 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-TRAE: A Dual-Phase Merging Transferable Reversible Adversarial Example for Image Privacy Protection
May 11, 2025In the field of digital security, Reversible Adversarial Examples (RAE) combine adversarial attacks with reversible data hiding techniques to effectively protect sensitive data and prevent unauthorized analysis by malicious Deep Neural Networks (DNNs). However, existing RAE techniques primarily focus on white-box attacks, lacking a comprehensive evaluation of their effectiveness in black-box scenarios. This limitation impedes their broader deployment in complex, dynamic environments. Further more, traditional black-box attacks are often characterized by poor transferability and high query costs, significantly limiting their practical applicability. To address these challenges, we propose the Dual-Phase Merging Transferable Reversible Attack method, which generates highly transferable initial adversarial perturbations in a white-box model and employs a memory augmented black-box strategy to effectively mislead target mod els. Experimental results demonstrate the superiority of our approach, achieving a 99.0% attack success rate and 100% recovery rate in black-box scenarios, highlighting its robustness in privacy protection. Moreover, we successfully implemented a black-box attack on a commercial model, further substantiating the potential of this approach for practical use.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
PATFinger: Prompt-Adapted Transferable Fingerprinting against Unauthorized Multimodal Dataset Usage
Apr 15, 2025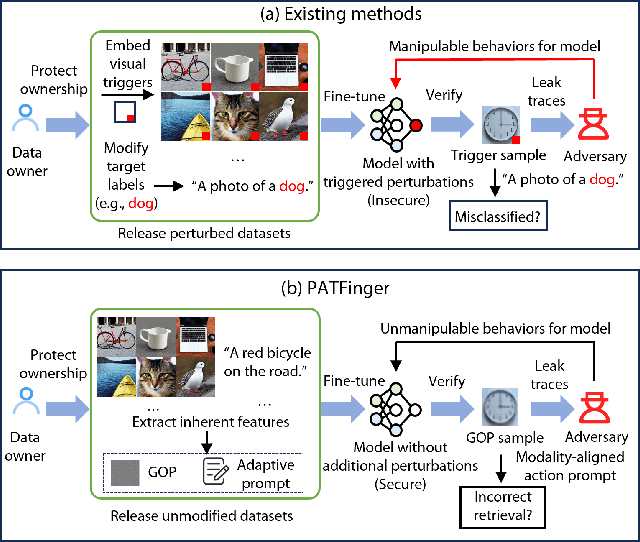
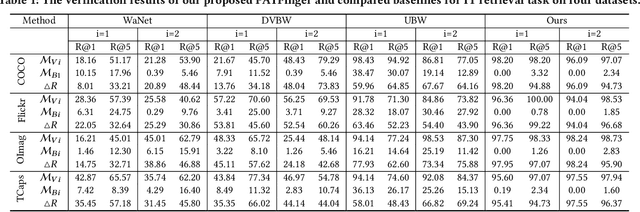
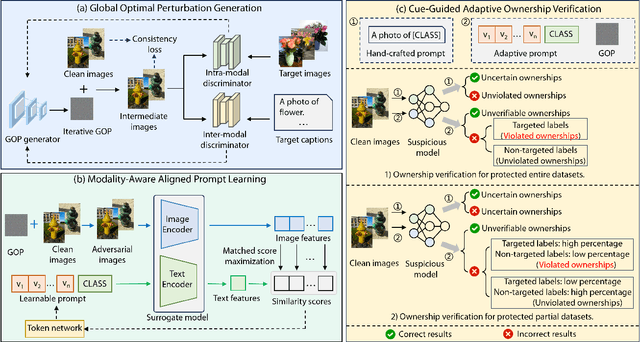
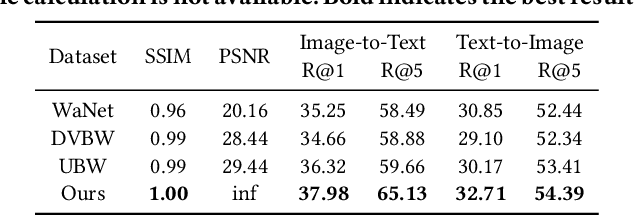
The multimodal datasets can be leveraged to pre-train large-scale vision-language models by providing cross-modal semantics. Current endeavors for determining the usage of datasets mainly focus on single-modal dataset ownership verification through intrusive methods and non-intrusive techniques, while cross-modal approaches remain under-explored. Intrusive methods can adapt to multimodal datasets but degrade model accuracy, while non-intrusive methods rely on label-driven decision boundaries that fail to guarantee stable behaviors for verification. To address these issues, we propose a novel prompt-adapted transferable fingerprinting scheme from a training-free perspective, called PATFinger, which incorporates the global optimal perturbation (GOP) and the adaptive prompts to capture dataset-specific distribution characteristics. Our scheme utilizes inherent dataset attributes as fingerprints instead of compelling the model to learn triggers. The GOP is derived from the sample distribution to maximize embedding drifts between different modalities. Subsequently, our PATFinger re-aligns the adaptive prompt with GOP samples to capture the cross-modal interactions on the carefully crafted surrogate model. This allows the dataset owner to check the usage of datasets by observing specific prediction behaviors linked to the PATFinger during retrieval queries. Extensive experiments demonstrate the effectiveness of our scheme against unauthorized multimodal dataset usage on various cross-modal retrieval architectures by 30% over state-of-the-art baselines.
Exploiting Vulnerabilities in Speech Translation Systems through Targeted Adversarial Attacks
Mar 05, 2025As speech translation (ST) systems become increasingly prevalent, understanding their vulnerabilities is crucial for ensuring robust and reliable communication. However, limited work has explored this issue in depth. This paper explores methods of compromising these systems through imperceptible audio manipulations. Specifically, we present two innovative approaches: (1) the injection of perturbation into source audio, and (2) the generation of adversarial music designed to guide targeted translation, while also conducting more practical over-the-air attacks in the physical world. Our experiments reveal that carefully crafted audio perturbations can mislead translation models to produce targeted, harmful outputs, while adversarial music achieve this goal more covertly, exploiting the natural imperceptibility of music. These attacks prove effective across multiple languages and translation models, highlighting a systemic vulnerability in current ST architectures. The implications of this research extend beyond immediate security concerns, shedding light on the interpretability and robustness of neural speech processing systems. Our findings underscore the need for advanced defense mechanisms and more resilient architectures in the realm of audio systems. More details and samples can be found at https://adv-st.github.io.
\textsc{Perseus}: Tracing the Masterminds Behind Cryptocurrency Pump-and-Dump Schemes
Mar 03, 2025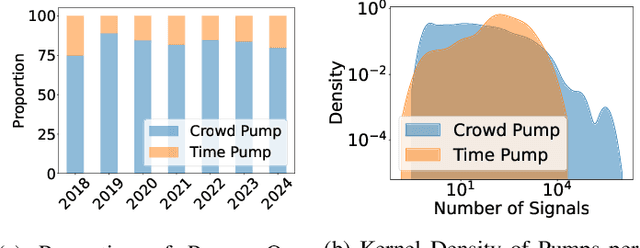
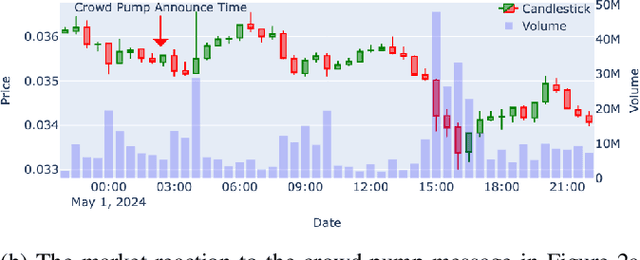
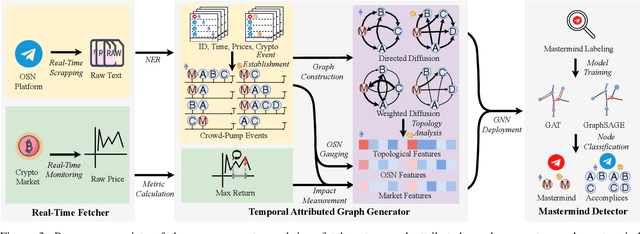
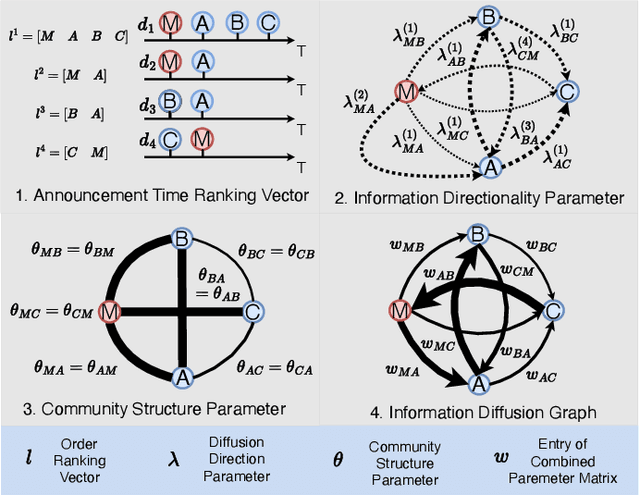
Masterminds are entities organizing, coordinating, and orchestrating cryptocurrency pump-and-dump schemes, a form of trade-based manipulation undermining market integrity and causing financial losses for unwitting investors. Previous research detects pump-and-dump activities in the market, predicts the target cryptocurrency, and examines investors and \ac{osn} entities. However, these solutions do not address the root cause of the problem. There is a critical gap in identifying and tracing the masterminds involved in these schemes. In this research, we develop a detection system \textsc{Perseus}, which collects real-time data from the \acs{osn} and cryptocurrency markets. \textsc{Perseus} then constructs temporal attributed graphs that preserve the direction of information diffusion and the structure of the community while leveraging \ac{gnn} to identify the masterminds behind pump-and-dump activities. Our design of \textsc{Perseus} leads to higher F1 scores and precision than the \ac{sota} fraud detection method, achieving fast training and inferring speeds. Deployed in the real world from February 16 to October 9 2024, \textsc{Perseus} successfully detects $438$ masterminds who are efficient in the pump-and-dump information diffusion networks. \textsc{Perseus} provides regulators with an explanation of the risks of masterminds and oversight capabilities to mitigate the pump-and-dump schemes of cryptocurrency.
Secure Resource Allocation via Constrained Deep Reinforcement Learning
Jan 20, 2025The proliferation of Internet of Things (IoT) devices and the advent of 6G technologies have introduced computationally intensive tasks that often surpass the processing capabilities of user devices. Efficient and secure resource allocation in serverless multi-cloud edge computing environments is essential for supporting these demands and advancing distributed computing. However, existing solutions frequently struggle with the complexity of multi-cloud infrastructures, robust security integration, and effective application of traditional deep reinforcement learning (DRL) techniques under system constraints. To address these challenges, we present SARMTO, a novel framework that integrates an action-constrained DRL model. SARMTO dynamically balances resource allocation, task offloading, security, and performance by utilizing a Markov decision process formulation, an adaptive security mechanism, and sophisticated optimization techniques. Extensive simulations across varying scenarios, including different task loads, data sizes, and MEC capacities, show that SARMTO consistently outperforms five baseline approaches, achieving up to a 40% reduction in system costs and a 41.5% improvement in energy efficiency over state-of-the-art methods. These enhancements highlight SARMTO's potential to revolutionize resource management in intricate distributed computing environments, opening the door to more efficient and secure IoT and edge computing applications.
Rethinking Membership Inference Attacks Against Transfer Learning
Jan 20, 2025Transfer learning, successful in knowledge translation across related tasks, faces a substantial privacy threat from membership inference attacks (MIAs). These attacks, despite posing significant risk to ML model's training data, remain limited-explored in transfer learning. The interaction between teacher and student models in transfer learning has not been thoroughly explored in MIAs, potentially resulting in an under-examined aspect of privacy vulnerabilities within transfer learning. In this paper, we propose a new MIA vector against transfer learning, to determine whether a specific data point was used to train the teacher model while only accessing the student model in a white-box setting. Our method delves into the intricate relationship between teacher and student models, analyzing the discrepancies in hidden layer representations between the student model and its shadow counterpart. These identified differences are then adeptly utilized to refine the shadow model's training process and to inform membership inference decisions effectively. Our method, evaluated across four datasets in diverse transfer learning tasks, reveals that even when an attacker only has access to the student model, the teacher model's training data remains susceptible to MIAs. We believe our work unveils the unexplored risk of membership inference in transfer learning.
LEO-Split: A Semi-Supervised Split Learning Framework over LEO Satellite Networks
Jan 02, 2025



Recently, the increasing deployment of LEO satellite systems has enabled various space analytics (e.g., crop and climate monitoring), which heavily relies on the advancements in deep learning (DL). However, the intermittent connectivity between LEO satellites and ground station (GS) significantly hinders the timely transmission of raw data to GS for centralized learning, while the scaled-up DL models hamper distributed learning on resource-constrained LEO satellites. Though split learning (SL) can be a potential solution to these problems by partitioning a model and offloading primary training workload to GS, the labor-intensive labeling process remains an obstacle, with intermittent connectivity and data heterogeneity being other challenges. In this paper, we propose LEO-Split, a semi-supervised (SS) SL design tailored for satellite networks to combat these challenges. Leveraging SS learning to handle (labeled) data scarcity, we construct an auxiliary model to tackle the training failure of the satellite-GS non-contact time. Moreover, we propose a pseudo-labeling algorithm to rectify data imbalances across satellites. Lastly, an adaptive activation interpolation scheme is devised to prevent the overfitting of server-side sub-model training at GS. Extensive experiments with real-world LEO satellite traces (e.g., Starlink) demonstrate that our LEO-Split framework achieves superior performance compared to state-ofthe-art benchmarks.
Adaptive Hyper-Graph Convolution Network for Skeleton-based Human Action Recognition with Virtual Connections
Nov 22, 2024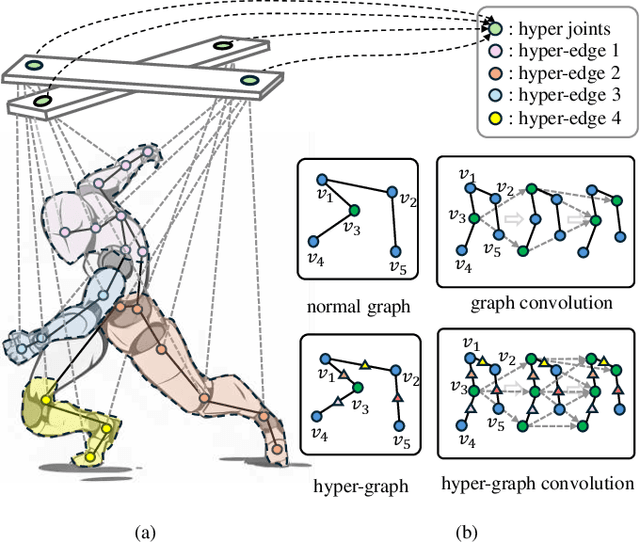



The shared topology of human skeletons motivated the recent investigation of graph convolutional network (GCN) solutions for action recognition. However, the existing GCNs rely on the binary connection of two neighbouring vertices (joints) formed by an edge (bone), overlooking the potential of constructing multi-vertex convolution structures. In this paper we address this oversight and explore the merits of a hyper-graph convolutional network (Hyper-GCN) to achieve the aggregation of rich semantic information conveyed by skeleton vertices. In particular, our Hyper-GCN adaptively optimises multi-scale hyper-graphs during training, revealing the action-driven multi-vertex relations. Besides, virtual connections are often designed to support efficient feature aggregation, implicitly extending the spectrum of dependencies within the skeleton. By injecting virtual connections into hyper-graphs, the semantic clues of diverse action categories can be highlighted. The results of experiments conducted on the NTU-60, NTU-120, and NW-UCLA datasets, demonstrate the merits of our Hyper-GCN, compared to the state-of-the-art methods. Specifically, we outperform the existing solutions on NTU-120, achieving 90.2\% and 91.4\% in terms of the top-1 recognition accuracy on X-Sub and X-Set.
HeteroSample: Meta-path Guided Sampling for Heterogeneous Graph Representation Learning
Nov 11, 2024
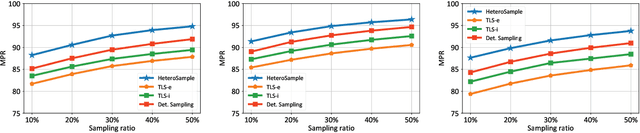
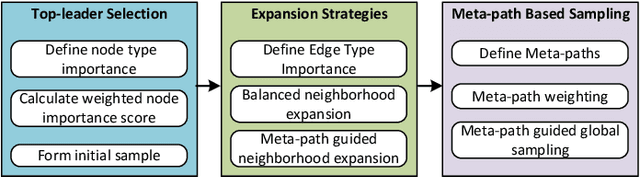
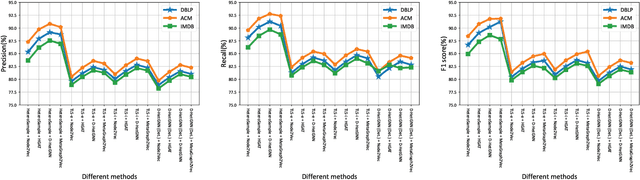
The rapid expansion of Internet of Things (IoT) has resulted in vast, heterogeneous graphs that capture complex interactions among devices, sensors, and systems. Efficient analysis of these graphs is critical for deriving insights in IoT scenarios such as smart cities, industrial IoT, and intelligent transportation systems. However, the scale and diversity of IoT-generated data present significant challenges, and existing methods often struggle with preserving the structural integrity and semantic richness of these complex graphs. Many current approaches fail to maintain the balance between computational efficiency and the quality of the insights generated, leading to potential loss of critical information necessary for accurate decision-making in IoT applications. We introduce HeteroSample, a novel sampling method designed to address these challenges by preserving the structural integrity, node and edge type distributions, and semantic patterns of IoT-related graphs. HeteroSample works by incorporating the novel top-leader selection, balanced neighborhood expansion, and meta-path guided sampling strategies. The key idea is to leverage the inherent heterogeneous structure and semantic relationships encoded by meta-paths to guide the sampling process. This approach ensures that the resulting subgraphs are representative of the original data while significantly reducing computational overhead. Extensive experiments demonstrate that HeteroSample outperforms state-of-the-art methods, achieving up to 15% higher F1 scores in tasks such as link prediction and node classification, while reducing runtime by 20%.These advantages make HeteroSample a transformative tool for scalable and accurate IoT applications, enabling more effective and efficient analysis of complex IoT systems, ultimately driving advancements in smart cities, industrial IoT, and beyond.