 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Video Foundation Models with NVIDIA NeMo
Mar 17, 2025Video Foundation Models (VFMs) have recently been used to simulate the real world to train physical AI systems and develop creative visual experiences. However, there are significant challenges in training large-scale, high quality VFMs that can generate high-quality videos. We present a scalable, open-source VFM training pipeline with NVIDIA NeMo, providing accelerated video dataset curation, multimodal data loading, and parallelized video diffusion model training and inference. We also provide a comprehensive performance analysis highlighting best practices for efficient VFM training and inference.
Multi-objective Neural Architecture Search by Learning Search Space Partitions
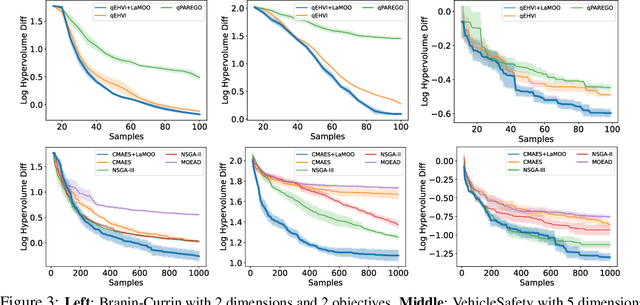
Jun 01, 2024Deploying deep learning models requires taking into consideration neural network metrics such as model size, inference latency, and #FLOPs, aside from inference accuracy. This results in deep learning model designers leveraging multi-objective optimization to design effective deep neural networks in multiple criteria. However, applying multi-objective optimizations to neural architecture search (NAS) is nontrivial because NAS tasks usually have a huge search space, along with a non-negligible searching cost. This requires effective multi-objective search algorithms to alleviate the GPU costs. In this work, we implement a novel multi-objectives optimizer based on a recently proposed meta-algorithm called LaMOO on NAS tasks. In a nutshell, LaMOO speedups the search process by learning a model from observed samples to partition the search space and then focusing on promising regions likely to contain a subset of the Pareto frontier. Using LaMOO, we observe an improvement of more than 200% sample efficiency compared to Bayesian optimization and evolutionary-based multi-objective optimizers on different NAS datasets. For example, when combined with LaMOO, qEHVI achieves a 225% improvement in sample efficiency compared to using qEHVI alone in NasBench201. For real-world tasks, LaMOO achieves 97.36% accuracy with only 1.62M #Params on CIFAR10 in only 600 search samples. On ImageNet, our large model reaches 80.4% top-1 accuracy with only 522M #FLOPs.
GPUNet: Searching the Deployable Convolution Neural Networks for GPUs
Apr 26, 2022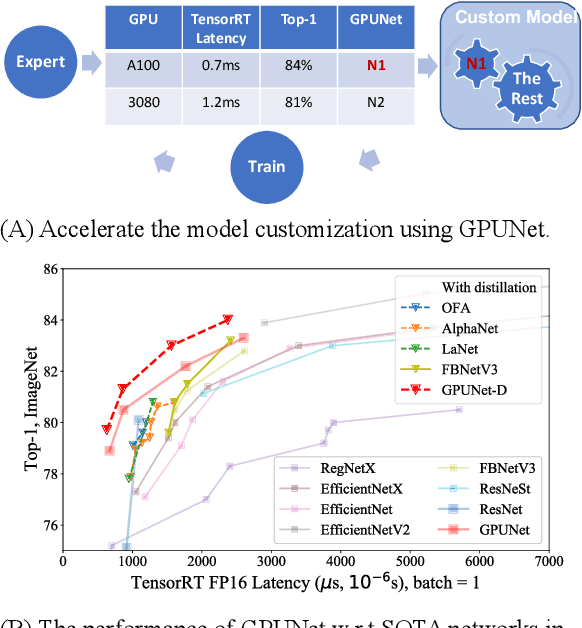
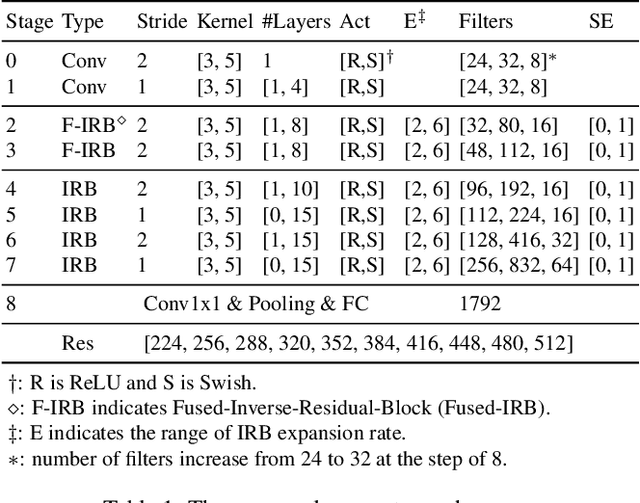
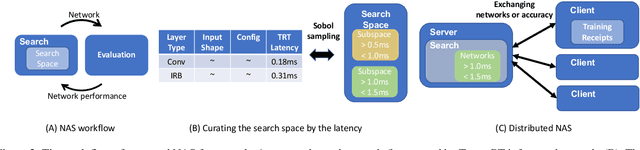

Customizing Convolution Neural Networks (CNN) for production use has been a challenging task for DL practitioners. This paper intends to expedite the model customization with a model hub that contains the optimized models tiered by their inference latency using Neural Architecture Search (NAS). To achieve this goal, we build a distributed NAS system to search on a novel search space that consists of prominent factors to impact latency and accuracy. Since we target GPU, we name the NAS optimized models as GPUNet, which establishes a new SOTA Pareto frontier in inference latency and accuracy. Within 1$ms$, GPUNet is 2x faster than EfficientNet-X and FBNetV3 with even better accuracy. We also validate GPUNet on detection tasks, and GPUNet consistently outperforms EfficientNet-X and FBNetV3 on COCO detection tasks in both latency and accuracy. All of these data validate that our NAS system is effective and generic to handle different design tasks. With this NAS system, we expand GPUNet to cover a wide range of latency targets such that DL practitioners can deploy our models directly in different scenarios.
Multi-objective Optimization by Learning Space Partitions
Oct 10, 2021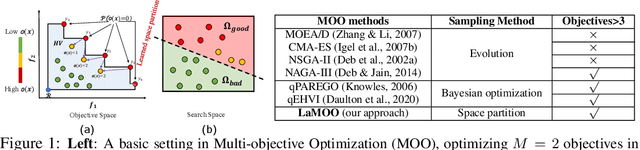
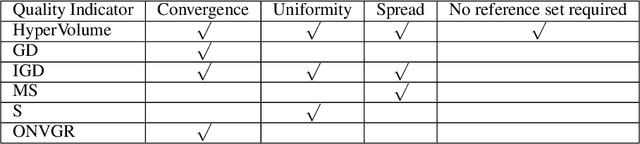
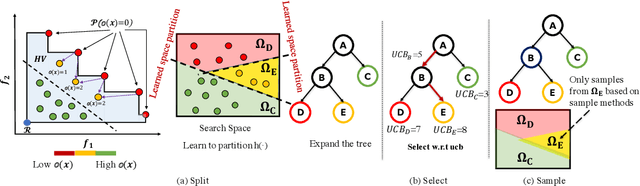
In contrast to single-objective optimization (SOO), multi-objective optimization (MOO) requires an optimizer to find the Pareto frontier, a subset of feasible solutions that are not dominated by other feasible solutions. In this paper, we propose LaMOO, a novel multi-objective optimizer that learns a model from observed samples to partition the search space and then focus on promising regions that are likely to contain a subset of the Pareto frontier. The partitioning is based on the dominance number, which measures "how close" a data point is to the Pareto frontier among existing samples. To account for possible partition errors due to limited samples and model mismatch, we leverage Monte Carlo Tree Search (MCTS) to exploit promising regions while exploring suboptimal regions that may turn out to contain good solutions later. Theoretically, we prove the efficacy of learning space partitioning via LaMOO under certain assumptions. Empirically, on the HyperVolume (HV) benchmark, a popular MOO metric, LaMOO substantially outperforms strong baselines on multiple real-world MOO tasks, by up to 225% in sample efficiency for neural architecture search on Nasbench201, and up to 10% for molecular design.
Learning Space Partitions for Path Planning
Jul 14, 2021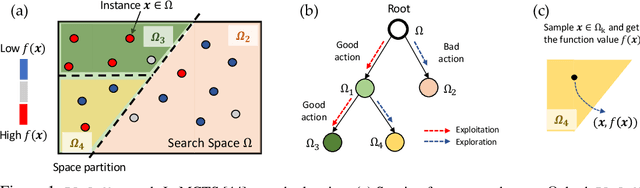

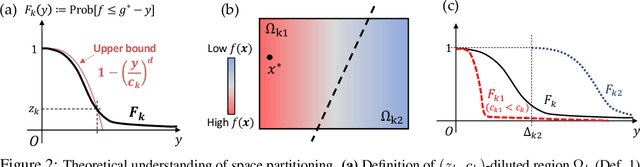
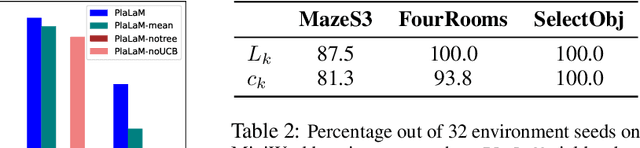
Path planning, the problem of efficiently discovering high-reward trajectories, often requires optimizing a high-dimensional and multimodal reward function. Popular approaches like CEM and CMA-ES greedily focus on promising regions of the search space and may get trapped in local maxima. DOO and VOOT balance exploration and exploitation, but use space partitioning strategies independent of the reward function to be optimized. Recently, LaMCTS empirically learns to partition the search space in a reward-sensitive manner for black-box optimization. In this paper, we develop a novel formal regret analysis for when and why such an adaptive region partitioning scheme works. We also propose a new path planning method PlaLaM which improves the function value estimation within each sub-region, and uses a latent representation of the search space. Empirically, PlaLaM outperforms existing path planning methods in 2D navigation tasks, especially in the presence of difficult-to-escape local optima, and shows benefits when plugged into model-based RL with planning components such as PETS. These gains transfer to highly multimodal real-world tasks, where we outperform strong baselines in compiler phase ordering by up to 245% and in molecular design by up to 0.4 on properties on a 0-1 scale. Code is available at https://github.com/yangkevin2/plalam.
Learning Search Space Partition for Black-box Optimization using Monte Carlo Tree Search
Jul 01, 2020

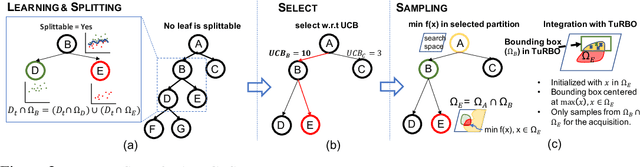
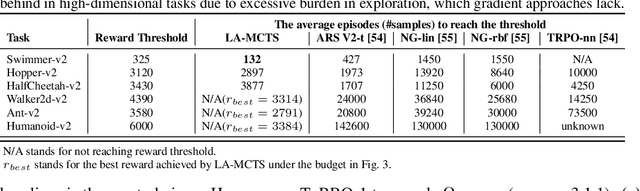
High dimensional black-box optimization has broad applications but remains a challenging problem to solve. Given a set of samples $\{\vx_i, y_i\}$, building a global model (like Bayesian Optimization (BO)) suffers from the curse of dimensionality in the high-dimensional search space, while a greedy search may lead to sub-optimality. By recursively splitting the search space into regions with high/low function values, recent works like LaNAS shows good performance in Neural Architecture Search (NAS), reducing the sample complexity empirically. In this paper, we coin LA-MCTS that extends LaNAS to other domains. Unlike previous approaches, LA-MCTS learns the partition of the search space using a few samples and their function values in an online fashion. While LaNAS uses linear partition and performs uniform sampling in each region, our LA-MCTS adopts a nonlinear decision boundary and learns a local model to pick good candidates. If the nonlinear partition function and the local model fits well with ground-truth black-box function, then good partitions and candidates can be reached with much fewer samples. LA-MCTS serves as a \emph{meta-algorithm} by using existing black-box optimizers (e.g., BO, TuRBO) as its local models, achieving strong performance in general black-box optimization and reinforcement learning benchmarks, in particular for high-dimensional problems.
Few-shot Neural Architecture Search
Jun 19, 2020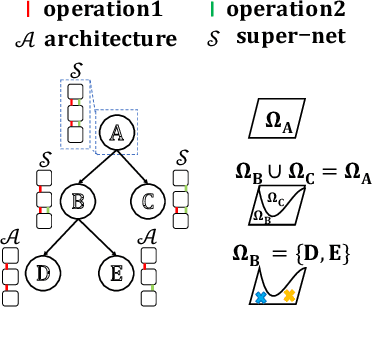
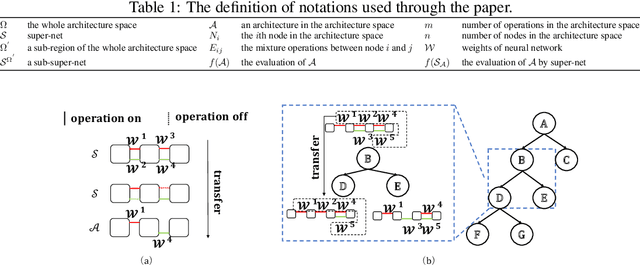
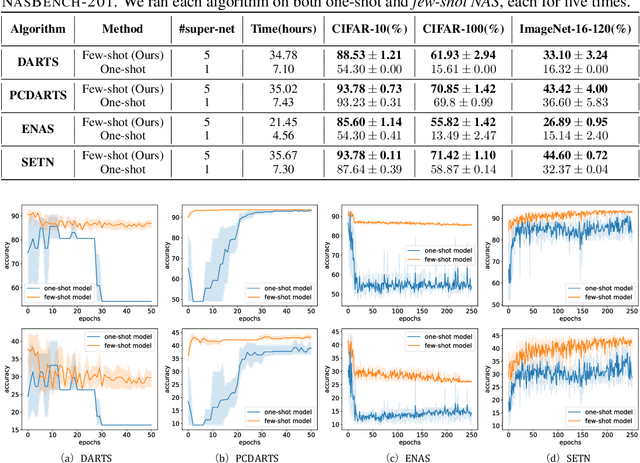
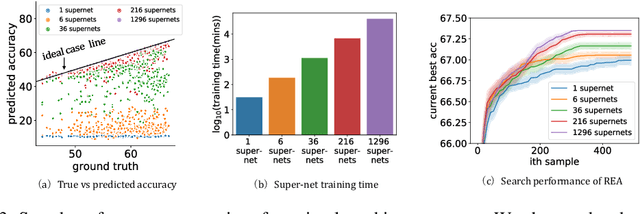
To improve the search efficiency for Neural Architecture Search (NAS), One-shot NAS proposes to train a single super-net to approximate the performance of proposal architectures during search via weight-sharing. While this greatly reduces the computation cost, due to approximation error, the performance prediction by a single super-net is less accurate than training each proposal architecture from scratch, leading to search inefficiency. In this work, we propose few-shot NAS that explores the choice of using multiple super-nets: each super-net is pre-trained to be in charge of a sub-region of the search space. This reduces the prediction error of each super-net. Moreover, training these super-nets can be done jointly via sequential fine-tuning. A natural choice of sub-region is to follow the splitting of search space in NAS. We empirically evaluate our approach on three different tasks in NAS-Bench-201. Extensive results have demonstrated that few-shot NAS, using only 5 super-nets, significantly improves performance of many search methods with slight increase of search time. The architectures found by DARTs and ENAS with few-shot models achieved 88.53% and 86.50% test accuracy on CIFAR-10 in NAS-Bench-201, significantly outperformed their one-shot counterparts (with 54.30% and 54.30% test accuracy). Moreover, on AUTOGAN and DARTS, few-shot NAS also outperforms previously state-of-the-art models.
Sample-Efficient Neural Architecture Search by Learning Action Space
Jun 17, 2019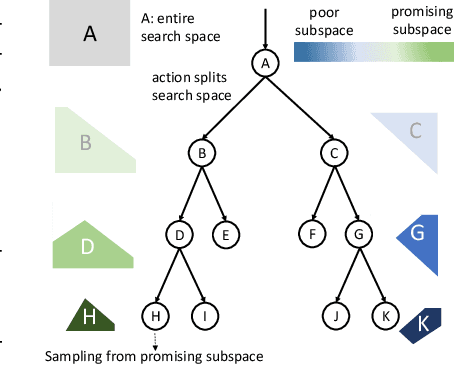
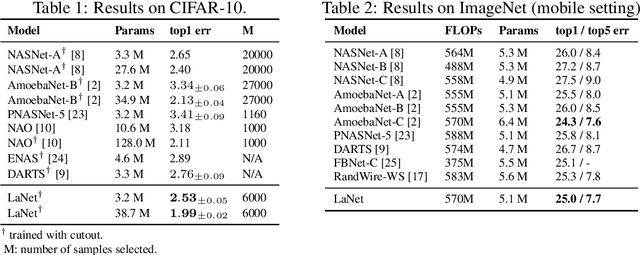
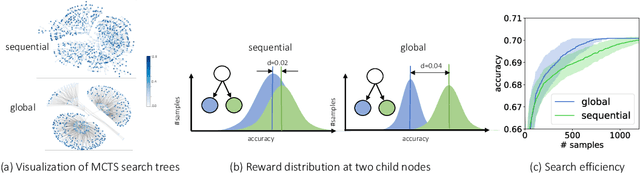
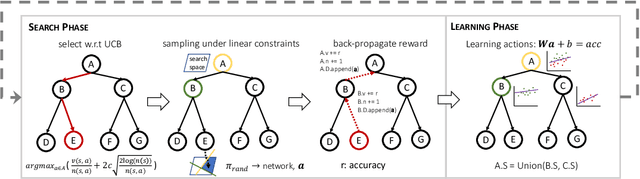
Neural Architecture Search (NAS) has emerged as a promising technique for automatic neural network design. However, existing NAS approaches often utilize manually designed action space, which is not directly related to the performance metric to be optimized (e.g., accuracy). As a result, using manually designed action space to perform NAS often leads to sample-inefficient explorations of architectures and thus can be sub-optimal. In order to improve sample efficiency, this paper proposes Latent Action Neural Architecture Search (LaNAS) that learns the action space to recursively partition the architecture search space into regions, each with concentrated performance metrics (\emph{i.e.}, low variance). During the search phase, as different architecture search action sequences lead to regions of different performance, the search efficiency can be significantly improved by biasing towards the regions with good performance. On the largest NAS dataset NasBench-101, our experimental results demonstrated that LaNAS is 22x, 14.6x and 12.4x more sample-efficient than random search, regularized evolution, and Monte Carlo Tree Search (MCTS) respectively. When applied to the open domain, LaNAS finds an architecture that achieves SoTA 98.0% accuracy on CIFAR-10 and 75.0% top1 accuracy on ImageNet (mobile setting), after exploring only 6,000 architectures.
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
Mar 26, 2019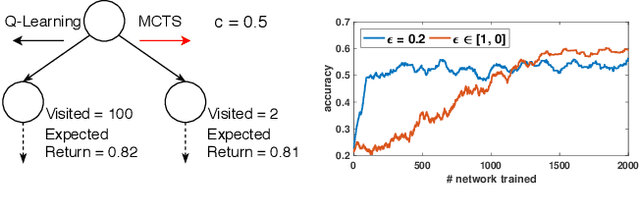
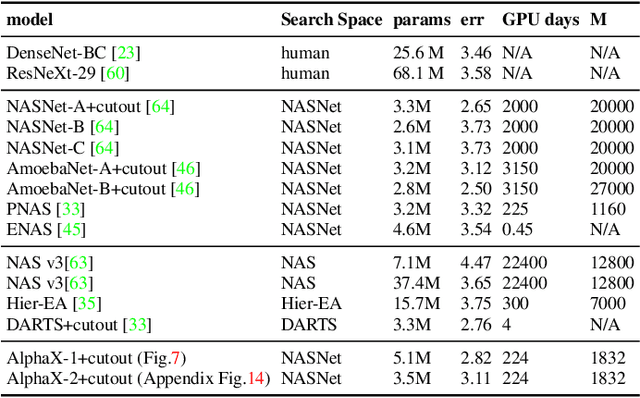
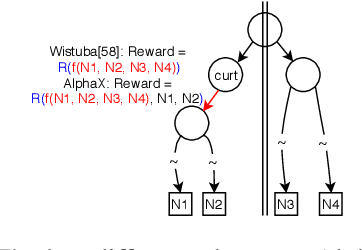
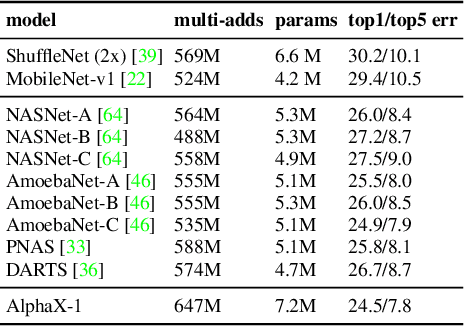
We present AlphaX, a fully automated agent that designs complex neural architectures from scratch. AlphaX explores the exponentially grown search space with a distributed Monte Carlo Tree Search (MCTS) and a Meta-Deep Neural Network (DNN). MCTS intrinsically improves the search efficiency by dynamically balancing the exploration and exploitation at fine-grained states, while Meta-DNN predicts the network accuracy to guide the search, and to provide an estimated reward to speed up the rollout. As the search progresses, AlphaX also generates the training data for Meta-DNN. So, the learning of Meta-DNN is end-to-end. In 14 days with only 16 GPUs (1832 samples), AlphaX found an architecture that reaches the state-of-the-art accuracies on both CIFAR-10(97.18%) and ImageNet(75.5% top-1 and 92.2% top-5). This demonstrates up to 10x speedup over the original searching for NASNet that used 500 GPUs in 4 days (20000 samples). On NASBench-101, AlphaX demonstrates 3x and 2.8x speedup over Random Search and Regularized Evolution. Finally, we show the searched architecture improves a variety of vision applications from Neural Style Transfer, to Image Captioning and Object Detection. Our implementation is available at https://github.com/linnanwang/AlphaX-NASBench101.