 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Deep Neural Network Training with Inconsistent Stochastic Gradient Descent
Paper and Code
Mar 28, 2017


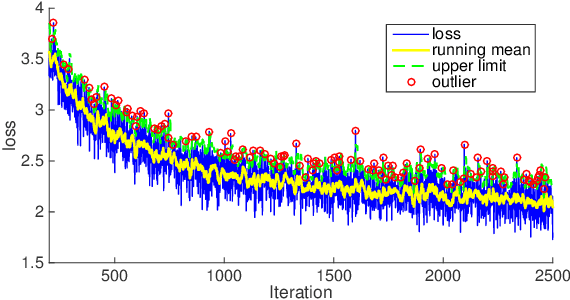
SGD is the widely adopted method to train CNN. Conceptually it approximates the population with a randomly sampled batch; then it evenly trains batches by conducting a gradient update on every batch in an epoch. In this paper, we demonstrate Sampling Bias, Intrinsic Image Difference and Fixed Cycle Pseudo Random Sampling differentiate batches in training, which then affect learning speeds on them. Because of this, the unbiased treatment of batches involved in SGD creates improper load balancing. To address this issue, we present Inconsistent Stochastic Gradient Descent (ISGD) to dynamically vary training effort according to learning statuses on batches. Specifically ISGD leverages techniques in Statistical Process Control to identify a undertrained batch. Once a batch is undertrained, ISGD solves a new subproblem, a chasing logic plus a conservative constraint, to accelerate the training on the batch while avoid drastic parameter changes. Extensive experiments on a variety of datasets demonstrate ISGD converges faster than SGD. In training AlexNet, ISGD is 21.05\% faster than SGD to reach 56\% top1 accuracy under the exactly same experiment setup. We also extend ISGD to work on multiGPU or heterogeneous distributed system based on data parallelism, enabling the batch size to be the key to scalability. Then we present the study of ISGD batch size to the learning rate, parallelism, synchronization cost, system saturation and scalability. We conclude the optimal ISGD batch size is machine dependent. Various experiments on a multiGPU system validate our claim. In particular, ISGD trains AlexNet to 56.3% top1 and 80.1% top5 accuracy in 11.5 hours with 4 NVIDIA TITAN X at the batch size of 1536.