 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Alignment of Medical Vision-Language Models for Grounded Radiology Report Generation
Dec 18, 2025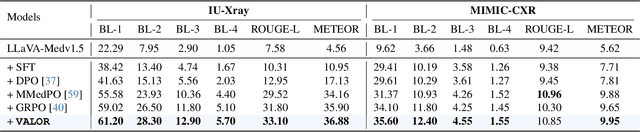
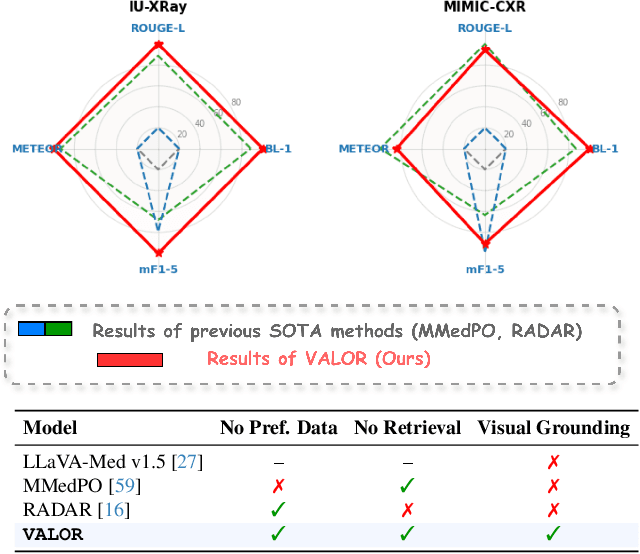
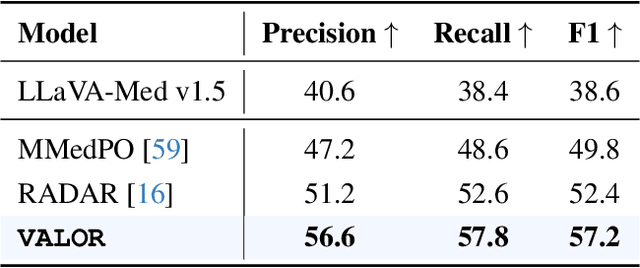
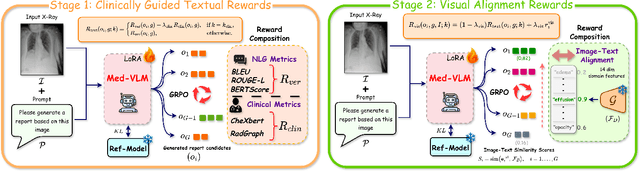
Radiology Report Generation (RRG) is a critical step toward automating healthcare workflows, facilitating accurate patient assessments, and reducing the workload of medical professionals. Despite recent progress in Large Medical Vision-Language Models (Med-VLMs), generating radiology reports that are both visually grounded and clinically accurate remains a significant challenge. Existing approaches often rely on large labeled corpora for pre-training, costly task-specific preference data, or retrieval-based methods. However, these strategies do not adequately mitigate hallucinations arising from poor cross-modal alignment between visual and linguistic representations. To address these limitations, we propose VALOR:Visual Alignment of Medical Vision-Language Models for GrOunded Radiology Report Generation. Our method introduces a reinforcement learning-based post-alignment framework utilizing Group-Relative Proximal Optimization (GRPO). The training proceeds in two stages: (1) improving the Med-VLM with textual rewards to encourage clinically precise terminology, and (2) aligning the vision projection module of the textually grounded model with disease findings, thereby guiding attention toward image re gions most relevant to the diagnostic task. Extensive experiments on multiple benchmarks demonstrate that VALOR substantially improves factual accuracy and visual grounding, achieving significant performance gains over state-of-the-art report generation methods.
iRAG: An Incremental Retrieval Augmented Generation System for Videos
Apr 18, 2024



Retrieval augmented generation (RAG) systems combine the strengths of language generation and information retrieval to power many real-world applications like chatbots. Use of RAG for combined understanding of multimodal data such as text, images and videos is appealing but two critical limitations exist: one-time, upfront capture of all content in large multimodal data as text descriptions entails high processing times, and not all information in the rich multimodal data is typically in the text descriptions. Since the user queries are not known apriori, developing a system for multimodal to text conversion and interactive querying of multimodal data is challenging. To address these limitations, we propose iRAG, which augments RAG with a novel incremental workflow to enable interactive querying of large corpus of multimodal data. Unlike traditional RAG, iRAG quickly indexes large repositories of multimodal data, and in the incremental workflow, it uses the index to opportunistically extract more details from select portions of the multimodal data to retrieve context relevant to an interactive user query. Such an incremental workflow avoids long multimodal to text conversion times, overcomes information loss issues by doing on-demand query-specific extraction of details in multimodal data, and ensures high quality of responses to interactive user queries that are often not known apriori. To the best of our knowledge, iRAG is the first system to augment RAG with an incremental workflow to support efficient interactive querying of large, real-world multimodal data. Experimental results on real-world long videos demonstrate 23x to 25x faster video to text ingestion, while ensuring that quality of responses to interactive user queries is comparable to responses from a traditional RAG where all video data is converted to text upfront before any querying.
Deep Video Codec Control
Sep 16, 2023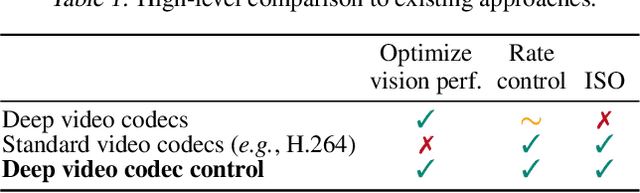
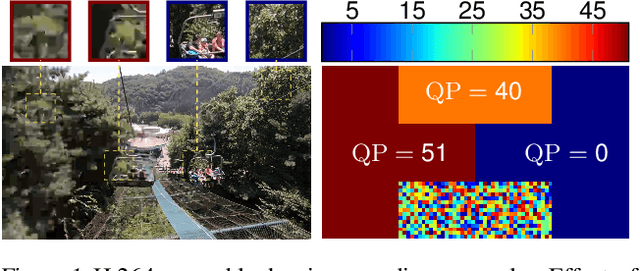
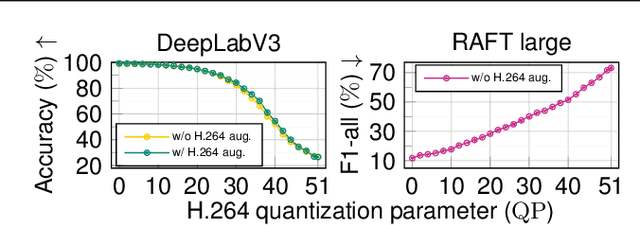
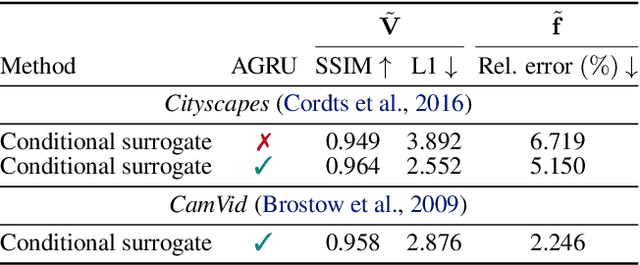
Lossy video compression is commonly used when transmitting and storing video data. Unified video codecs (e.g., H.264 or H.265) remain the de facto standard, despite the availability of advanced (neural) compression approaches. Transmitting videos in the face of dynamic network bandwidth conditions requires video codecs to adapt to vastly different compression strengths. Rate control modules augment the codec's compression such that bandwidth constraints are satisfied and video distortion is minimized. While, both standard video codes and their rate control modules are developed to minimize video distortion w.r.t. human quality assessment, preserving the downstream performance of deep vision models is not considered. In this paper, we present the first end-to-end learnable deep video codec control considering both bandwidth constraints and downstream vision performance, while not breaking existing standardization. We demonstrate for two common vision tasks (semantic segmentation and optical flow estimation) and on two different datasets that our deep codec control better preserves downstream performance than using 2-pass average bit rate control while meeting dynamic bandwidth constraints and adhering to standardizations.
Differentiable JPEG: The Devil is in the Details
Sep 13, 2023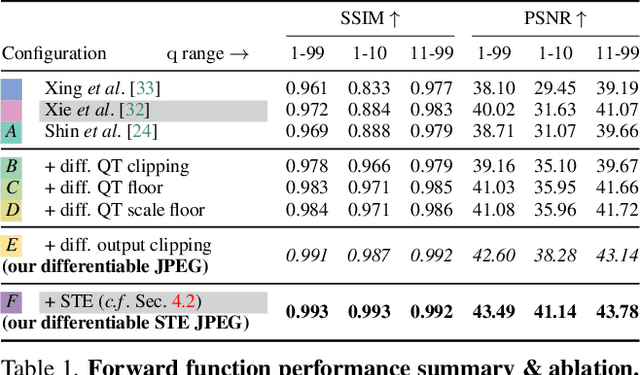
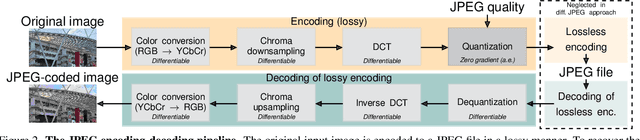
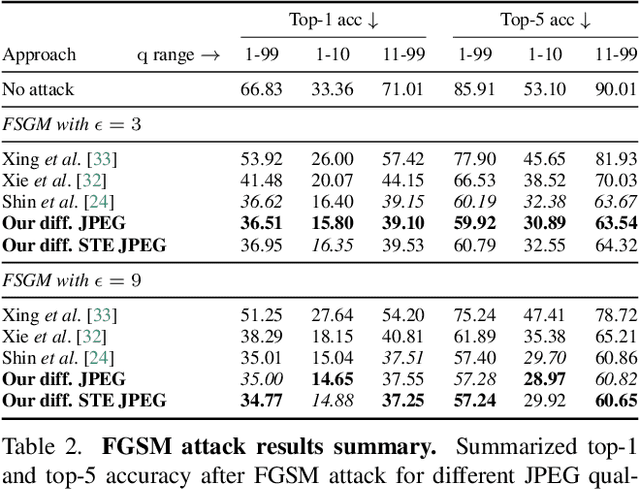

JPEG remains one of the most widespread lossy image coding methods. However, the non-differentiable nature of JPEG restricts the application in deep learning pipelines. Several differentiable approximations of JPEG have recently been proposed to address this issue. This paper conducts a comprehensive review of existing diff. JPEG approaches and identifies critical details that have been missed by previous methods. To this end, we propose a novel diff. JPEG approach, overcoming previous limitations. Our approach is differentiable w.r.t. the input image, the JPEG quality, the quantization tables, and the color conversion parameters. We evaluate the forward and backward performance of our diff. JPEG approach against existing methods. Additionally, extensive ablations are performed to evaluate crucial design choices. Our proposed diff. JPEG resembles the (non-diff.) reference implementation best, significantly surpassing the recent-best diff. approach by $3.47$dB (PSNR) on average. For strong compression rates, we can even improve PSNR by $9.51$dB. Strong adversarial attack results are yielded by our diff. JPEG, demonstrating the effective gradient approximation. Our code is available at https://github.com/necla-ml/Diff-JPEG.
LeanContext: Cost-Efficient Domain-Specific Question Answering Using LLMs
Sep 02, 2023Question-answering (QA) is a significant application of Large Language Models (LLMs), shaping chatbot capabilities across healthcare, education, and customer service. However, widespread LLM integration presents a challenge for small businesses due to the high expenses of LLM API usage. Costs rise rapidly when domain-specific data (context) is used alongside queries for accurate domain-specific LLM responses. One option is to summarize the context by using LLMs and reduce the context. However, this can also filter out useful information that is necessary to answer some domain-specific queries. In this paper, we shift from human-oriented summarizers to AI model-friendly summaries. Our approach, LeanContext, efficiently extracts $k$ key sentences from the context that are closely aligned with the query. The choice of $k$ is neither static nor random; we introduce a reinforcement learning technique that dynamically determines $k$ based on the query and context. The rest of the less important sentences are reduced using a free open source text reduction method. We evaluate LeanContext against several recent query-aware and query-unaware context reduction approaches on prominent datasets (arxiv papers and BBC news articles). Despite cost reductions of $37.29\%$ to $67.81\%$, LeanContext's ROUGE-1 score decreases only by $1.41\%$ to $2.65\%$ compared to a baseline that retains the entire context (no summarization). Additionally, if free pretrained LLM-based summarizers are used to reduce context (into human consumable summaries), LeanContext can further modify the reduced context to enhance the accuracy (ROUGE-1 score) by $13.22\%$ to $24.61\%$.
APT: Adaptive Perceptual quality based camera Tuning using reinforcement learning
Nov 15, 2022
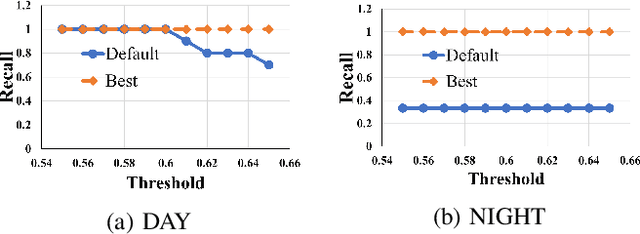
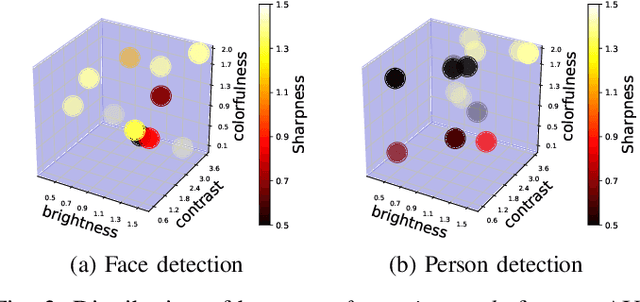
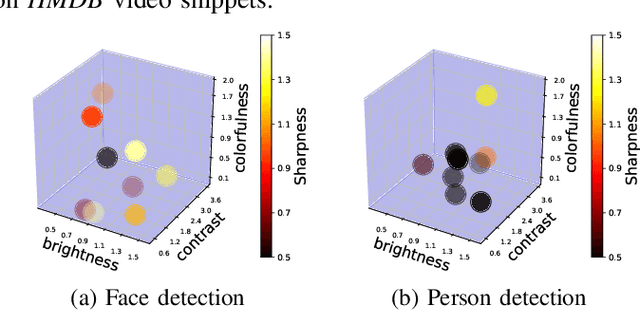
Cameras are increasingly being deployed in cities, enterprises and roads world-wide to enable many applications in public safety, intelligent transportation, retail, healthcare and manufacturing. Often, after initial deployment of the cameras, the environmental conditions and the scenes around these cameras change, and our experiments show that these changes can adversely impact the accuracy of insights from video analytics. This is because the camera parameter settings, though optimal at deployment time, are not the best settings for good-quality video capture as the environmental conditions and scenes around a camera change during operation. Capturing poor-quality video adversely affects the accuracy of analytics. To mitigate the loss in accuracy of insights, we propose a novel, reinforcement-learning based system APT that dynamically, and remotely (over 5G networks), tunes the camera parameters, to ensure a high-quality video capture, which mitigates any loss in accuracy of video analytics. As a result, such tuning restores the accuracy of insights when environmental conditions or scene content change. APT uses reinforcement learning, with no-reference perceptual quality estimation as the reward function. We conducted extensive real-world experiments, where we simultaneously deployed two cameras side-by-side overlooking an enterprise parking lot (one camera only has manufacturer-suggested default setting, while the other camera is dynamically tuned by APT during operation). Our experiments demonstrated that due to dynamic tuning by APT, the analytics insights are consistently better at all times of the day: the accuracy of object detection video analytics application was improved on average by ~ 42%. Since our reward function is independent of any analytics task, APT can be readily used for different video analytics tasks.
Why is the video analytics accuracy fluctuating, and what can we do about it?
Aug 23, 2022

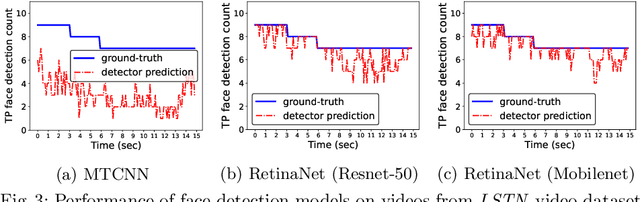
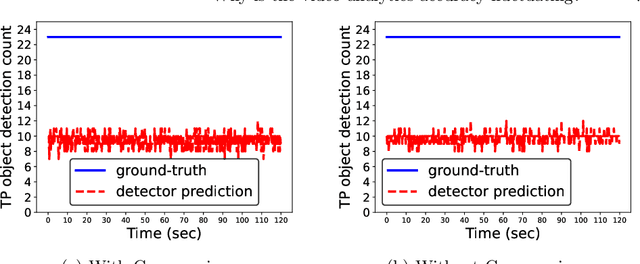
It is a common practice to think of a video as a sequence of images (frames), and re-use deep neural network models that are trained only on images for similar analytics tasks on videos. In this paper, we show that this leap of faith that deep learning models that work well on images will also work well on videos is actually flawed. We show that even when a video camera is viewing a scene that is not changing in any human-perceptible way, and we control for external factors like video compression and environment (lighting), the accuracy of video analytics application fluctuates noticeably. These fluctuations occur because successive frames produced by the video camera may look similar visually, but these frames are perceived quite differently by the video analytics applications. We observed that the root cause for these fluctuations is the dynamic camera parameter changes that a video camera automatically makes in order to capture and produce a visually pleasing video. The camera inadvertently acts as an unintentional adversary because these slight changes in the image pixel values in consecutive frames, as we show, have a noticeably adverse impact on the accuracy of insights from video analytics tasks that re-use image-trained deep learning models. To address this inadvertent adversarial effect from the camera, we explore the use of transfer learning techniques to improve learning in video analytics tasks through the transfer of knowledge from learning on image analytics tasks. In particular, we show that our newly trained Yolov5 model reduces fluctuation in object detection across frames, which leads to better tracking of objects(40% fewer mistakes in tracking). Our paper also provides new directions and techniques to mitigate the camera's adversarial effect on deep learning models used for video analytics applications.
Edge-based fever screening system over private 5G
Feb 08, 2022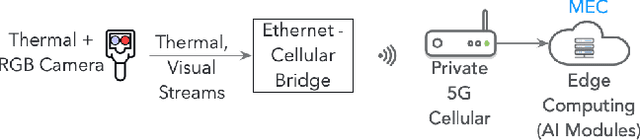
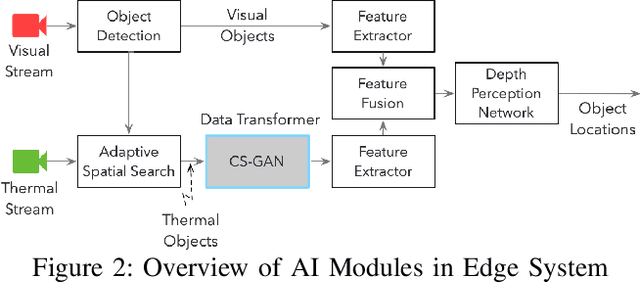
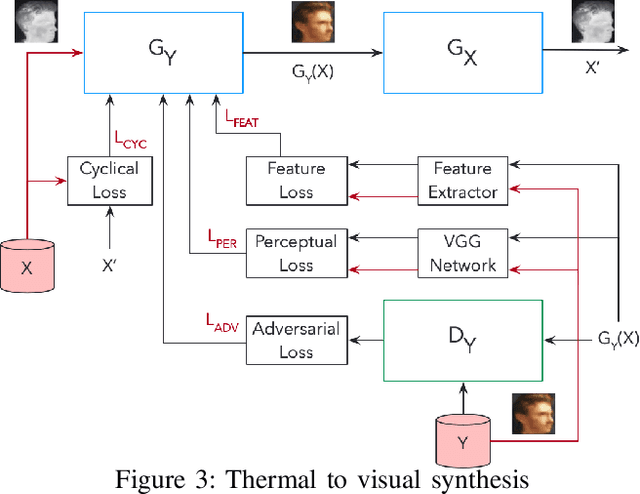
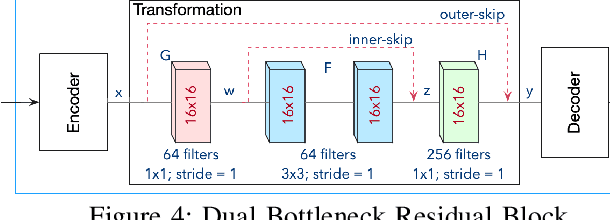
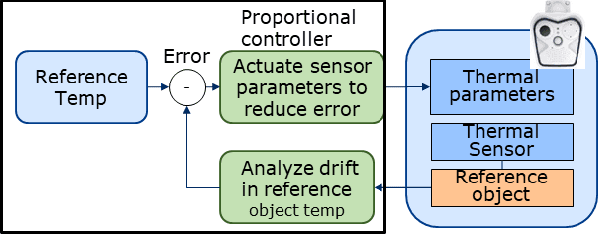
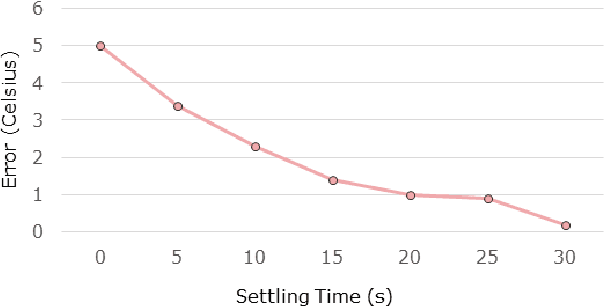
Edge computing and 5G have made it possible to perform analytics closer to the source of data and achieve super-low latency response times, which is not possible with centralized cloud deployment. In this paper, we present a novel fever-screening system, which uses edge machine learning techniques and leverages private 5G to accurately identify and screen individuals with fever in real-time. Particularly, we present deep-learning based novel techniques for fusion and alignment of cross-spectral visual and thermal data streams at the edge. Our novel Cross-Spectral Generative Adversarial Network (CS-GAN) synthesizes visual images that have the key, representative object level features required to uniquely associate objects across visual and thermal spectrum. Two key features of CS-GAN are a novel, feature-preserving loss function that results in high-quality pairing of corresponding cross-spectral objects, and dual bottleneck residual layers with skip connections (a new, network enhancement) to not only accelerate real-time inference, but to also speed up convergence during model training at the edge. To the best of our knowledge, this is the first technique that leverages 5G networks and limited edge resources to enable real-time feature-level association of objects in visual and thermal streams (30 ms per full HD frame on an Intel Core i7-8650 4-core, 1.9GHz mobile processor). To the best of our knowledge, this is also the first system to achieve real-time operation, which has enabled fever screening of employees and guests in arenas, theme parks, airports and other critical facilities. By leveraging edge computing and 5G, our fever screening system is able to achieve 98.5% accuracy and is able to process about 5X more people when compared to a centralized cloud deployment.
F3S: Free Flow Fever Screening
Sep 03, 2021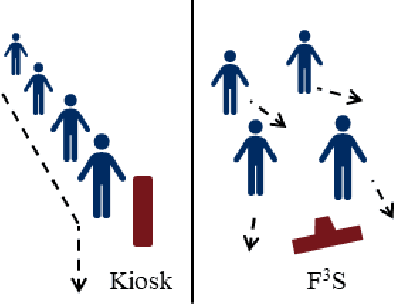
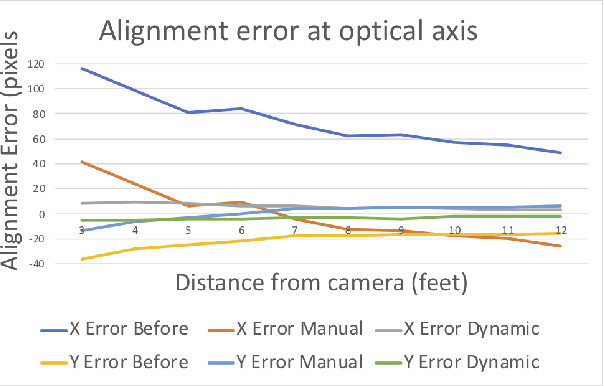
Identification of people with elevated body temperature can reduce or dramatically slow down the spread of infectious diseases like COVID-19. We present a novel fever-screening system, F3S, that uses edge machine learning techniques to accurately measure core body temperatures of multiple individuals in a free-flow setting. F3S performs real-time sensor fusion of visual camera with thermal camera data streams to detect elevated body temperature, and it has several unique features: (a) visual and thermal streams represent very different modalities, and we dynamically associate semantically-equivalent regions across visual and thermal frames by using a new, dynamic alignment technique that analyzes content and context in real-time, (b) we track people through occlusions, identify the eye (inner canthus), forehead, face and head regions where possible, and provide an accurate temperature reading by using a prioritized refinement algorithm, and (c) we robustly detect elevated body temperature even in the presence of personal protective equipment like masks, or sunglasses or hats, all of which can be affected by hot weather and lead to spurious temperature readings. F3S has been deployed at over a dozen large commercial establishments, providing contact-less, free-flow, real-time fever screening for thousands of employees and customers in indoors and outdoor settings.
Accelerating Deep Neural Network Training with Inconsistent Stochastic Gradient Descent
Mar 28, 2017


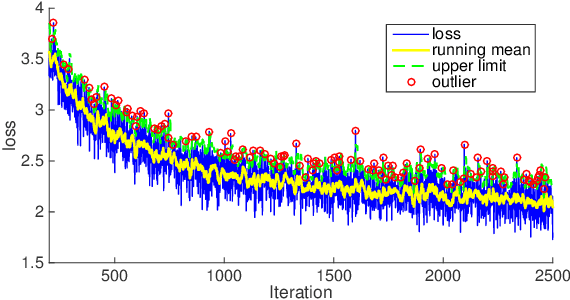
SGD is the widely adopted method to train CNN. Conceptually it approximates the population with a randomly sampled batch; then it evenly trains batches by conducting a gradient update on every batch in an epoch. In this paper, we demonstrate Sampling Bias, Intrinsic Image Difference and Fixed Cycle Pseudo Random Sampling differentiate batches in training, which then affect learning speeds on them. Because of this, the unbiased treatment of batches involved in SGD creates improper load balancing. To address this issue, we present Inconsistent Stochastic Gradient Descent (ISGD) to dynamically vary training effort according to learning statuses on batches. Specifically ISGD leverages techniques in Statistical Process Control to identify a undertrained batch. Once a batch is undertrained, ISGD solves a new subproblem, a chasing logic plus a conservative constraint, to accelerate the training on the batch while avoid drastic parameter changes. Extensive experiments on a variety of datasets demonstrate ISGD converges faster than SGD. In training AlexNet, ISGD is 21.05\% faster than SGD to reach 56\% top1 accuracy under the exactly same experiment setup. We also extend ISGD to work on multiGPU or heterogeneous distributed system based on data parallelism, enabling the batch size to be the key to scalability. Then we present the study of ISGD batch size to the learning rate, parallelism, synchronization cost, system saturation and scalability. We conclude the optimal ISGD batch size is machine dependent. Various experiments on a multiGPU system validate our claim. In particular, ISGD trains AlexNet to 56.3% top1 and 80.1% top5 accuracy in 11.5 hours with 4 NVIDIA TITAN X at the batch size of 1536.