 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrameHopper: Selective Processing of Video Frames in Detection-driven Real-Time Video Analytics
Mar 22, 2022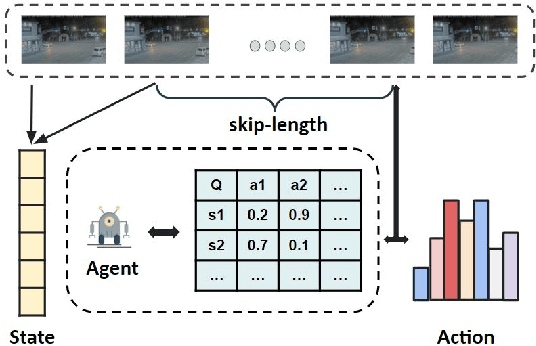
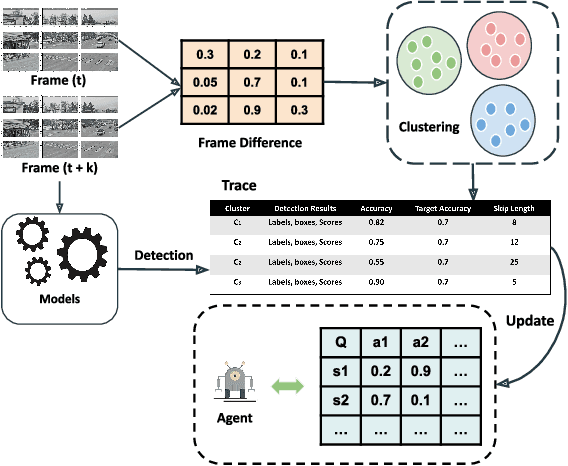
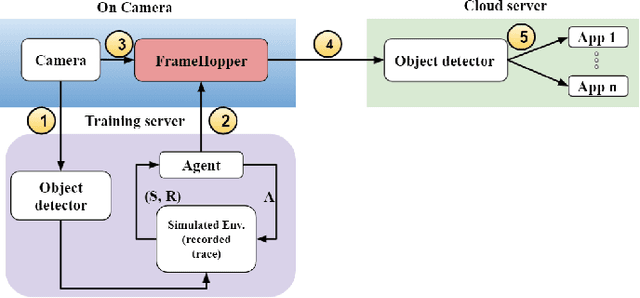

Detection-driven real-time video analytics require continuous detection of objects contained in the video frames using deep learning models like YOLOV3, EfficientDet. However, running these detectors on each and every frame in resource-constrained edge devices is computationally intensive. By taking the temporal correlation between consecutive video frames into account, we note that detection outputs tend to be overlapping in successive frames. Elimination of similar consecutive frames will lead to a negligible drop in performance while offering significant performance benefits by reducing overall computation and communication costs. The key technical questions are, therefore, (a) how to identify which frames to be processed by the object detector, and (b) how many successive frames can be skipped (called skip-length) once a frame is selected to be processed. The overall goal of the process is to keep the error due to skipping frames as small as possible. We introduce a novel error vs processing rate optimization problem with respect to the object detection task that balances between the error rate and the fraction of frames filtering. Subsequently, we propose an off-line Reinforcement Learning (RL)-based algorithm to determine these skip-lengths as a state-action policy of the RL agent from a recorded video and then deploy the agent online for live video streams. To this end, we develop FrameHopper, an edge-cloud collaborative video analytics framework, that runs a lightweight trained RL agent on the camera and passes filtered frames to the server where the object detection model runs for a set of applications. We have tested our approach on a number of live videos captured from real-life scenarios and show that FrameHopper processes only a handful of frames but produces detection results closer to the oracle solution and outperforms recent state-of-the-art solutions in most cases.
EARLIN: Early Out-of-Distribution Detection for Resource-efficient Collaborative Inference
Jun 29, 2021

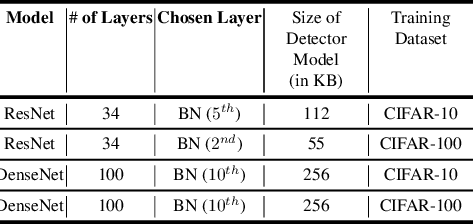
Collaborative inference enables resource-constrained edge devices to make inferences by uploading inputs (e.g., images) to a server (i.e., cloud) where the heavy deep learning models run. While this setup works cost-effectively for successful inferences, it severely underperforms when the model faces input samples on which the model was not trained (known as Out-of-Distribution (OOD) samples). If the edge devices could, at least, detect that an input sample is an OOD, that could potentially save communication and computation resources by not uploading those inputs to the server for inference workload. In this paper, we propose a novel lightweight OOD detection approach that mines important features from the shallow layers of a pretrained CNN model and detects an input sample as ID (In-Distribution) or OOD based on a distance function defined on the reduced feature space. Our technique (a) works on pretrained models without any retraining of those models, and (b) does not expose itself to any OOD dataset (all detection parameters are obtained from the ID training dataset). To this end, we develop EARLIN (EARLy OOD detection for Collaborative INference) that takes a pretrained model and partitions the model at the OOD detection layer and deploys the considerably small OOD part on an edge device and the rest on the cloud. By experimenting using real datasets and a prototype implementation, we show that our technique achieves better results than other approaches in terms of overall accuracy and cost when tested against popular OOD datasets on top of popular deep learning models pretrained on benchmark datasets.
A Lightweight ReLU-Based Feature Fusion for Aerial Scene Classification
Jun 15, 2021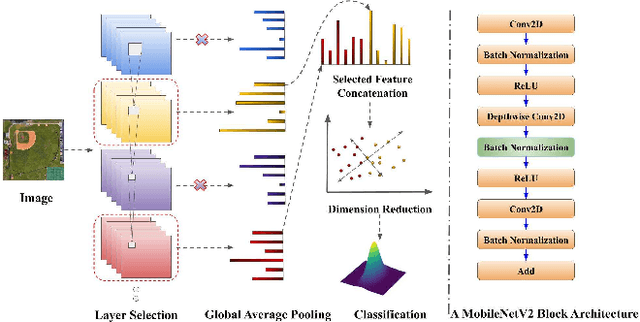

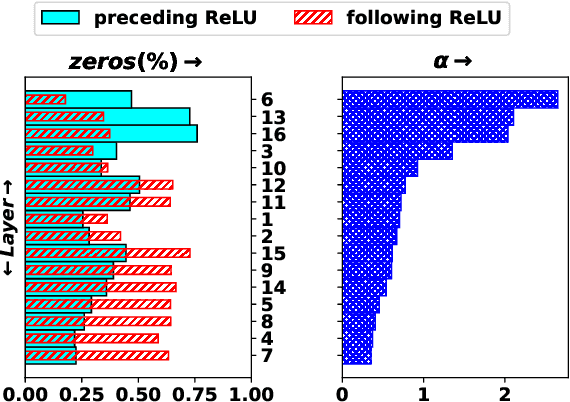
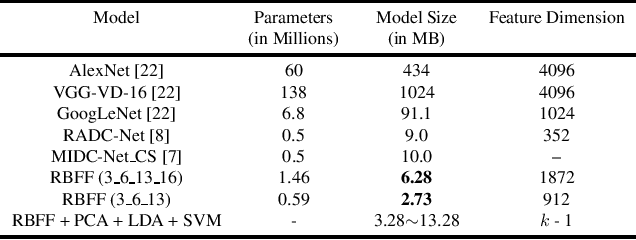
In this paper, we propose a transfer-learning based model construction technique for the aerial scene classification problem. The core of our technique is a layer selection strategy, named ReLU-Based Feature Fusion (RBFF), that extracts feature maps from a pretrained CNN-based single-object image classification model, namely MobileNetV2, and constructs a model for the aerial scene classification task. RBFF stacks features extracted from the batch normalization layer of a few selected blocks of MobileNetV2, where the candidate blocks are selected based on the characteristics of the ReLU activation layers present in those blocks. The feature vector is then compressed into a low-dimensional feature space using dimension reduction algorithms on which we train a low-cost SVM classifier for the classification of the aerial images. We validate our choice of selected features based on the significance of the extracted features with respect to our classification pipeline. RBFF remarkably does not involve any training of the base CNN model except for a few parameters for the classifier, which makes the technique very cost-effective for practical deployments. The constructed model despite being lightweight outperforms several recently proposed models in terms of accuracy for a number of aerial scene datasets.
Neural Network Based Undersampling Techniques
Aug 18, 2019



Class imbalance problem is commonly faced while developing machine learning models for real-life issues. Due to this problem, the fitted model tends to be biased towards the majority class data, which leads to lower precision, recall, AUC, F1, G-mean score. Several researches have been done to tackle this problem, most of which employed resampling, i.e. oversampling and undersampling techniques to bring the required balance in the data. In this paper, we propose neural network based algorithms for undersampling. Then we resampled several class imbalanced data using our algorithms and also some other popular resampling techniques. Afterwards we classified these undersampled data using some common classifier. We found out that our resampling approaches outperform most other resampling techniques in terms of both AUC, F1 and G-mean score.