 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrameHopper: Selective Processing of Video Frames in Detection-driven Real-Time Video Analytics
Paper and Code
Mar 22, 2022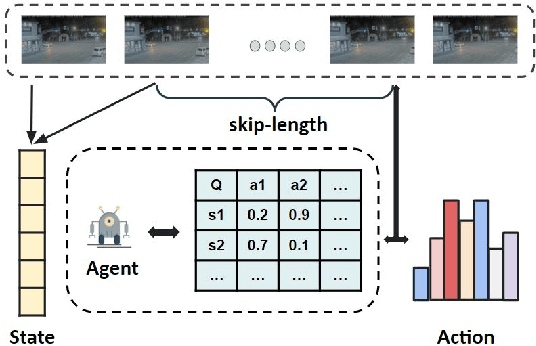
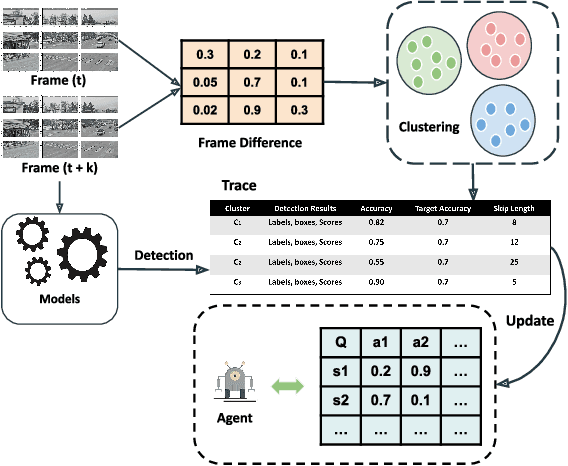
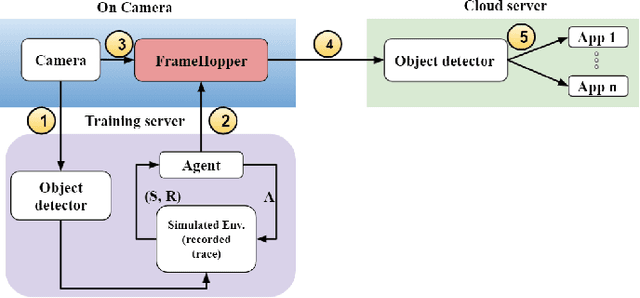

Detection-driven real-time video analytics require continuous detection of objects contained in the video frames using deep learning models like YOLOV3, EfficientDet. However, running these detectors on each and every frame in resource-constrained edge devices is computationally intensive. By taking the temporal correlation between consecutive video frames into account, we note that detection outputs tend to be overlapping in successive frames. Elimination of similar consecutive frames will lead to a negligible drop in performance while offering significant performance benefits by reducing overall computation and communication costs. The key technical questions are, therefore, (a) how to identify which frames to be processed by the object detector, and (b) how many successive frames can be skipped (called skip-length) once a frame is selected to be processed. The overall goal of the process is to keep the error due to skipping frames as small as possible. We introduce a novel error vs processing rate optimization problem with respect to the object detection task that balances between the error rate and the fraction of frames filtering. Subsequently, we propose an off-line Reinforcement Learning (RL)-based algorithm to determine these skip-lengths as a state-action policy of the RL agent from a recorded video and then deploy the agent online for live video streams. To this end, we develop FrameHopper, an edge-cloud collaborative video analytics framework, that runs a lightweight trained RL agent on the camera and passes filtered frames to the server where the object detection model runs for a set of applications. We have tested our approach on a number of live videos captured from real-life scenarios and show that FrameHopper processes only a handful of frames but produces detection results closer to the oracle solution and outperforms recent state-of-the-art solutions in most cases.