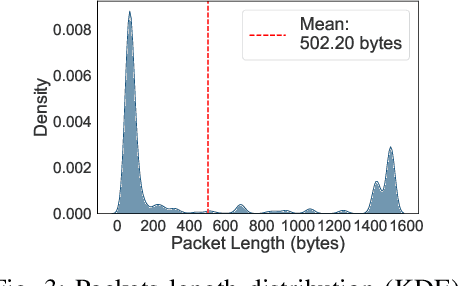
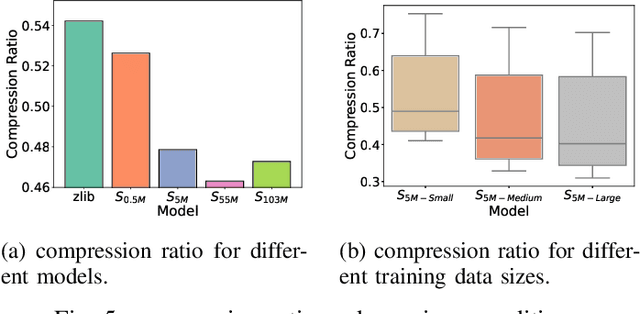
The rapid increase in networked systems and data transmission requires advanced data compression solutions to optimize bandwidth utilization and enhance network performance. This study introduces a novel byte-level predictive model using Transformer architecture, capable of handling the redundancy and diversity of data types in network traffic as byte sequences. Unlike traditional methods that require separate compressors for different data types, this unified approach sets new benchmarks and simplifies predictive modeling across various data modalities such as video, audio, images, and text, by processing them at the byte level. This is achieved by predicting subsequent byte probability distributions, encoding them into a sparse rank sequence using lossless entropy coding, and significantly reducing both data size and entropy. Experimental results show that our model achieves compression ratios below 50%, while offering models of various sizes tailored for different communication devices. Additionally, we successfully deploy these models on a range of edge devices and servers, demonstrating their practical applicability and effectiveness in real-world network scenarios. This approach significantly enhances data throughput and reduces bandwidth demands, making it particularly valuable in resource-constrained environments like the Internet of Things sensor networks.
Efficient Large Language Models Fine-Tuning On Graphs
Dec 07, 2023Learning from Text-Attributed Graphs (TAGs) has attracted significant attention due to its wide range of real-world applications. The rapid evolution of large language models (LLMs) has revolutionized the way we process textual data, which indicates a strong potential to replace shallow text embedding generally used in Graph Neural Networks (GNNs). However, we find that existing LLM approaches that exploit text information in graphs suffer from inferior computation and data efficiency. In this work, we introduce a novel and efficient approach for the end-to-end fine-tuning of Large Language Models (LLMs) on TAGs, named LEADING. The proposed approach maintains computation cost and memory overhead comparable to the graph-less fine-tuning of LLMs. Moreover, it transfers the rick knowledge in LLMs to downstream graph learning tasks effectively with limited labeled data in semi-supervised learning. Its superior computation and data efficiency are demonstrated through comprehensive experiments, offering a promising solution for a wide range of LLMs and graph learning tasks on TAGs.