 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-Audio: A Unified Framework for End-to-End Speech Interaction
Feb 24, 2025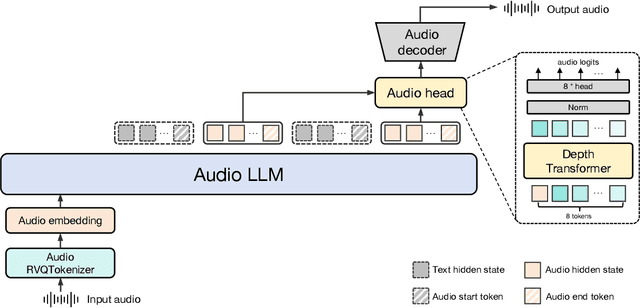
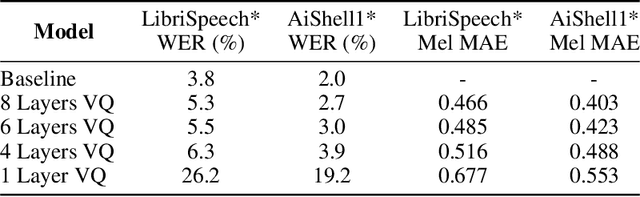
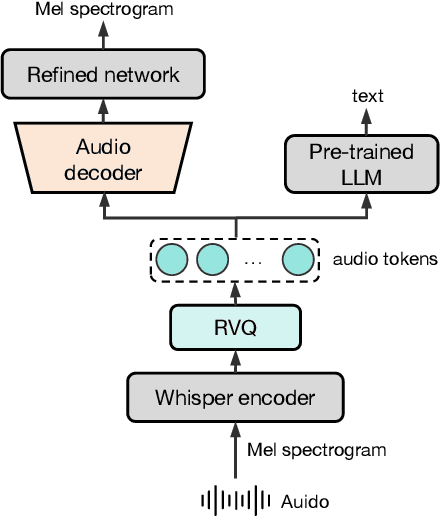
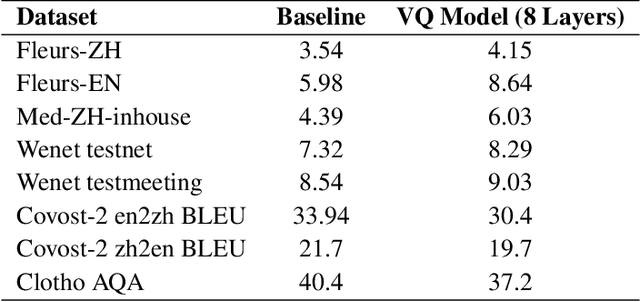
We introduce Baichuan-Audio, an end-to-end audio large language model that seamlessly integrates audio understanding and generation. It features a text-guided aligned speech generation mechanism, enabling real-time speech interaction with both comprehension and generation capabilities. Baichuan-Audio leverages a pre-trained ASR model, followed by multi-codebook discretization of speech at a frame rate of 12.5 Hz. This multi-codebook setup ensures that speech tokens retain both semantic and acoustic information. To further enhance modeling, an independent audio head is employed to process audio tokens, effectively capturing their unique characteristics. To mitigate the loss of intelligence during pre-training and preserve the original capabilities of the LLM, we propose a two-stage pre-training strategy that maintains language understanding while enhancing audio modeling. Following alignment, the model excels in real-time speech-based conversation and exhibits outstanding question-answering capabilities, demonstrating its versatility and efficiency. The proposed model demonstrates superior performance in real-time spoken dialogue and exhibits strong question-answering abilities. Our code, model and training data are available at https://github.com/baichuan-inc/Baichuan-Audio
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Med-R$^2$: Crafting Trustworthy LLM Physicians through Retrieval and Reasoning of Evidence-Based Medicine
Jan 21, 2025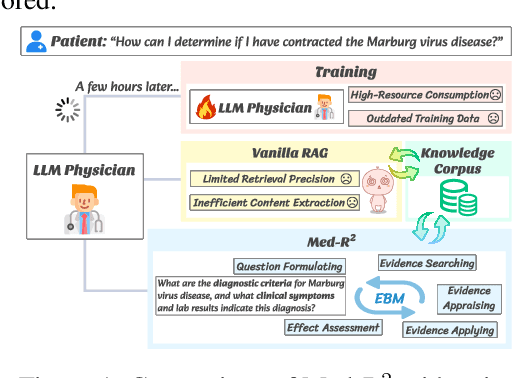
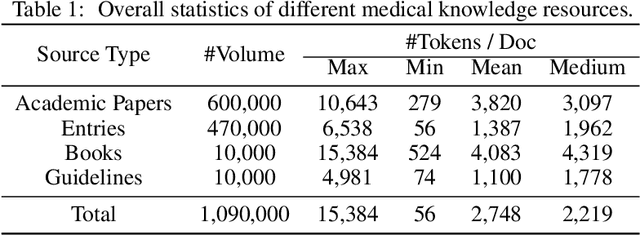
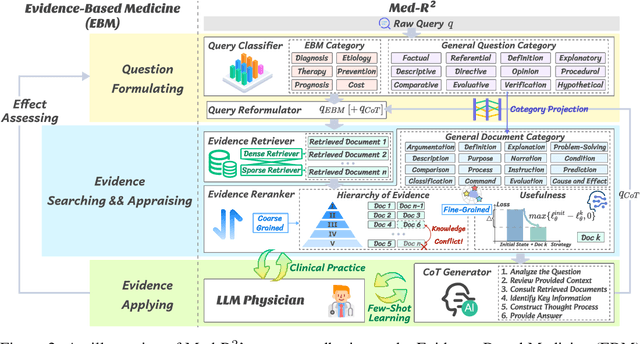
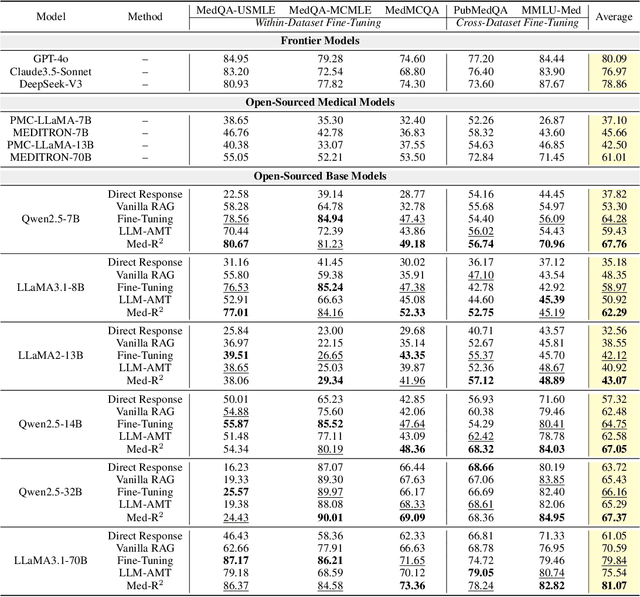
In recent years, Large Language Models (LLMs) have exhibited remarkable capabilities in clinical scenarios. However, despite their potential, existing works face challenges when applying LLMs to medical settings. Strategies relying on training with medical datasets are highly cost-intensive and may suffer from outdated training data. Leveraging external knowledge bases is a suitable alternative, yet it faces obstacles such as limited retrieval precision and poor effectiveness in answer extraction. These issues collectively prevent LLMs from demonstrating the expected level of proficiency in mastering medical expertise. To address these challenges, we introduce Med-R^2, a novel LLM physician framework that adheres to the Evidence-Based Medicine (EBM) process, efficiently integrating retrieval mechanisms as well as the selection and reasoning processes of evidence, thereby enhancing the problem-solving capabilities of LLMs in healthcare scenarios and fostering a trustworthy LLM physician. Our comprehensive experiments indicate that Med-R^2 achieves a 14.87\% improvement over vanilla RAG methods and even a 3.59\% enhancement compared to fine-tuning strategies, without incurring additional training costs.
VersaTune: An Efficient Data Composition Framework for Training Multi-Capability LLMs
Dec 02, 2024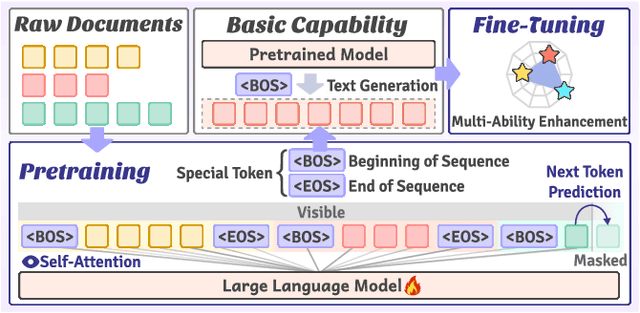



Large-scale pretrained models, particularly Large Language Models (LLMs), have exhibited remarkable capabilities in handling multiple tasks across domains due to their emergent properties. These capabilities are further augmented during the Supervised Fine-Tuning (SFT) phase. Despite their potential, existing work mainly focuses on domain-specific enhancements during fine-tuning, the challenge of which lies in catastrophic forgetting of knowledge across other domains. In this study, we introduce VersaTune, a novel data composition framework designed for enhancing LLMs' overall multi-ability performances during training. We categorize knowledge into distinct domains including law, medicine, finance, science, code, etc. We begin with detecting the distribution of domain-specific knowledge within the base model, followed by the training data composition that aligns with the model's existing knowledge distribution. During the training process, domain weights are dynamically adjusted based on their learnable potential and forgetting degree. Experimental results demonstrate that VersaTune achieves significant improvements in multi-domain performance, with an 35.21% enhancement in comprehensive multi-domain tasks. Additionally, in scenarios where specific domain optimization is required, VersaTune reduces the degradation of performance in other domains by 38.77%, without compromising the target domain's training efficacy.
VersaTune: Harnessing Vertical Domain Insights for Multi-Ability LLM Supervised Fine-Tuning
Nov 24, 2024Large Language Models (LLMs) exhibit remarkable capabilities in handling multiple tasks across domains due to their emergent properties. These capabilities are further augmented during the Supervised Fine-Tuning (SFT) phase. Despite their potential, existing work mainly focuses on domain-specific enhancements during fine-tuning, the challenge of which lies in catastrophic forgetting of knowledge across other domains. In this study, we introduce VersaTune, a novel data composition framework designed for enhancing LLMs' overall multi-ability performances during fine-tuning. We categorize knowledge into distinct domains including law, medicine, finance, science, code. We begin with detecting the distribution of domain-specific knowledge within the base model, followed by the composition of training data that aligns with the model's existing knowledge distribution. During the fine-tuning process, weights of different domains are dynamically adjusted based on their learnable potential and forgetting degree. Experimental results demonstrate that VersaTune achieves significant improvements in multi-domain performance, with a 35.21% enhancement in comprehensive multi-domain tasks. Additionally, in scenarios where specific domain optimization is required, VersaTune reduces the degradation of performance in other domains by 38.77%, without compromising the target domain's training efficacy.
VersaTune: Fine-Tuning Multi-Ability LLMs Efficiently
Nov 18, 2024Large Language Models (LLMs) exhibit remarkable capabilities in handling multiple tasks across domains due to their emergent properties. These capabilities are further augmented during the Supervised Fine-Tuning (SFT) phase. Despite their potential, existing work mainly focuses on domain-specific enhancements during fine-tuning, the challenge of which lies in catastrophic forgetting of knowledge across other domains. In this study, we introduce VersaTune, a novel data composition framework designed for enhancing LLMs' overall multi-ability performances during fine-tuning. We categorize knowledge into distinct domains including law, medicine, finance, science, code. We begin with detecting the distribution of domain-specific knowledge within the base model, followed by the composition of training data that aligns with the model's existing knowledge distribution. During the fine-tuning process, weights of different domains are dynamically adjusted based on their learnable potential and forgetting degree. Experimental results demonstrate that VersaTune achieves significant improvements in multi-domain performance, with a 35.21% enhancement in comprehensive multi-domain tasks. Additionally, in scenarios where specific domain optimization is required, VersaTune reduces the degradation of performance in other domains by 38.77%, without compromising the target domain's training efficacy.
Baichuan Alignment Technical Report
Oct 19, 2024



We introduce Baichuan Alignment, a detailed analysis of the alignment techniques employed in the Baichuan series of models. This represents the industry's first comprehensive account of alignment methodologies, offering valuable insights for advancing AI research. We investigate the critical components that enhance model performance during the alignment process, including optimization methods, data strategies, capability enhancements, and evaluation processes. The process spans three key stages: Prompt Augmentation System (PAS), Supervised Fine-Tuning (SFT), and Preference Alignment. The problems encountered, the solutions applied, and the improvements made are thoroughly recorded. Through comparisons across well-established benchmarks, we highlight the technological advancements enabled by Baichuan Alignment. Baichuan-Instruct is an internal model, while Qwen2-Nova-72B and Llama3-PBM-Nova-70B are instruct versions of the Qwen2-72B and Llama-3-70B base models, optimized through Baichuan Alignment. Baichuan-Instruct demonstrates significant improvements in core capabilities, with user experience gains ranging from 17% to 28%, and performs exceptionally well on specialized benchmarks. In open-source benchmark evaluations, both Qwen2-Nova-72B and Llama3-PBM-Nova-70B consistently outperform their respective official instruct versions across nearly all datasets. This report aims to clarify the key technologies behind the alignment process, fostering a deeper understanding within the community. Llama3-PBM-Nova-70B model is available at https://huggingface.co/PKU-Baichuan-MLSystemLab/Llama3-PBM-Nova-70B.
FB-Bench: A Fine-Grained Multi-Task Benchmark for Evaluating LLMs' Responsiveness to Human Feedback
Oct 12, 2024



Human feedback is crucial in the interactions between humans and Large Language Models (LLMs). However, existing research primarily focuses on benchmarking LLMs in single-turn dialogues. Even in benchmarks designed for multi-turn dialogues, the user inputs are often independent, neglecting the nuanced and complex nature of human feedback within real-world usage scenarios. To fill this research gap, we introduce FB-Bench, a fine-grained, multi-task benchmark designed to evaluate LLMs' responsiveness to human feedback in real-world usage scenarios. Drawing from the two main interaction scenarios, FB-Bench comprises 734 meticulously curated samples, encompassing eight task types, five deficiency types of response, and nine feedback types. We extensively evaluate a broad array of popular LLMs, revealing significant variations in their performance across different interaction scenarios. Further analysis indicates that task, human feedback, and deficiencies of previous responses can also significantly impact LLMs' responsiveness. Our findings underscore both the strengths and limitations of current models, providing valuable insights and directions for future research. Both the toolkits and the dataset of FB-Bench are available at https://github.com/PKU-Baichuan-MLSystemLab/FB-Bench.
Baichuan-Omni Technical Report
Oct 11, 2024



The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.