 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacmap: Bridging the Tactile Sim-to-Real Gap via Geometry-Consistent Penetration Depth Map
Feb 25, 2026Vision-Based Tactile Sensors (VBTS) are essential for achieving dexterous robotic manipulation, yet the tactile sim-to-real gap remains a fundamental bottleneck. Current tactile simulations suffer from a persistent dilemma: simplified geometric projections lack physical authenticity, while high-fidelity Finite Element Methods (FEM) are too computationally prohibitive for large-scale reinforcement learning. In this work, we present Tacmap, a high-fidelity, computationally efficient tactile simulation framework anchored in volumetric penetration depth. Our key insight is to bridge the tactile sim-to-real gap by unifying both domains through a shared deform map representation. Specifically, we compute 3D intersection volumes as depth maps in simulation, while in the real world, we employ an automated data-collection rig to learn a robust mapping from raw tactile images to ground-truth depth maps. By aligning simulation and real-world in this unified geometric space, Tacmap minimizes domain shift while maintaining physical consistency. Quantitative evaluations across diverse contact scenarios demonstrate that Tacmap's deform maps closely mirror real-world measurements. Moreover, we validate the utility of Tacmap through an in-hand rotation task, where a policy trained exclusively in simulation achieves zero-shot transfer to a physical robot.
Position-Prior-Guided Network for System Matrix Super-Resolution in Magnetic Particle Imaging
Nov 08, 2025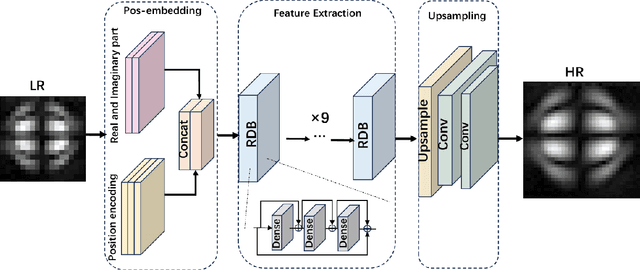
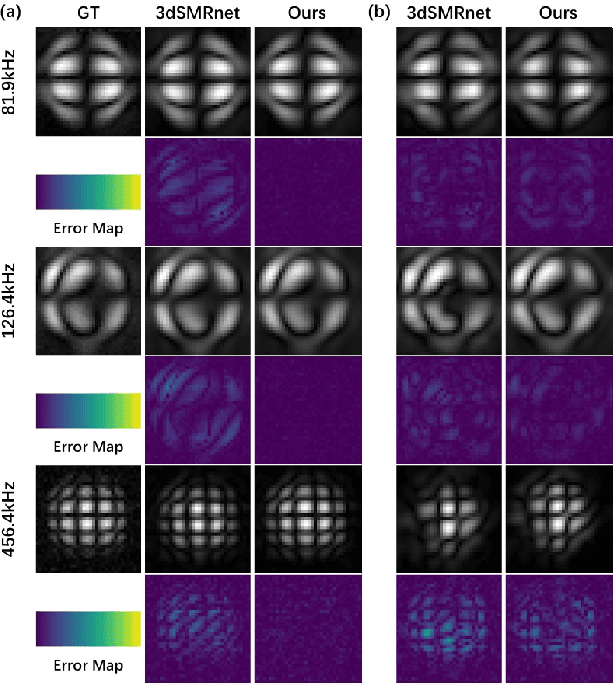
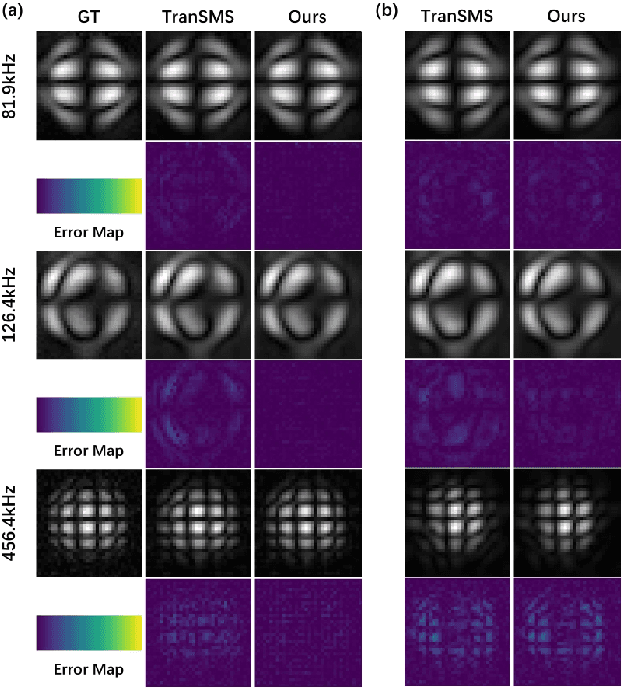
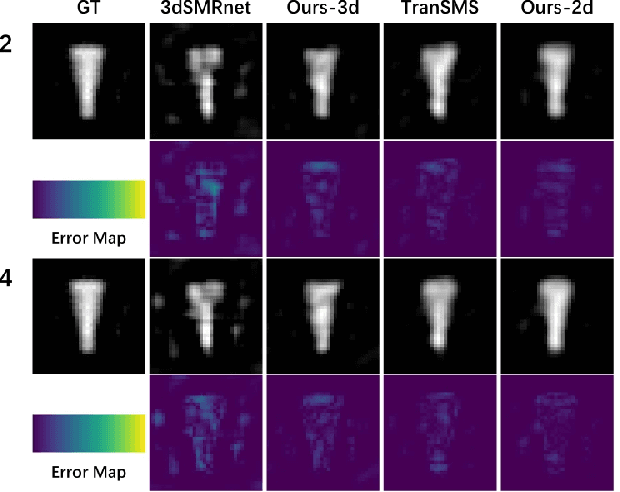
Magnetic Particle Imaging (MPI) is a novel medical imaging modality. One of the established methods for MPI reconstruction is based on the System Matrix (SM). However, the calibration of the SM is often time-consuming and requires repeated measurements whenever the system parameters change. Current methodologies utilize deep learning-based super-resolution (SR) techniques to expedite SM calibration; nevertheless, these strategies do not fully exploit physical prior knowledge associated with the SM, such as symmetric positional priors. Consequently, we integrated positional priors into existing frameworks for SM calibration. Underpinned by theoretical justification, we empirically validated the efficacy of incorporating positional priors through experiments involving both 2D and 3D SM SR methods.
GNCAF: A GNN-based Neighboring Context Aggregation Framework for Tertiary Lymphoid Structures Semantic Segmentation in WSI
May 13, 2025Tertiary lymphoid structures (TLS) are organized clusters of immune cells, whose maturity and area can be quantified in whole slide image (WSI) for various prognostic tasks. Existing methods for assessing these characteristics typically rely on cell proxy tasks and require additional post-processing steps. In this work, We focus on a novel task-TLS Semantic Segmentation (TLS-SS)-which segments both the regions and maturation stages of TLS in WSI in an end-to-end manner. Due to the extensive scale of WSI and patch-based segmentation strategies, TLS-SS necessitates integrating from neighboring patches to guide target patch (target) segmentation. Previous techniques often employ on multi-resolution approaches, constraining the capacity to leverage the broader neighboring context while tend to preserve coarse-grained information. To address this, we propose a GNN-based Neighboring Context Aggregation Framework (GNCAF), which progressively aggregates multi-hop neighboring context from the target and employs a self-attention mechanism to guide the segmentation of the target. GNCAF can be integrated with various segmentation models to enhance their ability to perceive contextual information outside of the patch. We build two TLS-SS datasets, called TCGA-COAD and INHOUSE-PAAD, and make the former (comprising 225 WSIs and 5041 TLSs) publicly available. Experiments on these datasets demonstrate the superiority of GNCAF, achieving a maximum of 22.08% and 26.57% improvement in mF1 and mIoU, respectively. Additionally, we also validate the task scalability of GNCAF on segmentation of lymph node metastases.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Memory Analysis on the Training Course of DeepSeek Models
Feb 11, 2025


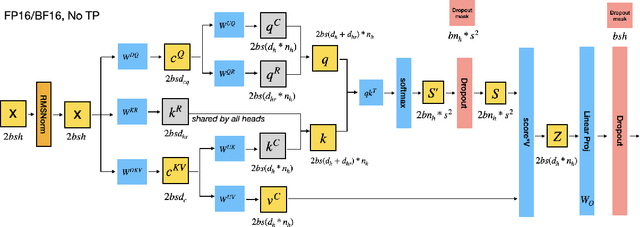
We present a theoretical analysis of GPU memory consumption during the training of DeepSeek models such as DeepSeek-v2 and DeepSeek-v3. Our primary objective is to clarify the device-level memory requirements associated with various distributed training configurations. Specifically, we examine critical factors influencing memory usage, including micro-batch size, activation recomputation policies, 3D parallelism, and ZeRO optimizations. It is important to emphasize that the training policies discussed in this report are not representative of DeepSeek's official configurations. Instead, they are explored to provide a deeper understanding of memory dynamics in training of large-scale mixture-of-experts model.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization Through Spare-Coding Transformer
Dec 19, 2024
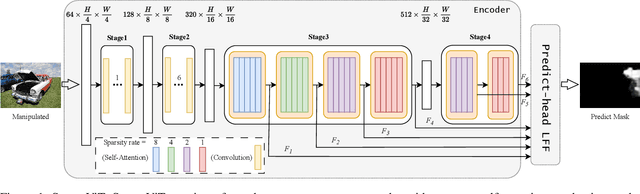
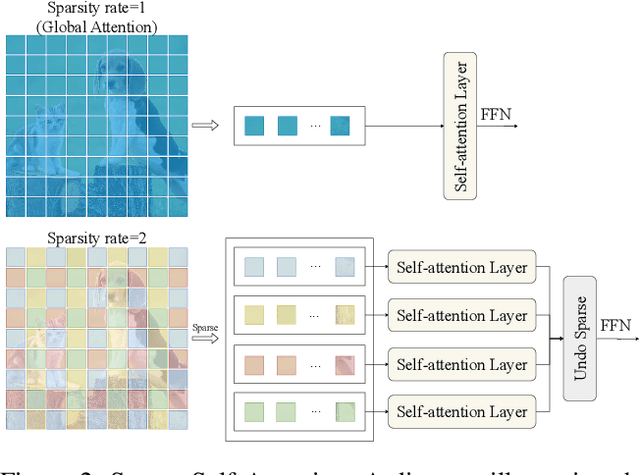
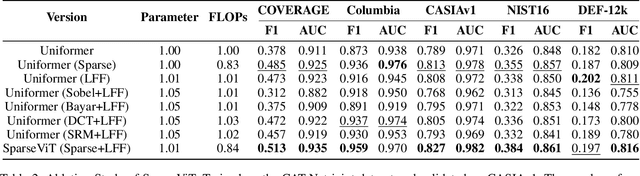
Non-semantic features or semantic-agnostic features, which are irrelevant to image context but sensitive to image manipulations, are recognized as evidential to Image Manipulation Localization (IML). Since manual labels are impossible, existing works rely on handcrafted methods to extract non-semantic features. Handcrafted non-semantic features jeopardize IML model's generalization ability in unseen or complex scenarios. Therefore, for IML, the elephant in the room is: How to adaptively extract non-semantic features? Non-semantic features are context-irrelevant and manipulation-sensitive. That is, within an image, they are consistent across patches unless manipulation occurs. Then, spare and discrete interactions among image patches are sufficient for extracting non-semantic features. However, image semantics vary drastically on different patches, requiring dense and continuous interactions among image patches for learning semantic representations. Hence, in this paper, we propose a Sparse Vision Transformer (SparseViT), which reformulates the dense, global self-attention in ViT into a sparse, discrete manner. Such sparse self-attention breaks image semantics and forces SparseViT to adaptively extract non-semantic features for images. Besides, compared with existing IML models, the sparse self-attention mechanism largely reduced the model size (max 80% in FLOPs), achieving stunning parameter efficiency and computation reduction. Extensive experiments demonstrate that, without any handcrafted feature extractors, SparseViT is superior in both generalization and efficiency across benchmark datasets.
Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization
Dec 18, 2024



The mesoscopic level serves as a bridge between the macroscopic and microscopic worlds, addressing gaps overlooked by both. Image manipulation localization (IML), a crucial technique to pursue truth from fake images, has long relied on low-level (microscopic-level) traces. However, in practice, most tampering aims to deceive the audience by altering image semantics. As a result, manipulation commonly occurs at the object level (macroscopic level), which is equally important as microscopic traces. Therefore, integrating these two levels into the mesoscopic level presents a new perspective for IML research. Inspired by this, our paper explores how to simultaneously construct mesoscopic representations of micro and macro information for IML and introduces the Mesorch architecture to orchestrate both. Specifically, this architecture i) combines Transformers and CNNs in parallel, with Transformers extracting macro information and CNNs capturing micro details, and ii) explores across different scales, assessing micro and macro information seamlessly. Additionally, based on the Mesorch architecture, the paper introduces two baseline models aimed at solving IML tasks through mesoscopic representation. Extensive experiments across four datasets have demonstrated that our models surpass the current state-of-the-art in terms of performance, computational complexity, and robustness.
GCUNet: A GNN-Based Contextual Learning Network for Tertiary Lymphoid Structure Semantic Segmentation in Whole Slide Image
Dec 09, 2024We focus on tertiary lymphoid structure (TLS) semantic segmentation in whole slide image (WSI). Unlike TLS binary segmentation, TLS semantic segmentation identifies boundaries and maturity, which requires integrating contextual information to discover discriminative features. Due to the extensive scale of WSI (e.g., 100,000 \times 100,000 pixels), the segmentation of TLS is usually carried out through a patch-based strategy. However, this prevents the model from accessing information outside of the patches, limiting the performance. To address this issue, we propose GCUNet, a GNN-based contextual learning network for TLS semantic segmentation. Given an image patch (target) to be segmented, GCUNet first progressively aggregates long-range and fine-grained context outside the target. Then, a Detail and Context Fusion block (DCFusion) is designed to integrate the context and detail of the target to predict the segmentation mask. We build four TLS semantic segmentation datasets, called TCGA-COAD, TCGA-LUSC, TCGA-BLCA and INHOUSE-PAAD, and make the former three datasets (comprising 826 WSIs and 15,276 TLSs) publicly available to promote the TLS semantic segmentation. Experiments on these datasets demonstrate the superiority of GCUNet, achieving at least 7.41% improvement in mF1 compared with SOTA.
Comprehensive Performance Evaluation of YOLOv11, YOLOv10, YOLOv9, YOLOv8 and YOLOv5 on Object Detection of Power Equipment
Nov 28, 2024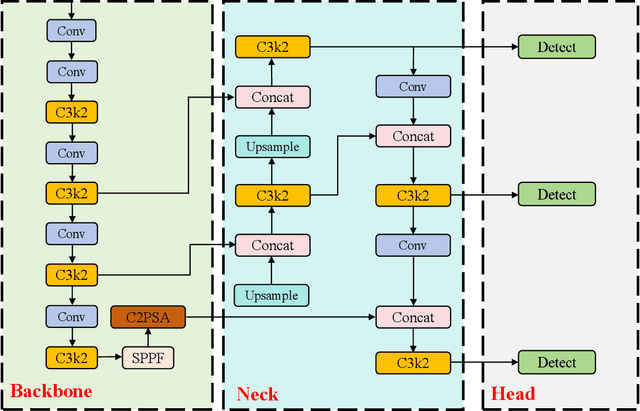


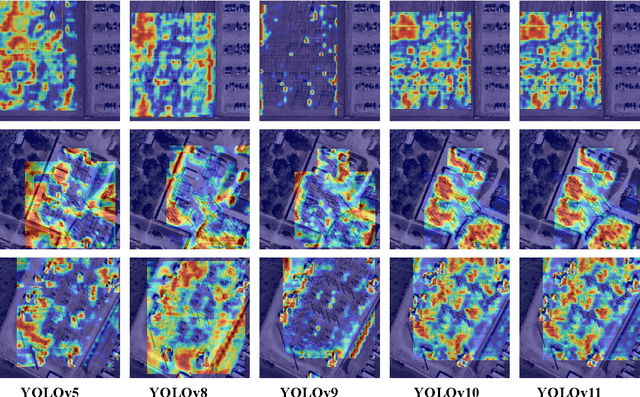
With the rapid development of global industrial production, the demand for reliability in power equipment has been continuously increasing. Ensuring the stability of power system operations requires accurate methods to detect potential faults in power equipment, thereby guaranteeing the normal supply of electrical energy. In this article, the performance of YOLOv5, YOLOv8, YOLOv9, YOLOv10, and the state-of-the-art YOLOv11 methods was comprehensively evaluated for power equipment object detection. Experimental results demonstrate that the mean average precision (mAP) on a public dataset for power equipment was 54.4%, 55.5%, 43.8%, 48.0%, and 57.2%, respectively, with the YOLOv11 achieving the highest detection performance. Moreover, the YOLOv11 outperformed other methods in terms of recall rate and exhibited superior performance in reducing false detections. In conclusion, the findings indicate that the YOLOv11 model provides a reliable and effective solution for power equipment object detection, representing a promising approach to enhancing the operational reliability of power systems.