 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank-Based Modeling for Universal Packets Compression in Multi-Modal Communications
Mar 24, 2025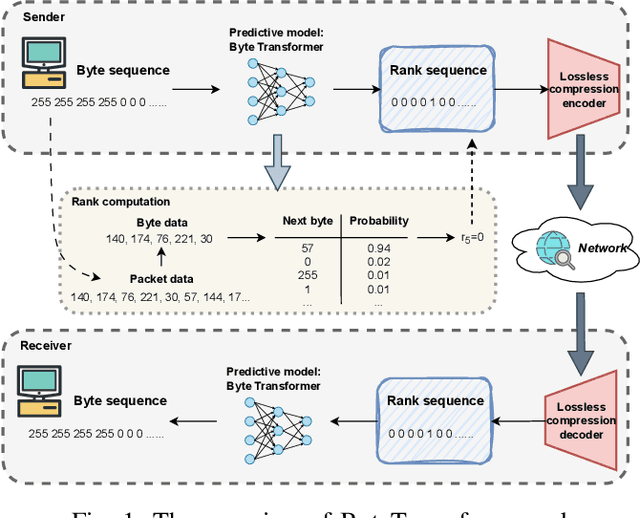
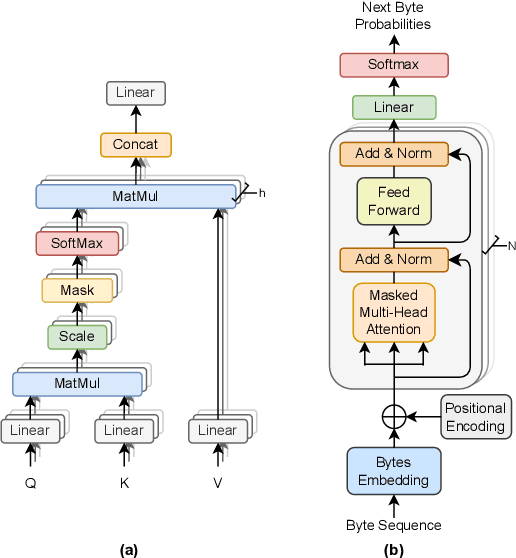
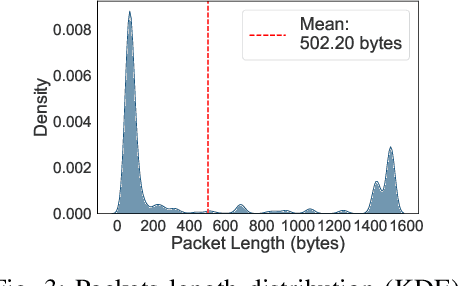
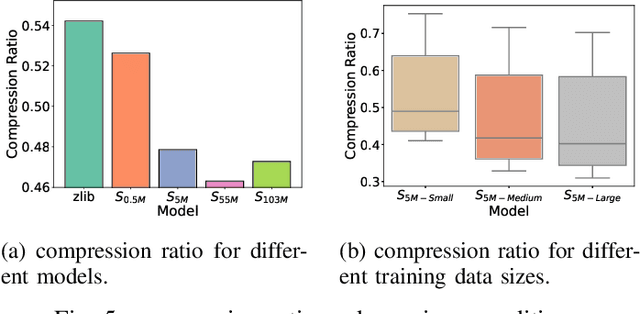
The rapid increase in networked systems and data transmission requires advanced data compression solutions to optimize bandwidth utilization and enhance network performance. This study introduces a novel byte-level predictive model using Transformer architecture, capable of handling the redundancy and diversity of data types in network traffic as byte sequences. Unlike traditional methods that require separate compressors for different data types, this unified approach sets new benchmarks and simplifies predictive modeling across various data modalities such as video, audio, images, and text, by processing them at the byte level. This is achieved by predicting subsequent byte probability distributions, encoding them into a sparse rank sequence using lossless entropy coding, and significantly reducing both data size and entropy. Experimental results show that our model achieves compression ratios below 50%, while offering models of various sizes tailored for different communication devices. Additionally, we successfully deploy these models on a range of edge devices and servers, demonstrating their practical applicability and effectiveness in real-world network scenarios. This approach significantly enhances data throughput and reduces bandwidth demands, making it particularly valuable in resource-constrained environments like the Internet of Things sensor networks.
MetaMorphosis: Task-oriented Privacy Cognizant Feature Generation for Multi-task Learning
May 13, 2023With the growth of computer vision applications, deep learning, and edge computing contribute to ensuring practical collaborative intelligence (CI) by distributing the workload among edge devices and the cloud. However, running separate single-task models on edge devices is inefficient regarding the required computational resource and time. In this context, multi-task learning allows leveraging a single deep learning model for performing multiple tasks, such as semantic segmentation and depth estimation on incoming video frames. This single processing pipeline generates common deep features that are shared among multi-task modules. However, in a collaborative intelligence scenario, generating common deep features has two major issues. First, the deep features may inadvertently contain input information exposed to the downstream modules (violating input privacy). Second, the generated universal features expose a piece of collective information than what is intended for a certain task, in which features for one task can be utilized to perform another task (violating task privacy). This paper proposes a novel deep learning-based privacy-cognizant feature generation process called MetaMorphosis that limits inference capability to specific tasks at hand. To achieve this, we propose a channel squeeze-excitation based feature metamorphosis module, Cross-SEC, to achieve distinct attention of all tasks and a de-correlation loss function with differential-privacy to train a deep learning model that produces distinct privacy-aware features as an output for the respective tasks. With extensive experimentation on four datasets consisting of diverse images related to scene understanding and facial attributes, we show that MetaMorphosis outperforms recent adversarial learning and universal feature generation methods by guaranteeing privacy requirements in an efficient way for image and video analytics.