 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMESA: Improving MoE Safety Alignment via Decentralized Expertise
May 30, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models (LLMs) efficiently, enabling greater capacity with reduced computational cost by dynamically routing inputs to relevant experts, yet introduce a critical vulnerability: Safety Sparsity, where safety capabilities concentrate in few experts, making them susceptible to adversarial bypassing. Meanwhile, conventional alignment methods uniformly adapt all parameters, ignoring their functional differences and inadvertently degrading performances. To address these challenges, we propose MESA (MoE Safety Alignment), a targeted alignment framework for MoE-based LLMs that strategically decentralizes safety responsibility to maximize coverage while minimizing interference with utility. Based on Optimal Transport (OT) theory, MESA operates through two mechanisms: (1) Expert Capacity Reallocation uses a transport cost matrix to distribute safety duties to the most cost-effective experts, and (2) Dynamic Routing Refinement constrains the router to precisely activate these decentralized modules. Experiments show that MESA achieves robust defensive performance against varied harmful benchmarks while preserving helpfulness. Code is available at https://github.com/lorraine021/MESA.
Perceptual Flow Network for Visually Grounded Reasoning
May 04, 2026Despite the success of Large-Vision Language Models (LVLMs), general optimization objectives (e.g., standard MLE) fail to constrain visual trajectories, leading to language bias and hallucination. To mitigate this, current methods introduce geometric priors from visual experts as additional supervision. However, we observe that such supervision is typically suboptimal: it is biased toward geometric precision and offers limited reasoning utility. To bridge this gap, we propose Perceptual Flow Network (PFlowNet), which eschews rigid alignment with the expert priors and achieves interpretable yet more effective visual reasoning. Specifically, PFlowNet decouples perception from reasoning to establish a self-conditioned generation process. Based on this, it integrates multi-dimensional rewards with vicinal geometric shaping via variational reinforcement learning, thereby facilitating reasoning-oriented perceptual behaviors while preserving visual reliability. PFlowNet delivers a provable performance guarantee and competitive empirical results, particularly setting new SOTA records on V* Bench (90.6%) and MME-RealWorld-lite (67.0%).
Probabilistic Graphical Model using Graph Neural Networks for Bayesian Inversion of Discrete Structural Component States
Apr 26, 2026The health condition of components in civil infrastructures can be described by various discrete states according to their performance degradation. Inferring these states from measurable responses is typically an ill-posed inverse problem. Although Bayesian methods are well-suited to tackle such problems, computing the posterior probability density function (PDF) presents challenges. The likelihood function cannot be analytically formulated due to the unclear relationship between discrete states and structural responses, and the high-dimensional state parameters resulting from numerous components severely complicates the computation of the marginal likelihood function. To address these challenges, this study proposes a novel Bayesian inversion paradigm for discrete variables based on Probabilistic Graphical Models (PGMs). The Markov networks are employed as modeling tools, with model parameters learned from data and structural topology prior. It has been proved that inferring this PGM produces the same probabilistic estimation as the posterior PDF derived from Bayesian inference, which effectively solves the above challenges. The inference is accomplished by Graph Neural Networks (GNNs), and a graph property-based GNN training strategy is developed to enable accurate inference across varying graph scales, thereby significantly reducing the computational overhead in high-dimensional problems. Both synthetic and experimental data are used to validate the proposed framework
TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
Apr 08, 2026We propose TC-AE, a ViT-based architecture for deep compression autoencoders. Existing methods commonly increase the channel number of latent representations to maintain reconstruction quality under high compression ratios. However, this strategy often leads to latent representation collapse, which degrades generative performance. Instead of relying on increasingly complex architectures or multi-stage training schemes, TC-AE addresses this challenge from the perspective of the token space, the key bridge between pixels and image latents, through two complementary innovations: Firstly, we study token number scaling by adjusting the patch size in ViT under a fixed latent budget, and identify aggressive token-to-latent compression as the key factor that limits effective scaling. To address this issue, we decompose token-to-latent compression into two stages, reducing structural information loss and enabling effective token number scaling for generation. Secondly, to further mitigate latent representation collapse, we enhance the semantic structure of image tokens via joint self-supervised training, leading to more generative-friendly latents. With these designs, TC-AE achieves substantially improved reconstruction and generative performance under deep compression. We hope our research will advance ViT-based tokenizer for visual generation.
CGRL: Causal-Guided Representation Learning for Graph Out-of-Distribution Generalization
Mar 25, 2026Graph Neural Networks (GNNs) have achieved impressive performance in graph-related tasks. However, they suffer from poor generalization on out-of-distribution (OOD) data, as they tend to learn spurious correlations. Such correlations present a phenomenon that GNNs fail to stably learn the mutual information between prediction representations and ground-truth labels under OOD settings. To address these challenges, we formulate a causal graph starting from the essence of node classification, adopt backdoor adjustment to block non-causal paths, and theoretically derive a lower bound for improving OOD generalization of GNNs. To materialize these insights, we further propose a novel approach integrating causal representation learning and a loss replacement strategy. The former captures node-level causal invariance and reconstructs graph posterior distribution. The latter introduces asymptotic losses of the same order to replace the original losses. Extensive experiments demonstrate the superiority of our method in OOD generalization and effectively alleviating the phenomenon of unstable mutual information learning.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
RealCam-Vid: High-resolution Video Dataset with Dynamic Scenes and Metric-scale Camera Movements
Apr 11, 2025
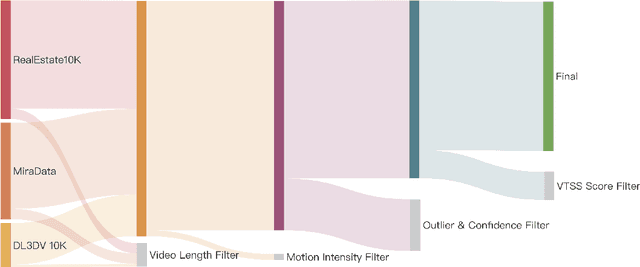
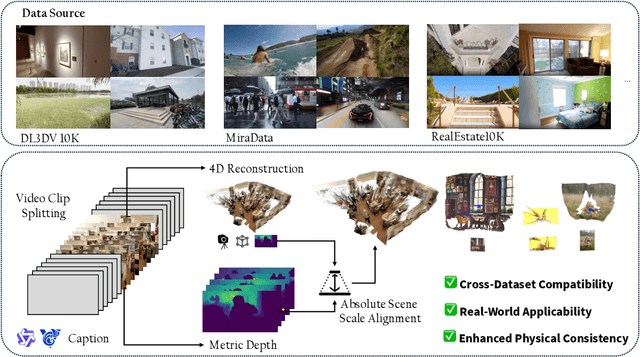
Recent advances in camera-controllable video generation have been constrained by the reliance on static-scene datasets with relative-scale camera annotations, such as RealEstate10K. While these datasets enable basic viewpoint control, they fail to capture dynamic scene interactions and lack metric-scale geometric consistency-critical for synthesizing realistic object motions and precise camera trajectories in complex environments. To bridge this gap, we introduce the first fully open-source, high-resolution dynamic-scene dataset with metric-scale camera annotations in https://github.com/ZGCTroy/RealCam-Vid.
Uni-Gaussians: Unifying Camera and Lidar Simulation with Gaussians for Dynamic Driving Scenarios
Mar 11, 2025Ensuring the safety of autonomous vehicles necessitates comprehensive simulation of multi-sensor data, encompassing inputs from both cameras and LiDAR sensors, across various dynamic driving scenarios. Neural rendering techniques, which utilize collected raw sensor data to simulate these dynamic environments, have emerged as a leading methodology. While NeRF-based approaches can uniformly represent scenes for rendering data from both camera and LiDAR, they are hindered by slow rendering speeds due to dense sampling. Conversely, Gaussian Splatting-based methods employ Gaussian primitives for scene representation and achieve rapid rendering through rasterization. However, these rasterization-based techniques struggle to accurately model non-linear optical sensors. This limitation restricts their applicability to sensors beyond pinhole cameras. To address these challenges and enable unified representation of dynamic driving scenarios using Gaussian primitives, this study proposes a novel hybrid approach. Our method utilizes rasterization for rendering image data while employing Gaussian ray-tracing for LiDAR data rendering. Experimental results on public datasets demonstrate that our approach outperforms current state-of-the-art methods. This work presents a unified and efficient solution for realistic simulation of camera and LiDAR data in autonomous driving scenarios using Gaussian primitives, offering significant advancements in both rendering quality and computational efficiency.
Energy-Guided Optimization for Personalized Image Editing with Pretrained Text-to-Image Diffusion Models
Mar 06, 2025The rapid advancement of pretrained text-driven diffusion models has significantly enriched applications in image generation and editing. However, as the demand for personalized content editing increases, new challenges emerge especially when dealing with arbitrary objects and complex scenes. Existing methods usually mistakes mask as the object shape prior, which struggle to achieve a seamless integration result. The mostly used inversion noise initialization also hinders the identity consistency towards the target object. To address these challenges, we propose a novel training-free framework that formulates personalized content editing as the optimization of edited images in the latent space, using diffusion models as the energy function guidance conditioned by reference text-image pairs. A coarse-to-fine strategy is proposed that employs text energy guidance at the early stage to achieve a natural transition toward the target class and uses point-to-point feature-level image energy guidance to perform fine-grained appearance alignment with the target object. Additionally, we introduce the latent space content composition to enhance overall identity consistency with the target. Extensive experiments demonstrate that our method excels in object replacement even with a large domain gap, highlighting its potential for high-quality, personalized image editing.
AIM: Additional Image Guided Generation of Transferable Adversarial Attacks
Jan 02, 2025Transferable adversarial examples highlight the vulnerability of deep neural networks (DNNs) to imperceptible perturbations across various real-world applications. While there have been notable advancements in untargeted transferable attacks, targeted transferable attacks remain a significant challenge. In this work, we focus on generative approaches for targeted transferable attacks. Current generative attacks focus on reducing overfitting to surrogate models and the source data domain, but they often overlook the importance of enhancing transferability through additional semantics. To address this issue, we introduce a novel plug-and-play module into the general generator architecture to enhance adversarial transferability. Specifically, we propose a \emph{Semantic Injection Module} (SIM) that utilizes the semantics contained in an additional guiding image to improve transferability. The guiding image provides a simple yet effective method to incorporate target semantics from the target class to create targeted and highly transferable attacks. Additionally, we propose new loss formulations that can integrate the semantic injection module more effectively for both targeted and untargeted attacks. We conduct comprehensive experiments under both targeted and untargeted attack settings to demonstrate the efficacy of our proposed approach.