 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically-Induced Atmospheric Adversarial Perturbations: Enhancing Transferability and Robustness in Remote Sensing Image Classification
Apr 16, 2026Adversarial attacks pose a severe threat to the reliability of deep learning models in remote sensing (RS) image classification. Most existing methods rely on direct pixel-wise perturbations, failing to exploit the inherent atmospheric characteristics of RS imagery or survive real-world image degradations. In this paper, we propose FogFool, a physically plausible adversarial framework that generates fog-based perturbations by iteratively optimizing atmospheric patterns based on Perlin noise. By modeling fog formations with natural, irregular structures, FogFool generates adversarial examples that are not only visually consistent with authentic RS scenes but also deceptive. By leveraging the spatial coherence and mid-to-low-frequency nature of atmospheric phenomena, FogFool embeds adversarial information into structural features shared across diverse architectures. Extensive experiments on two benchmark RS datasets demonstrate that FogFool achieves superior performance: not only does it exceed in white-box settings, but also exhibits exceptional black-box transferability (reaching 83.74% TASR) and robustness against common preprocessing-based defenses such as JPEG compression and filtering. Detailed analyses, including confusion matrices and Class Activation Map (CAM) visualizations, reveal that our atmospheric-driven perturbations induce a universal shift in model attention. These results indicate that FogFool represents a practical, stealthy, and highly persistent threat to RS classification systems, providing a robust benchmark for evaluating model reliability in complex environments.
Adaptive Image Zoom-in with Bounding Box Transformation for UAV Object Detection
Feb 07, 2026Detecting objects from UAV-captured images is challenging due to the small object size. In this work, a simple and efficient adaptive zoom-in framework is explored for object detection on UAV images. The main motivation is that the foreground objects are generally smaller and sparser than those in common scene images, which hinders the optimization of effective object detectors. We thus aim to zoom in adaptively on the objects to better capture object features for the detection task. To achieve the goal, two core designs are required: \textcolor{black}{i) How to conduct non-uniform zooming on each image efficiently? ii) How to enable object detection training and inference with the zoomed image space?} Correspondingly, a lightweight offset prediction scheme coupled with a novel box-based zooming objective is introduced to learn non-uniform zooming on the input image. Based on the learned zooming transformation, a corner-aligned bounding box transformation method is proposed. The method warps the ground-truth bounding boxes to the zoomed space to learn object detection, and warps the predicted bounding boxes back to the original space during inference. We conduct extensive experiments on three representative UAV object detection datasets, including VisDrone, UAVDT, and SeaDronesSee. The proposed ZoomDet is architecture-independent and can be applied to an arbitrary object detection architecture. Remarkably, on the SeaDronesSee dataset, ZoomDet offers more than 8.4 absolute gain of mAP with a Faster R-CNN model, with only about 3 ms additional latency. The code is available at https://github.com/twangnh/zoomdet_code.
SIDeR: Semantic Identity Decoupling for Unrestricted Face Privacy
Feb 04, 2026With the deep integration of facial recognition into online banking, identity verification, and other networked services, achieving effective decoupling of identity information from visual representations during image storage and transmission has become a critical challenge for privacy protection. To address this issue, we propose SIDeR, a Semantic decoupling-driven framework for unrestricted face privacy protection. SIDeR decomposes a facial image into a machine-recognizable identity feature vector and a visually perceptible semantic appearance component. By leveraging semantic-guided recomposition in the latent space of a diffusion model, it generates visually anonymous adversarial faces while maintaining machine-level identity consistency. The framework incorporates momentum-driven unrestricted perturbation optimization and a semantic-visual balancing factor to synthesize multiple visually diverse, highly natural adversarial samples. Furthermore, for authorized access, the protected image can be restored to its original form when the correct password is provided. Extensive experiments on the CelebA-HQ and FFHQ datasets demonstrate that SIDeR achieves a 99% attack success rate in black-box scenarios and outperforms baseline methods by 41.28% in PSNR-based restoration quality.
IO-RAE: Information-Obfuscation Reversible Adversarial Example for Audio Privacy Protection
Jan 03, 2026The rapid advancements in artificial intelligence have significantly accelerated the adoption of speech recognition technology, leading to its widespread integration across various applications. However, this surge in usage also highlights a critical issue: audio data is highly vulnerable to unauthorized exposure and analysis, posing significant privacy risks for businesses and individuals. This paper introduces an Information-Obfuscation Reversible Adversarial Example (IO-RAE) framework, the pioneering method designed to safeguard audio privacy using reversible adversarial examples. IO-RAE leverages large language models to generate misleading yet contextually coherent content, effectively preventing unauthorized eavesdropping by humans and Automatic Speech Recognition (ASR) systems. Additionally, we propose the Cumulative Signal Attack technique, which mitigates high-frequency noise and enhances attack efficacy by targeting low-frequency signals. Our approach ensures the protection of audio data without degrading its quality or our ability. Experimental evaluations demonstrate the superiority of our method, achieving a targeted misguidance rate of 96.5% and a remarkable 100% untargeted misguidance rate in obfuscating target keywords across multiple ASR models, including a commercial black-box system from Google. Furthermore, the quality of the recovered audio, measured by the Perceptual Evaluation of Speech Quality score, reached 4.45, comparable to high-quality original recordings. Notably, the recovered audio processed by ASR systems exhibited an error rate of 0%, indicating nearly lossless recovery. These results highlight the practical applicability and effectiveness of our IO-RAE framework in protecting sensitive audio privacy.
Synthesizing Sheet Music Problems for Evaluation and Reinforcement Learning
Sep 04, 2025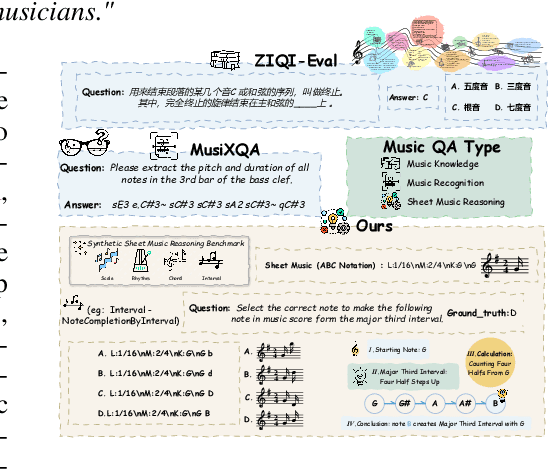

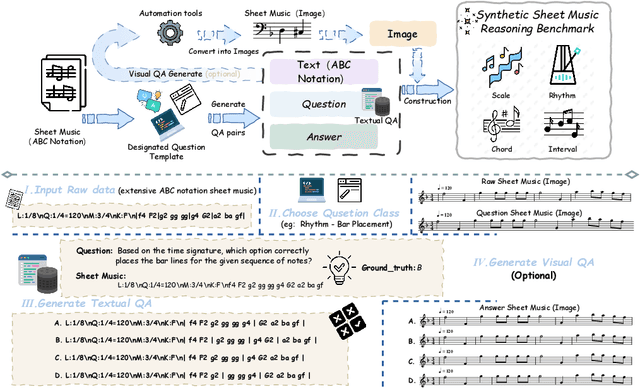
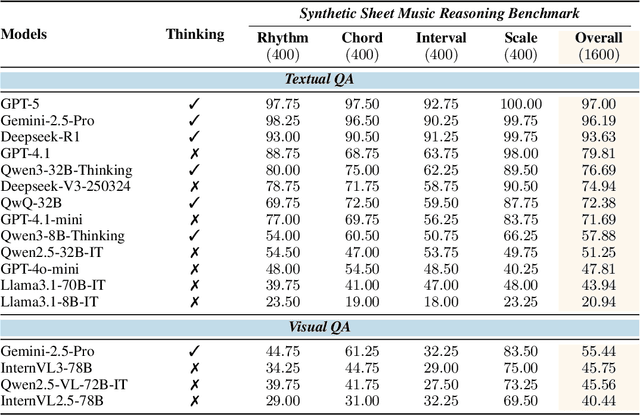
Enhancing the ability of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) to interpret sheet music is a crucial step toward building AI musicians. However, current research lacks both evaluation benchmarks and training data for sheet music reasoning. To address this, we propose the idea of synthesizing sheet music problems grounded in music theory, which can serve both as evaluation benchmarks and as training data for reinforcement learning with verifiable rewards (RLVR). We introduce a data synthesis framework that generates verifiable sheet music questions in both textual and visual modalities, leading to the Synthetic Sheet Music Reasoning Benchmark (SSMR-Bench) and a complementary training set. Evaluation results on SSMR-Bench show the importance of models' reasoning abilities in interpreting sheet music. At the same time, the poor performance of Gemini 2.5-Pro highlights the challenges that MLLMs still face in interpreting sheet music in a visual format. By leveraging synthetic data for RLVR, Qwen3-8B-Base and Qwen2.5-VL-Instruct achieve improvements on the SSMR-Bench. Besides, the trained Qwen3-8B-Base surpasses GPT-4 in overall performance on MusicTheoryBench and achieves reasoning performance comparable to GPT-4 with the strategies of Role play and Chain-of-Thought. Notably, its performance on math problems also improves relative to the original Qwen3-8B-Base. Furthermore, our results show that the enhanced reasoning ability can also facilitate music composition. In conclusion, we are the first to propose the idea of synthesizing sheet music problems based on music theory rules, and demonstrate its effectiveness not only in advancing model reasoning for sheet music understanding but also in unlocking new possibilities for AI-assisted music creation.
Unsourced Adversarial CAPTCHA: A Bi-Phase Adversarial CAPTCHA Framework
Jun 12, 2025
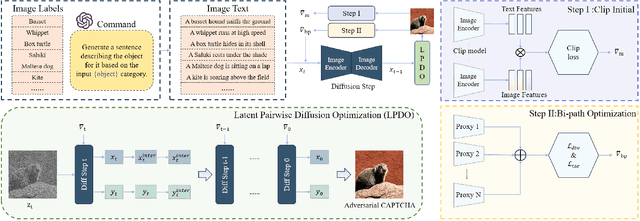

With the rapid advancements in deep learning, traditional CAPTCHA schemes are increasingly vulnerable to automated attacks powered by deep neural networks (DNNs). Existing adversarial attack methods often rely on original image characteristics, resulting in distortions that hinder human interpretation and limit applicability in scenarios lacking initial input images. To address these challenges, we propose the Unsourced Adversarial CAPTCHA (UAC), a novel framework generating high-fidelity adversarial examples guided by attacker-specified text prompts. Leveraging a Large Language Model (LLM), UAC enhances CAPTCHA diversity and supports both targeted and untargeted attacks. For targeted attacks, the EDICT method optimizes dual latent variables in a diffusion model for superior image quality. In untargeted attacks, especially for black-box scenarios, we introduce bi-path unsourced adversarial CAPTCHA (BP-UAC), a two-step optimization strategy employing multimodal gradients and bi-path optimization for efficient misclassification. Experiments show BP-UAC achieves high attack success rates across diverse systems, generating natural CAPTCHAs indistinguishable to humans and DNNs.
ForensicHub: A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization
May 16, 2025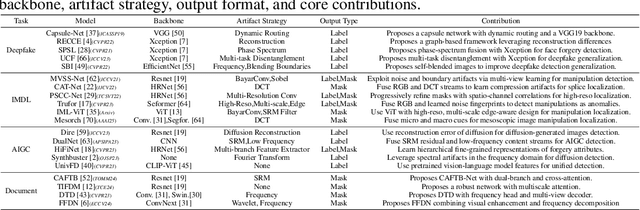
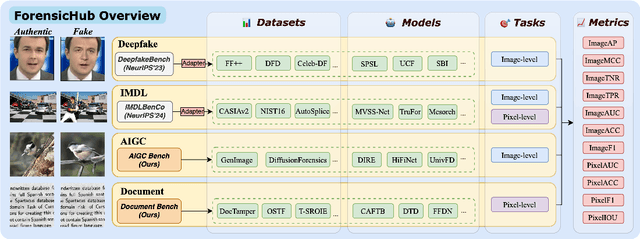
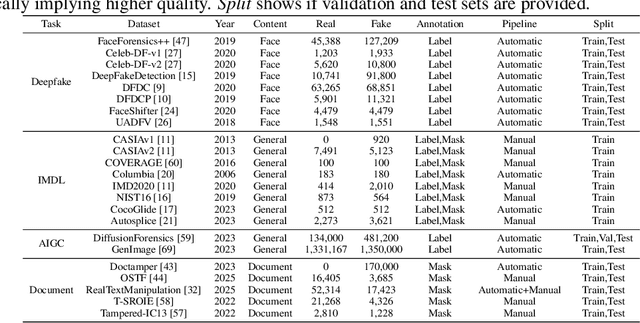
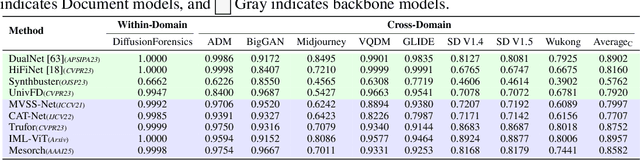
The field of Fake Image Detection and Localization (FIDL) is highly fragmented, encompassing four domains: deepfake detection (Deepfake), image manipulation detection and localization (IMDL), artificial intelligence-generated image detection (AIGC), and document image manipulation localization (Doc). Although individual benchmarks exist in some domains, a unified benchmark for all domains in FIDL remains blank. The absence of a unified benchmark results in significant domain silos, where each domain independently constructs its datasets, models, and evaluation protocols without interoperability, preventing cross-domain comparisons and hindering the development of the entire FIDL field. To close the domain silo barrier, we propose ForensicHub, the first unified benchmark & codebase for all-domain fake image detection and localization. Considering drastic variations on dataset, model, and evaluation configurations across all domains, as well as the scarcity of open-sourced baseline models and the lack of individual benchmarks in some domains, ForensicHub: i) proposes a modular and configuration-driven architecture that decomposes forensic pipelines into interchangeable components across datasets, transforms, models, and evaluators, allowing flexible composition across all domains; ii) fully implements 10 baseline models, 6 backbones, 2 new benchmarks for AIGC and Doc, and integrates 2 existing benchmarks of DeepfakeBench and IMDLBenCo through an adapter-based design; iii) conducts indepth analysis based on the ForensicHub, offering 8 key actionable insights into FIDL model architecture, dataset characteristics, and evaluation standards. ForensicHub represents a significant leap forward in breaking the domain silos in the FIDL field and inspiring future breakthroughs.
DP-TRAE: A Dual-Phase Merging Transferable Reversible Adversarial Example for Image Privacy Protection
May 11, 2025In the field of digital security, Reversible Adversarial Examples (RAE) combine adversarial attacks with reversible data hiding techniques to effectively protect sensitive data and prevent unauthorized analysis by malicious Deep Neural Networks (DNNs). However, existing RAE techniques primarily focus on white-box attacks, lacking a comprehensive evaluation of their effectiveness in black-box scenarios. This limitation impedes their broader deployment in complex, dynamic environments. Further more, traditional black-box attacks are often characterized by poor transferability and high query costs, significantly limiting their practical applicability. To address these challenges, we propose the Dual-Phase Merging Transferable Reversible Attack method, which generates highly transferable initial adversarial perturbations in a white-box model and employs a memory augmented black-box strategy to effectively mislead target mod els. Experimental results demonstrate the superiority of our approach, achieving a 99.0% attack success rate and 100% recovery rate in black-box scenarios, highlighting its robustness in privacy protection. Moreover, we successfully implemented a black-box attack on a commercial model, further substantiating the potential of this approach for practical use.
EBAD-Gaussian: Event-driven Bundle Adjusted Deblur Gaussian Splatting
Apr 14, 2025While 3D Gaussian Splatting (3D-GS) achieves photorealistic novel view synthesis, its performance degrades with motion blur. In scenarios with rapid motion or low-light conditions, existing RGB-based deblurring methods struggle to model camera pose and radiance changes during exposure, reducing reconstruction accuracy. Event cameras, capturing continuous brightness changes during exposure, can effectively assist in modeling motion blur and improving reconstruction quality. Therefore, we propose Event-driven Bundle Adjusted Deblur Gaussian Splatting (EBAD-Gaussian), which reconstructs sharp 3D Gaussians from event streams and severely blurred images. This method jointly learns the parameters of these Gaussians while recovering camera motion trajectories during exposure time. Specifically, we first construct a blur loss function by synthesizing multiple latent sharp images during the exposure time, minimizing the difference between real and synthesized blurred images. Then we use event stream to supervise the light intensity changes between latent sharp images at any time within the exposure period, supplementing the light intensity dynamic changes lost in RGB images. Furthermore, we optimize the latent sharp images at intermediate exposure times based on the event-based double integral (EDI) prior, applying consistency constraints to enhance the details and texture information of the reconstructed images. Extensive experiments on synthetic and real-world datasets show that EBAD-Gaussian can achieve high-quality 3D scene reconstruction under the condition of blurred images and event stream inputs.
Style Quantization for Data-Efficient GAN Training
Mar 31, 2025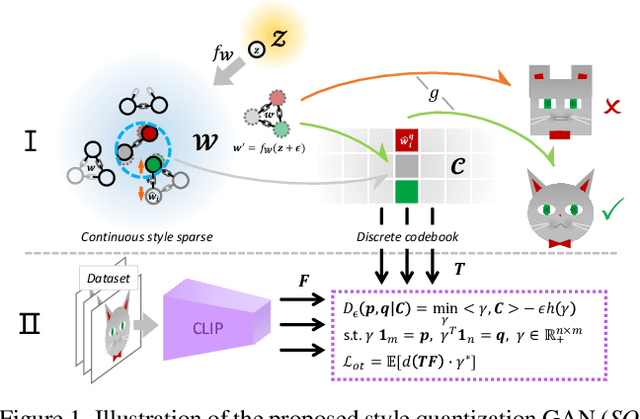
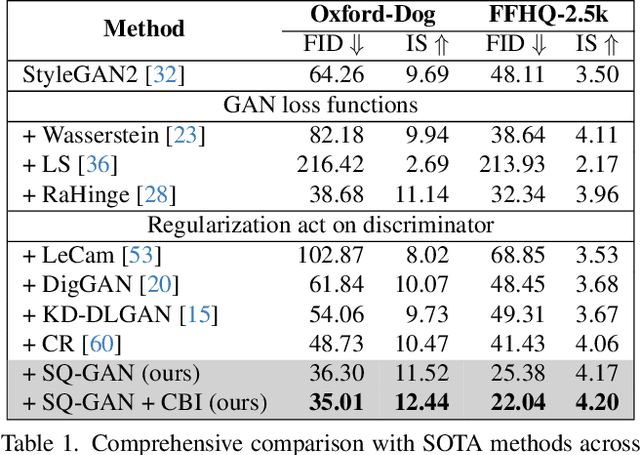
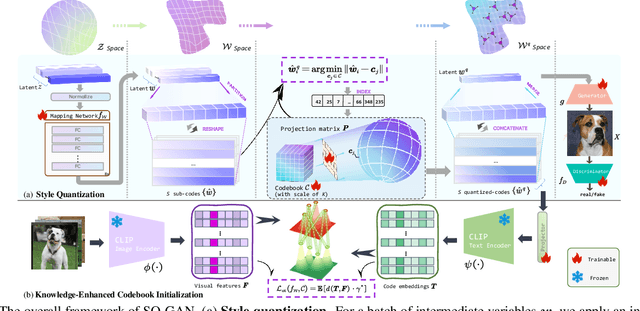
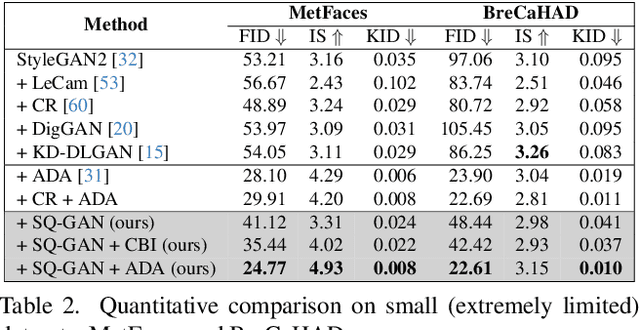
Under limited data setting, GANs often struggle to navigate and effectively exploit the input latent space. Consequently, images generated from adjacent variables in a sparse input latent space may exhibit significant discrepancies in realism, leading to suboptimal consistency regularization (CR) outcomes. To address this, we propose \textit{SQ-GAN}, a novel approach that enhances CR by introducing a style space quantization scheme. This method transforms the sparse, continuous input latent space into a compact, structured discrete proxy space, allowing each element to correspond to a specific real data point, thereby improving CR performance. Instead of direct quantization, we first map the input latent variables into a less entangled ``style'' space and apply quantization using a learnable codebook. This enables each quantized code to control distinct factors of variation. Additionally, we optimize the optimal transport distance to align the codebook codes with features extracted from the training data by a foundation model, embedding external knowledge into the codebook and establishing a semantically rich vocabulary that properly describes the training dataset. Extensive experiments demonstrate significant improvements in both discriminator robustness and generation quality with our method.