 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIDeR: Semantic Identity Decoupling for Unrestricted Face Privacy
Feb 04, 2026With the deep integration of facial recognition into online banking, identity verification, and other networked services, achieving effective decoupling of identity information from visual representations during image storage and transmission has become a critical challenge for privacy protection. To address this issue, we propose SIDeR, a Semantic decoupling-driven framework for unrestricted face privacy protection. SIDeR decomposes a facial image into a machine-recognizable identity feature vector and a visually perceptible semantic appearance component. By leveraging semantic-guided recomposition in the latent space of a diffusion model, it generates visually anonymous adversarial faces while maintaining machine-level identity consistency. The framework incorporates momentum-driven unrestricted perturbation optimization and a semantic-visual balancing factor to synthesize multiple visually diverse, highly natural adversarial samples. Furthermore, for authorized access, the protected image can be restored to its original form when the correct password is provided. Extensive experiments on the CelebA-HQ and FFHQ datasets demonstrate that SIDeR achieves a 99% attack success rate in black-box scenarios and outperforms baseline methods by 41.28% in PSNR-based restoration quality.
Conflict-Aware Client Selection for Multi-Server Federated Learning
Feb 02, 2026Federated learning (FL) has emerged as a promising distributed machine learning (ML) that enables collaborative model training across clients without exposing raw data, thereby preserving user privacy and reducing communication costs. Despite these benefits, traditional single-server FL suffers from high communication latency due to the aggregation of models from a large number of clients. While multi-server FL distributes workloads across edge servers, overlapping client coverage and uncoordinated selection often lead to resource contention, causing bandwidth conflicts and training failures. To address these limitations, we propose a decentralized reinforcement learning with conflict risk prediction, named RL CRP, to optimize client selection in multi-server FL systems. Specifically, each server estimates the likelihood of client selection conflicts using a categorical hidden Markov model based on its sparse historical client selection sequence. Then, a fairness-aware reward mechanism is incorporated to promote long-term client participation for minimizing training latency and resource contention. Extensive experiments demonstrate that the proposed RL-CRP framework effectively reduces inter-server conflicts and significantly improves training efficiency in terms of convergence speed and communication cost.
IO-RAE: Information-Obfuscation Reversible Adversarial Example for Audio Privacy Protection
Jan 03, 2026The rapid advancements in artificial intelligence have significantly accelerated the adoption of speech recognition technology, leading to its widespread integration across various applications. However, this surge in usage also highlights a critical issue: audio data is highly vulnerable to unauthorized exposure and analysis, posing significant privacy risks for businesses and individuals. This paper introduces an Information-Obfuscation Reversible Adversarial Example (IO-RAE) framework, the pioneering method designed to safeguard audio privacy using reversible adversarial examples. IO-RAE leverages large language models to generate misleading yet contextually coherent content, effectively preventing unauthorized eavesdropping by humans and Automatic Speech Recognition (ASR) systems. Additionally, we propose the Cumulative Signal Attack technique, which mitigates high-frequency noise and enhances attack efficacy by targeting low-frequency signals. Our approach ensures the protection of audio data without degrading its quality or our ability. Experimental evaluations demonstrate the superiority of our method, achieving a targeted misguidance rate of 96.5% and a remarkable 100% untargeted misguidance rate in obfuscating target keywords across multiple ASR models, including a commercial black-box system from Google. Furthermore, the quality of the recovered audio, measured by the Perceptual Evaluation of Speech Quality score, reached 4.45, comparable to high-quality original recordings. Notably, the recovered audio processed by ASR systems exhibited an error rate of 0%, indicating nearly lossless recovery. These results highlight the practical applicability and effectiveness of our IO-RAE framework in protecting sensitive audio privacy.
Unsourced Adversarial CAPTCHA: A Bi-Phase Adversarial CAPTCHA Framework
Jun 12, 2025
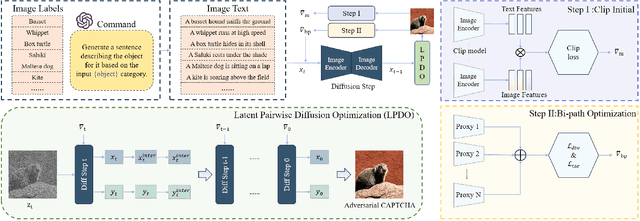

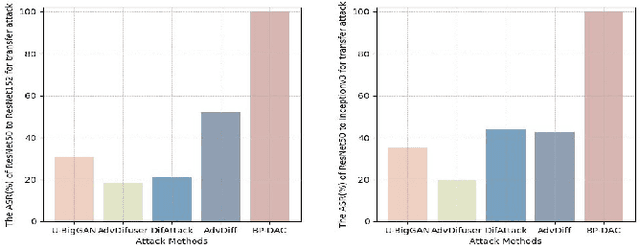
With the rapid advancements in deep learning, traditional CAPTCHA schemes are increasingly vulnerable to automated attacks powered by deep neural networks (DNNs). Existing adversarial attack methods often rely on original image characteristics, resulting in distortions that hinder human interpretation and limit applicability in scenarios lacking initial input images. To address these challenges, we propose the Unsourced Adversarial CAPTCHA (UAC), a novel framework generating high-fidelity adversarial examples guided by attacker-specified text prompts. Leveraging a Large Language Model (LLM), UAC enhances CAPTCHA diversity and supports both targeted and untargeted attacks. For targeted attacks, the EDICT method optimizes dual latent variables in a diffusion model for superior image quality. In untargeted attacks, especially for black-box scenarios, we introduce bi-path unsourced adversarial CAPTCHA (BP-UAC), a two-step optimization strategy employing multimodal gradients and bi-path optimization for efficient misclassification. Experiments show BP-UAC achieves high attack success rates across diverse systems, generating natural CAPTCHAs indistinguishable to humans and DNNs.
DP-TRAE: A Dual-Phase Merging Transferable Reversible Adversarial Example for Image Privacy Protection
May 11, 2025In the field of digital security, Reversible Adversarial Examples (RAE) combine adversarial attacks with reversible data hiding techniques to effectively protect sensitive data and prevent unauthorized analysis by malicious Deep Neural Networks (DNNs). However, existing RAE techniques primarily focus on white-box attacks, lacking a comprehensive evaluation of their effectiveness in black-box scenarios. This limitation impedes their broader deployment in complex, dynamic environments. Further more, traditional black-box attacks are often characterized by poor transferability and high query costs, significantly limiting their practical applicability. To address these challenges, we propose the Dual-Phase Merging Transferable Reversible Attack method, which generates highly transferable initial adversarial perturbations in a white-box model and employs a memory augmented black-box strategy to effectively mislead target mod els. Experimental results demonstrate the superiority of our approach, achieving a 99.0% attack success rate and 100% recovery rate in black-box scenarios, highlighting its robustness in privacy protection. Moreover, we successfully implemented a black-box attack on a commercial model, further substantiating the potential of this approach for practical use.
Beyond Visual Appearances: Privacy-sensitive Objects Identification via Hybrid Graph Reasoning
Jun 18, 2024The Privacy-sensitive Object Identification (POI) task allocates bounding boxes for privacy-sensitive objects in a scene. The key to POI is settling an object's privacy class (privacy-sensitive or non-privacy-sensitive). In contrast to conventional object classes which are determined by the visual appearance of an object, one object's privacy class is derived from the scene contexts and is subject to various implicit factors beyond its visual appearance. That is, visually similar objects may be totally opposite in their privacy classes. To explicitly derive the objects' privacy class from the scene contexts, in this paper, we interpret the POI task as a visual reasoning task aimed at the privacy of each object in the scene. Following this interpretation, we propose the PrivacyGuard framework for POI. PrivacyGuard contains three stages. i) Structuring: an unstructured image is first converted into a structured, heterogeneous scene graph that embeds rich scene contexts. ii) Data Augmentation: a contextual perturbation oversampling strategy is proposed to create slightly perturbed privacy-sensitive objects in a scene graph, thereby balancing the skewed distribution of privacy classes. iii) Hybrid Graph Generation & Reasoning: the balanced, heterogeneous scene graph is then transformed into a hybrid graph by endowing it with extra "node-node" and "edge-edge" homogeneous paths. These homogeneous paths allow direct message passing between nodes or edges, thereby accelerating reasoning and facilitating the capturing of subtle context changes. Based on this hybrid graph... **For the full abstract, see the original paper.**
SHAN: Object-Level Privacy Detection via Inference on Scene Heterogeneous Graph
Mar 14, 2024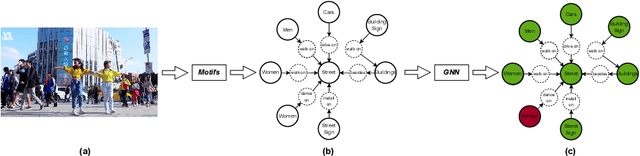
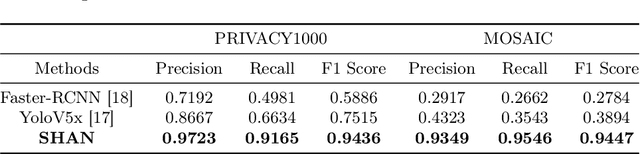

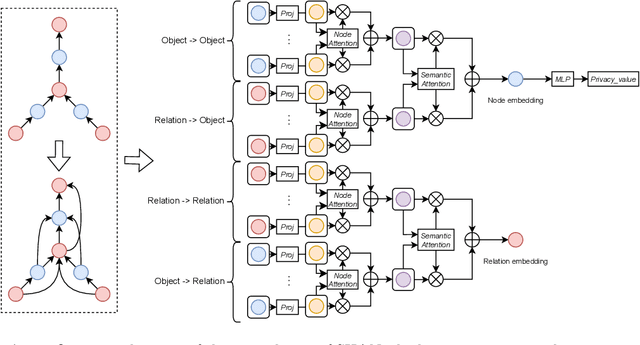
With the rise of social platforms, protecting privacy has become an important issue. Privacy object detection aims to accurately locate private objects in images. It is the foundation of safeguarding individuals' privacy rights and ensuring responsible data handling practices in the digital age. Since privacy of object is not shift-invariant, the essence of the privacy object detection task is inferring object privacy based on scene information. However, privacy object detection has long been studied as a subproblem of common object detection tasks. Therefore, existing methods suffer from serious deficiencies in accuracy, generalization, and interpretability. Moreover, creating large-scale privacy datasets is difficult due to legal constraints and existing privacy datasets lack label granularity. The granularity of existing privacy detection methods remains limited to the image level. To address the above two issues, we introduce two benchmark datasets for object-level privacy detection and propose SHAN, Scene Heterogeneous graph Attention Network, a model constructs a scene heterogeneous graph from an image and utilizes self-attention mechanisms for scene inference to obtain object privacy. Through experiments, we demonstrated that SHAN performs excellently in privacy object detection tasks, with all metrics surpassing those of the baseline model.
Pre-training-free Image Manipulation Localization through Non-Mutually Exclusive Contrastive Learning
Sep 27, 2023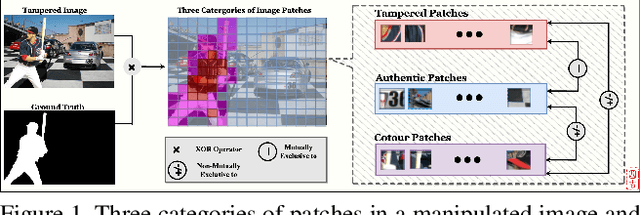

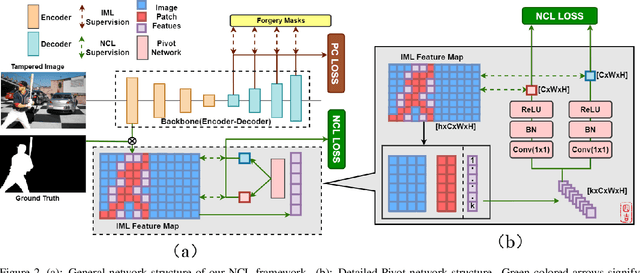

Deep Image Manipulation Localization (IML) models suffer from training data insufficiency and thus heavily rely on pre-training. We argue that contrastive learning is more suitable to tackle the data insufficiency problem for IML. Crafting mutually exclusive positives and negatives is the prerequisite for contrastive learning. However, when adopting contrastive learning in IML, we encounter three categories of image patches: tampered, authentic, and contour patches. Tampered and authentic patches are naturally mutually exclusive, but contour patches containing both tampered and authentic pixels are non-mutually exclusive to them. Simply abnegating these contour patches results in a drastic performance loss since contour patches are decisive to the learning outcomes. Hence, we propose the Non-mutually exclusive Contrastive Learning (NCL) framework to rescue conventional contrastive learning from the above dilemma. In NCL, to cope with the non-mutually exclusivity, we first establish a pivot structure with dual branches to constantly switch the role of contour patches between positives and negatives while training. Then, we devise a pivot-consistent loss to avoid spatial corruption caused by the role-switching process. In this manner, NCL both inherits the self-supervised merits to address the data insufficiency and retains a high manipulation localization accuracy. Extensive experiments verify that our NCL achieves state-of-the-art performance on all five benchmarks without any pre-training and is more robust on unseen real-life samples. The code is available at: https://github.com/Knightzjz/NCL-IML.