 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM2CT: MR-to-CT translation for multi-modal image fusion with mamba
Aug 07, 2025Magnetic resonance (MR)-to-computed tomography (CT) translation offers significant advantages, including the elimination of radiation exposure associated with CT scans and the mitigation of imaging artifacts caused by patient motion. The existing approaches are based on single-modality MR-to-CT translation, with limited research exploring multimodal fusion. To address this limitation, we introduce Multi-modal MR to CT (MM2CT) translation method by leveraging multimodal T1- and T2-weighted MRI data, an innovative Mamba-based framework for multi-modal medical image synthesis. Mamba effectively overcomes the limited local receptive field in CNNs and the high computational complexity issues in Transformers. MM2CT leverages this advantage to maintain long-range dependencies modeling capabilities while achieving multi-modal MR feature integration. Additionally, we incorporate a dynamic local convolution module and a dynamic enhancement module to improve MRI-to-CT synthesis. The experiments on a public pelvis dataset demonstrate that MM2CT achieves state-of-the-art performance in terms of Structural Similarity Index Measure (SSIM) and Peak Signal-to-Noise Ratio (PSNR). Our code is publicly available at https://github.com/Gots-ch/MM2CT.
F2PASeg: Feature Fusion for Pituitary Anatomy Segmentation in Endoscopic Surgery
Aug 07, 2025Pituitary tumors often cause deformation or encapsulation of adjacent vital structures. Anatomical structure segmentation can provide surgeons with early warnings of regions that pose surgical risks, thereby enhancing the safety of pituitary surgery. However, pixel-level annotated video stream datasets for pituitary surgeries are extremely rare. To address this challenge, we introduce a new dataset for Pituitary Anatomy Segmentation (PAS). PAS comprises 7,845 time-coherent images extracted from 120 videos. To mitigate class imbalance, we apply data augmentation techniques that simulate the presence of surgical instruments in the training data. One major challenge in pituitary anatomy segmentation is the inconsistency in feature representation due to occlusions, camera motion, and surgical bleeding. By incorporating a Feature Fusion module, F2PASeg is proposed to refine anatomical structure segmentation by leveraging both high-resolution image features and deep semantic embeddings, enhancing robustness against intraoperative variations. Experimental results demonstrate that F2PASeg consistently segments critical anatomical structures in real time, providing a reliable solution for intraoperative pituitary surgery planning. Code: https://github.com/paulili08/F2PASeg.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
INT-FlashAttention: Enabling Flash Attention for INT8 Quantization
Sep 26, 2024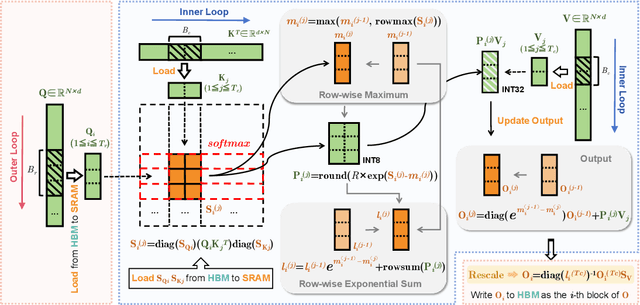
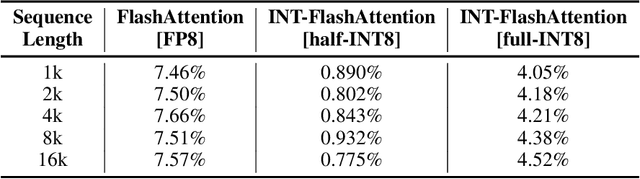
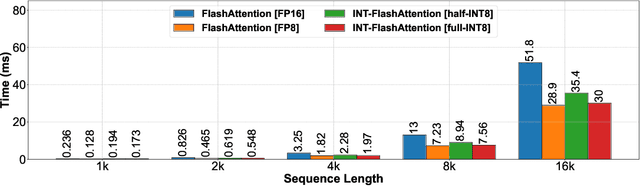
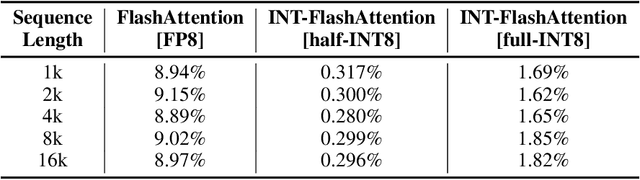
As the foundation of large language models (LLMs), self-attention module faces the challenge of quadratic time and memory complexity with respect to sequence length. FlashAttention accelerates attention computation and reduces its memory usage by leveraging the GPU memory hierarchy. A promising research direction is to integrate FlashAttention with quantization methods. This paper introduces INT-FlashAttention, the first INT8 quantization architecture compatible with the forward workflow of FlashAttention, which significantly improves the inference speed of FlashAttention on Ampere GPUs. We implement our INT-FlashAttention prototype with fully INT8 activations and general matrix-multiplication (GEMM) kernels, making it the first attention operator with fully INT8 input. As a general token-level post-training quantization framework, INT-FlashAttention is also compatible with other data formats like INT4, etc. Experimental results show INT-FlashAttention achieves 72% faster inference speed and 82% smaller quantization error compared to standard FlashAttention with FP16 and FP8 data format.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.