 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataSculpt: Crafting Data Landscapes for LLM Post-Training through Multi-objective Partitioning
Paper and Code
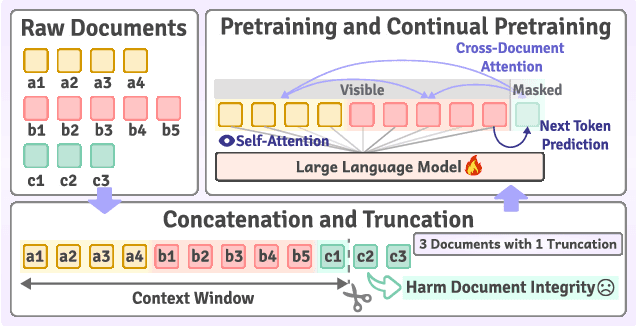

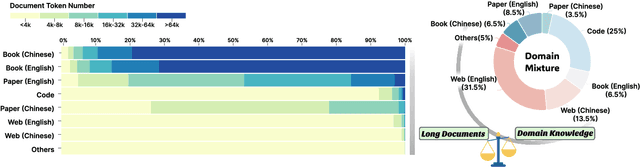
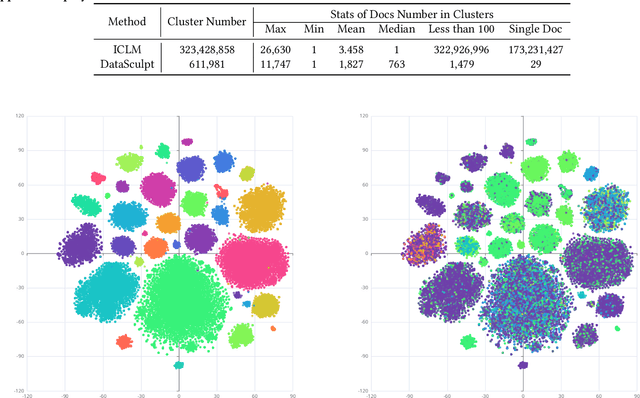
The effectiveness of long-context modeling is important for Large Language Models (LLMs) in various applications. Despite their potential, LLMs' efficacy in processing long context does not consistently meet expectations, posing significant challenges for efficient management of prolonged sequences in training. This difficulty is compounded by the scarcity of comprehensive and diverse training datasets suitable for long sequences, which stems from inherent length biases across different data sources, and the logistical complexities associated with massive data management for training in extended contexts. In this work, we introduce DataSculpt, a data construction framework designed to strategically augment the data architecture for extended-context training. Our thorough evaluations demonstrate DataSculpt's remarkable capacity to boost long-context training performance, achieving improvements including an 18.09% increase in retrieval augmentation, 21.23% in summarization, 21.27% in reading comprehension, and a 3.81% rise in code completion, all while preserving the models' overall proficiency with a 4.88% improvement.