 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePilotRL: Training Language Model Agents via Global Planning-Guided Progressive Reinforcement Learning
Aug 01, 2025Large Language Models (LLMs) have shown remarkable advancements in tackling agent-oriented tasks. Despite their potential, existing work faces challenges when deploying LLMs in agent-based environments. The widely adopted agent paradigm ReAct centers on integrating single-step reasoning with immediate action execution, which limits its effectiveness in complex tasks requiring long-term strategic planning. Furthermore, the coordination between the planner and executor during problem-solving is also a critical factor to consider in agent design. Additionally, current approaches predominantly rely on supervised fine-tuning, which often leads models to memorize established task completion trajectories, thereby restricting their generalization ability when confronted with novel problem contexts. To address these challenges, we introduce an adaptive global plan-based agent paradigm AdaPlan, aiming to synergize high-level explicit guidance with execution to support effective long-horizon decision-making. Based on the proposed paradigm, we further put forward PilotRL, a global planning-guided training framework for LLM agents driven by progressive reinforcement learning. We first develop the model's ability to follow explicit guidance from global plans when addressing agent tasks. Subsequently, based on this foundation, we focus on optimizing the quality of generated plans. Finally, we conduct joint optimization of the model's planning and execution coordination. Experiments indicate that PilotRL could achieve state-of-the-art performances, with LLaMA3.1-8B-Instruct + PilotRL surpassing closed-sourced GPT-4o by 3.60%, while showing a more substantial gain of 55.78% comparing to GPT-4o-mini at a comparable parameter scale.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Med-R$^2$: Crafting Trustworthy LLM Physicians through Retrieval and Reasoning of Evidence-Based Medicine
Jan 21, 2025
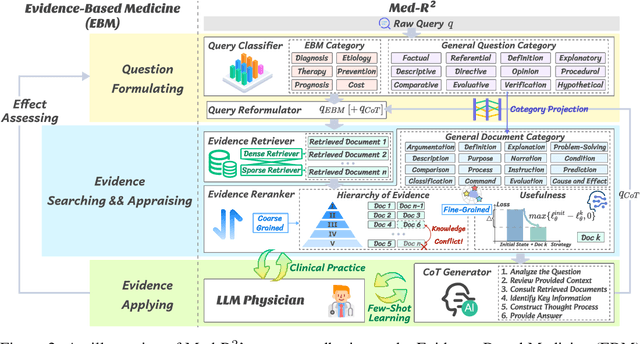
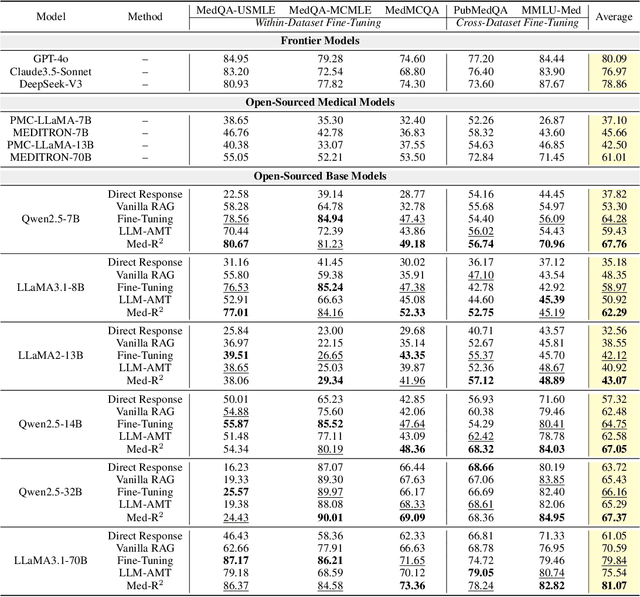
In recent years, Large Language Models (LLMs) have exhibited remarkable capabilities in clinical scenarios. However, despite their potential, existing works face challenges when applying LLMs to medical settings. Strategies relying on training with medical datasets are highly cost-intensive and may suffer from outdated training data. Leveraging external knowledge bases is a suitable alternative, yet it faces obstacles such as limited retrieval precision and poor effectiveness in answer extraction. These issues collectively prevent LLMs from demonstrating the expected level of proficiency in mastering medical expertise. To address these challenges, we introduce Med-R^2, a novel LLM physician framework that adheres to the Evidence-Based Medicine (EBM) process, efficiently integrating retrieval mechanisms as well as the selection and reasoning processes of evidence, thereby enhancing the problem-solving capabilities of LLMs in healthcare scenarios and fostering a trustworthy LLM physician. Our comprehensive experiments indicate that Med-R^2 achieves a 14.87\% improvement over vanilla RAG methods and even a 3.59\% enhancement compared to fine-tuning strategies, without incurring additional training costs.
VersaTune: An Efficient Data Composition Framework for Training Multi-Capability LLMs
Dec 02, 2024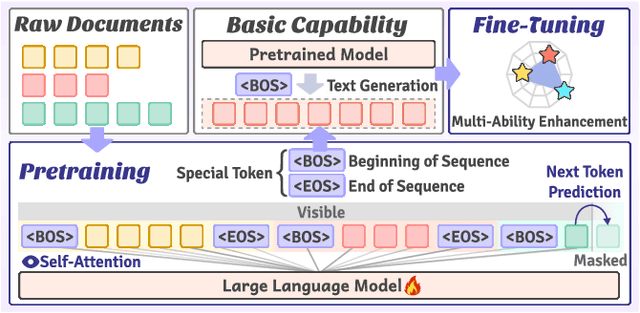



Large-scale pretrained models, particularly Large Language Models (LLMs), have exhibited remarkable capabilities in handling multiple tasks across domains due to their emergent properties. These capabilities are further augmented during the Supervised Fine-Tuning (SFT) phase. Despite their potential, existing work mainly focuses on domain-specific enhancements during fine-tuning, the challenge of which lies in catastrophic forgetting of knowledge across other domains. In this study, we introduce VersaTune, a novel data composition framework designed for enhancing LLMs' overall multi-ability performances during training. We categorize knowledge into distinct domains including law, medicine, finance, science, code, etc. We begin with detecting the distribution of domain-specific knowledge within the base model, followed by the training data composition that aligns with the model's existing knowledge distribution. During the training process, domain weights are dynamically adjusted based on their learnable potential and forgetting degree. Experimental results demonstrate that VersaTune achieves significant improvements in multi-domain performance, with an 35.21% enhancement in comprehensive multi-domain tasks. Additionally, in scenarios where specific domain optimization is required, VersaTune reduces the degradation of performance in other domains by 38.77%, without compromising the target domain's training efficacy.
VersaTune: Harnessing Vertical Domain Insights for Multi-Ability LLM Supervised Fine-Tuning
Nov 24, 2024Large Language Models (LLMs) exhibit remarkable capabilities in handling multiple tasks across domains due to their emergent properties. These capabilities are further augmented during the Supervised Fine-Tuning (SFT) phase. Despite their potential, existing work mainly focuses on domain-specific enhancements during fine-tuning, the challenge of which lies in catastrophic forgetting of knowledge across other domains. In this study, we introduce VersaTune, a novel data composition framework designed for enhancing LLMs' overall multi-ability performances during fine-tuning. We categorize knowledge into distinct domains including law, medicine, finance, science, code. We begin with detecting the distribution of domain-specific knowledge within the base model, followed by the composition of training data that aligns with the model's existing knowledge distribution. During the fine-tuning process, weights of different domains are dynamically adjusted based on their learnable potential and forgetting degree. Experimental results demonstrate that VersaTune achieves significant improvements in multi-domain performance, with a 35.21% enhancement in comprehensive multi-domain tasks. Additionally, in scenarios where specific domain optimization is required, VersaTune reduces the degradation of performance in other domains by 38.77%, without compromising the target domain's training efficacy.
VersaTune: Fine-Tuning Multi-Ability LLMs Efficiently
Nov 18, 2024Large Language Models (LLMs) exhibit remarkable capabilities in handling multiple tasks across domains due to their emergent properties. These capabilities are further augmented during the Supervised Fine-Tuning (SFT) phase. Despite their potential, existing work mainly focuses on domain-specific enhancements during fine-tuning, the challenge of which lies in catastrophic forgetting of knowledge across other domains. In this study, we introduce VersaTune, a novel data composition framework designed for enhancing LLMs' overall multi-ability performances during fine-tuning. We categorize knowledge into distinct domains including law, medicine, finance, science, code. We begin with detecting the distribution of domain-specific knowledge within the base model, followed by the composition of training data that aligns with the model's existing knowledge distribution. During the fine-tuning process, weights of different domains are dynamically adjusted based on their learnable potential and forgetting degree. Experimental results demonstrate that VersaTune achieves significant improvements in multi-domain performance, with a 35.21% enhancement in comprehensive multi-domain tasks. Additionally, in scenarios where specific domain optimization is required, VersaTune reduces the degradation of performance in other domains by 38.77%, without compromising the target domain's training efficacy.
Facilitating Multi-turn Function Calling for LLMs via Compositional Instruction Tuning
Oct 16, 2024



Large Language Models (LLMs) have exhibited significant potential in performing diverse tasks, including the ability to call functions or use external tools to enhance their performance. While current research on function calling by LLMs primarily focuses on single-turn interactions, this paper addresses the overlooked necessity for LLMs to engage in multi-turn function calling--critical for handling compositional, real-world queries that require planning with functions but not only use functions. To facilitate this, we introduce an approach, BUTTON, which generates synthetic compositional instruction tuning data via bottom-up instruction construction and top-down trajectory generation. In the bottom-up phase, we generate simple atomic tasks based on real-world scenarios and build compositional tasks using heuristic strategies based on atomic tasks. Corresponding functions are then developed for these compositional tasks. The top-down phase features a multi-agent environment where interactions among simulated humans, assistants, and tools are utilized to gather multi-turn function calling trajectories. This approach ensures task compositionality and allows for effective function and trajectory generation by examining atomic tasks within compositional tasks. We produce a dataset BUTTONInstruct comprising 8k data points and demonstrate its effectiveness through extensive experiments across various LLMs.
Baichuan-Omni Technical Report
Oct 11, 2024



The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
DataSculpt: Crafting Data Landscapes for LLM Post-Training through Multi-objective Partitioning
Sep 02, 2024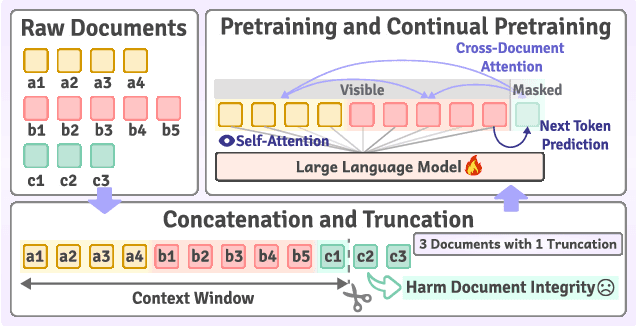

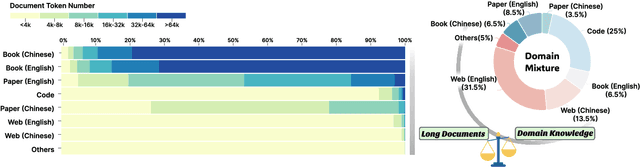
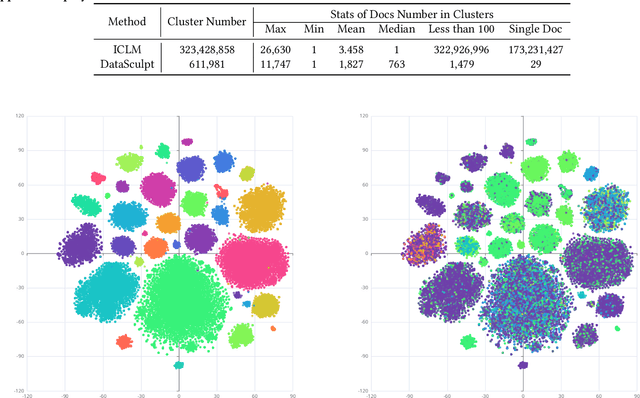
The effectiveness of long-context modeling is important for Large Language Models (LLMs) in various applications. Despite their potential, LLMs' efficacy in processing long context does not consistently meet expectations, posing significant challenges for efficient management of prolonged sequences in training. This difficulty is compounded by the scarcity of comprehensive and diverse training datasets suitable for long sequences, which stems from inherent length biases across different data sources, and the logistical complexities associated with massive data management for training in extended contexts. In this work, we introduce DataSculpt, a data construction framework designed to strategically augment the data architecture for extended-context training. Our thorough evaluations demonstrate DataSculpt's remarkable capacity to boost long-context training performance, achieving improvements including an 18.09% increase in retrieval augmentation, 21.23% in summarization, 21.27% in reading comprehension, and a 3.81% rise in code completion, all while preserving the models' overall proficiency with a 4.88% improvement.