 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiRAG: An Incremental Retrieval Augmented Generation System for Videos
Apr 18, 2024



Retrieval augmented generation (RAG) systems combine the strengths of language generation and information retrieval to power many real-world applications like chatbots. Use of RAG for combined understanding of multimodal data such as text, images and videos is appealing but two critical limitations exist: one-time, upfront capture of all content in large multimodal data as text descriptions entails high processing times, and not all information in the rich multimodal data is typically in the text descriptions. Since the user queries are not known apriori, developing a system for multimodal to text conversion and interactive querying of multimodal data is challenging. To address these limitations, we propose iRAG, which augments RAG with a novel incremental workflow to enable interactive querying of large corpus of multimodal data. Unlike traditional RAG, iRAG quickly indexes large repositories of multimodal data, and in the incremental workflow, it uses the index to opportunistically extract more details from select portions of the multimodal data to retrieve context relevant to an interactive user query. Such an incremental workflow avoids long multimodal to text conversion times, overcomes information loss issues by doing on-demand query-specific extraction of details in multimodal data, and ensures high quality of responses to interactive user queries that are often not known apriori. To the best of our knowledge, iRAG is the first system to augment RAG with an incremental workflow to support efficient interactive querying of large, real-world multimodal data. Experimental results on real-world long videos demonstrate 23x to 25x faster video to text ingestion, while ensuring that quality of responses to interactive user queries is comparable to responses from a traditional RAG where all video data is converted to text upfront before any querying.
MetaMorphosis: Task-oriented Privacy Cognizant Feature Generation for Multi-task Learning
May 13, 2023With the growth of computer vision applications, deep learning, and edge computing contribute to ensuring practical collaborative intelligence (CI) by distributing the workload among edge devices and the cloud. However, running separate single-task models on edge devices is inefficient regarding the required computational resource and time. In this context, multi-task learning allows leveraging a single deep learning model for performing multiple tasks, such as semantic segmentation and depth estimation on incoming video frames. This single processing pipeline generates common deep features that are shared among multi-task modules. However, in a collaborative intelligence scenario, generating common deep features has two major issues. First, the deep features may inadvertently contain input information exposed to the downstream modules (violating input privacy). Second, the generated universal features expose a piece of collective information than what is intended for a certain task, in which features for one task can be utilized to perform another task (violating task privacy). This paper proposes a novel deep learning-based privacy-cognizant feature generation process called MetaMorphosis that limits inference capability to specific tasks at hand. To achieve this, we propose a channel squeeze-excitation based feature metamorphosis module, Cross-SEC, to achieve distinct attention of all tasks and a de-correlation loss function with differential-privacy to train a deep learning model that produces distinct privacy-aware features as an output for the respective tasks. With extensive experimentation on four datasets consisting of diverse images related to scene understanding and facial attributes, we show that MetaMorphosis outperforms recent adversarial learning and universal feature generation methods by guaranteeing privacy requirements in an efficient way for image and video analytics.
FrameHopper: Selective Processing of Video Frames in Detection-driven Real-Time Video Analytics
Mar 22, 2022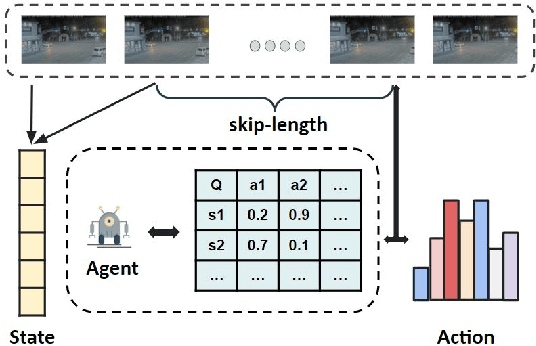
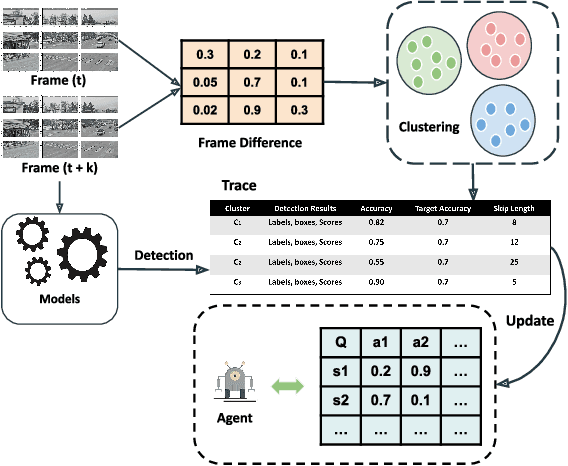
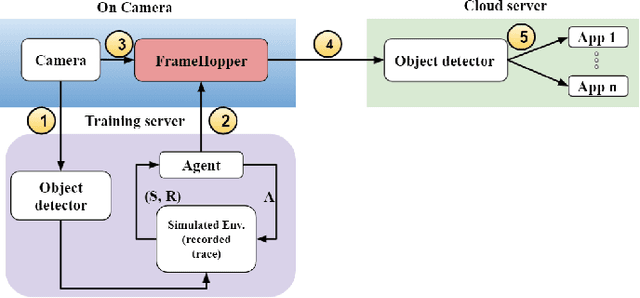

Detection-driven real-time video analytics require continuous detection of objects contained in the video frames using deep learning models like YOLOV3, EfficientDet. However, running these detectors on each and every frame in resource-constrained edge devices is computationally intensive. By taking the temporal correlation between consecutive video frames into account, we note that detection outputs tend to be overlapping in successive frames. Elimination of similar consecutive frames will lead to a negligible drop in performance while offering significant performance benefits by reducing overall computation and communication costs. The key technical questions are, therefore, (a) how to identify which frames to be processed by the object detector, and (b) how many successive frames can be skipped (called skip-length) once a frame is selected to be processed. The overall goal of the process is to keep the error due to skipping frames as small as possible. We introduce a novel error vs processing rate optimization problem with respect to the object detection task that balances between the error rate and the fraction of frames filtering. Subsequently, we propose an off-line Reinforcement Learning (RL)-based algorithm to determine these skip-lengths as a state-action policy of the RL agent from a recorded video and then deploy the agent online for live video streams. To this end, we develop FrameHopper, an edge-cloud collaborative video analytics framework, that runs a lightweight trained RL agent on the camera and passes filtered frames to the server where the object detection model runs for a set of applications. We have tested our approach on a number of live videos captured from real-life scenarios and show that FrameHopper processes only a handful of frames but produces detection results closer to the oracle solution and outperforms recent state-of-the-art solutions in most cases.
EARLIN: Early Out-of-Distribution Detection for Resource-efficient Collaborative Inference
Jun 29, 2021

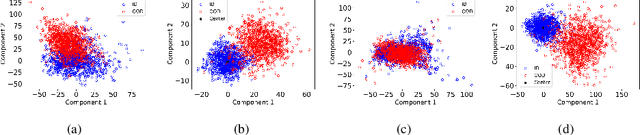
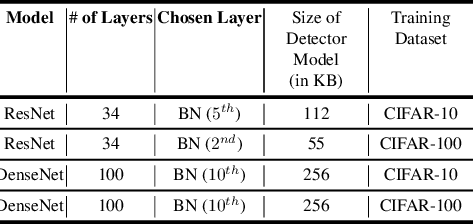
Collaborative inference enables resource-constrained edge devices to make inferences by uploading inputs (e.g., images) to a server (i.e., cloud) where the heavy deep learning models run. While this setup works cost-effectively for successful inferences, it severely underperforms when the model faces input samples on which the model was not trained (known as Out-of-Distribution (OOD) samples). If the edge devices could, at least, detect that an input sample is an OOD, that could potentially save communication and computation resources by not uploading those inputs to the server for inference workload. In this paper, we propose a novel lightweight OOD detection approach that mines important features from the shallow layers of a pretrained CNN model and detects an input sample as ID (In-Distribution) or OOD based on a distance function defined on the reduced feature space. Our technique (a) works on pretrained models without any retraining of those models, and (b) does not expose itself to any OOD dataset (all detection parameters are obtained from the ID training dataset). To this end, we develop EARLIN (EARLy OOD detection for Collaborative INference) that takes a pretrained model and partitions the model at the OOD detection layer and deploys the considerably small OOD part on an edge device and the rest on the cloud. By experimenting using real datasets and a prototype implementation, we show that our technique achieves better results than other approaches in terms of overall accuracy and cost when tested against popular OOD datasets on top of popular deep learning models pretrained on benchmark datasets.
A Lightweight ReLU-Based Feature Fusion for Aerial Scene Classification
Jun 15, 2021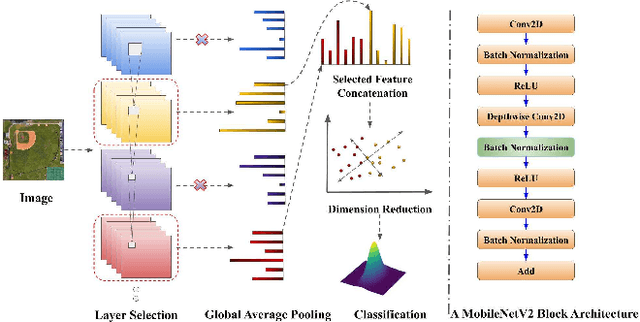

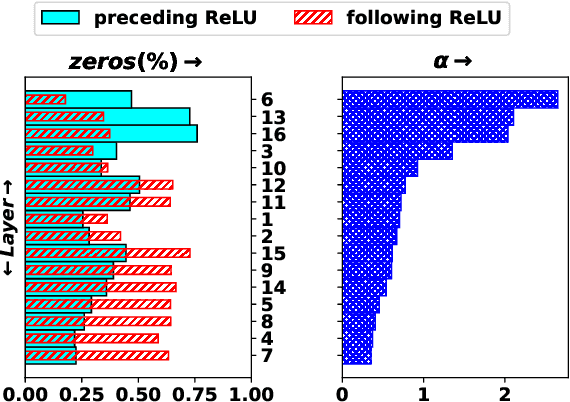
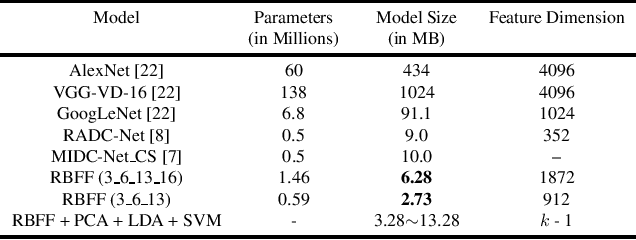
In this paper, we propose a transfer-learning based model construction technique for the aerial scene classification problem. The core of our technique is a layer selection strategy, named ReLU-Based Feature Fusion (RBFF), that extracts feature maps from a pretrained CNN-based single-object image classification model, namely MobileNetV2, and constructs a model for the aerial scene classification task. RBFF stacks features extracted from the batch normalization layer of a few selected blocks of MobileNetV2, where the candidate blocks are selected based on the characteristics of the ReLU activation layers present in those blocks. The feature vector is then compressed into a low-dimensional feature space using dimension reduction algorithms on which we train a low-cost SVM classifier for the classification of the aerial images. We validate our choice of selected features based on the significance of the extracted features with respect to our classification pipeline. RBFF remarkably does not involve any training of the base CNN model except for a few parameters for the classifier, which makes the technique very cost-effective for practical deployments. The constructed model despite being lightweight outperforms several recently proposed models in terms of accuracy for a number of aerial scene datasets.