 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraft-and-Prune: Improving the Reliability of Auto-formalization for Logical Reasoning
Mar 18, 2026Auto-formalization (AF) translates natural-language reasoning problems into solver-executable programs, enabling symbolic solvers to perform sound logical deduction. In practice, however, AF pipelines are currently brittle: programs may fail to execute, or execute but encode incorrect semantics. While prior work largely mitigates syntactic failures via repairs based on solver feedback, reducing semantics failures remains a major bottleneck. We propose Draft-and-Prune (D&P), an inference-time framework that improves AF-based logical reasoning via diversity and verification. D&P first drafts multiple natural-language plans and conditions program generation on them. It further prunes executable but contradictory or ambiguous formalizations, and aggregates predictions from surviving paths via majority voting. Across four representative benchmarks (AR-LSAT, ProofWriter, PrOntoQA, LogicalDeduction), D&P substantially strengthens AF-based reasoning without extra supervision. On AR-LSAT, in the AF-only setting, D&P achieves 78.43% accuracy with GPT-4 and 78.00% accuracy with GPT-4o, significantly outperforming the strongest AF baselines MAD-LOGIC and CLOVER. D&P then attains near-ceiling performance on the other benchmarks, including 100% on PrOntoQA and LogicalDeduction.
Agentified Assessment of Logical Reasoning Agents
Mar 03, 2026We present a framework for evaluating and benchmarking logical reasoning agents when assessment itself must be reproducible, auditable, and robust to execution failures. Building on agentified assessment, we use an assessor agent to issue tasks, enforce execution budgets, parse outputs, and record structured failure types, while the agent under test only needs to expose a standardized agent-to-agent interface. As a case study, we benchmark an auto-formalization agent for first-order logic (FOL) reasoning on a solver-verified and repaired split of FOLIO. The agent translates natural language premises and conclusions into executable Z3Py programs and employs satisfiability modulo theories (SMT) solving to determine logical entailment. On the cleaned FOLIO validation set, the auto-formalization agent achieves 86.70% accuracy under the assessor protocol, outperforming a chain-of-thought baseline (73.89%).
Nearly Optimal Bayesian Inference for Structural Missingness
Jan 27, 2026Structural missingness breaks 'just impute and train': values can be undefined by causal or logical constraints, and the mask may depend on observed variables, unobserved variables (MNAR), and other missingness indicators. It simultaneously brings (i) a catch-22 situation with causal loop, prediction needs the missing features, yet inferring them depends on the missingness mechanism, (ii) under MNAR, the unseen are different, the missing part can come from a shifted distribution, and (iii) plug-in imputation, a single fill-in can lock in uncertainty and yield overconfident, biased decisions. In the Bayesian view, prediction via the posterior predictive distribution integrates over the full model posterior uncertainty, rather than relying on a single point estimate. This framework decouples (i) learning an in-model missing-value posterior from (ii) label prediction by optimizing the predictive posterior distribution, enabling posterior integration. This decoupling yields an in-model almost-free-lunch: once the posterior is learned, prediction is plug-and-play while preserving uncertainty propagation. It achieves SOTA on 43 classification and 15 imputation benchmarks, with finite-sample near Bayes-optimality guarantees under our SCM prior.
Exploring the Heterogeneity of Tabular Data: A Diversity-aware Data Generator via LLMs
Dec 26, 2025Tabular data generation has become increasingly essential for enabling robust machine learning applications, which require large-scale, high-quality data. Existing solutions leverage generative models to learn original data distributions. However, real-world data are naturally heterogeneous with diverse distributions, making it challenging to obtain a universally good model for diverse data generation. To address this limitation, we introduce Diversity-Aware Tabular data gEnerator (DATE), a framework that (i) prepares high-quality and distributionally distinct examples for in-context learning by effectively partitioning the original heterogeneous data into multiple diverse subsets; (ii) harnesses Large Language Models (LLMs) to explore the diversity of the partitioned distribution with decision tree reasoning as feedback, generating high-quality labeled data for each subset. However, the massive generated data inherently involves a trade-off between diversity and quality. To integrate this issue, existing solutions greedily select the validation-best data. However, we prove that the selection in heterogeneous settings does not possess the greedy-choice property, and design a Multi-Arm Bandit-based sampling algorithm that balances the diversity and quality of generated data. Extensive experiments on tabular classification and regression benchmarks demonstrate that DATE consistently outperforms state-of-the-art GAN-based and LLM-based methods. On average, DATE achieves a 23.75% reduction in error rate with just 100 generated data. Empirically, we demonstrate that data generated by DATE can improve the accuracy of Direct Preference Optimization (DPO) and enhance the reasoning capability of LLMs on the target data. Code is available at https://github.com/windblow32/DATE.
Deep LG-Track: An Enhanced Localization-Confidence-Guided Multi-Object Tracker
Apr 02, 2025Multi-object tracking plays a crucial role in various applications, such as autonomous driving and security surveillance. This study introduces Deep LG-Track, a novel multi-object tracker that incorporates three key enhancements to improve the tracking accuracy and robustness. First, an adaptive Kalman filter is developed to dynamically update the covariance of measurement noise based on detection confidence and trajectory disappearance. Second, a novel cost matrix is formulated to adaptively fuse motion and appearance information, leveraging localization confidence and detection confidence as weighting factors. Third, a dynamic appearance feature updating strategy is introduced, adjusting the relative weighting of historical and current appearance features based on appearance clarity and localization accuracy. Comprehensive evaluations on the MOT17 and MOT20 datasets demonstrate that the proposed Deep LG-Track consistently outperforms state-of-the-art trackers across multiple performance metrics, highlighting its effectiveness in multi-object tracking tasks.
KDSelector: A Knowledge-Enhanced and Data-Efficient Model Selector Learning Framework for Time Series Anomaly Detection
Mar 16, 2025



Model selection has been raised as an essential problem in the area of time series anomaly detection (TSAD), because there is no single best TSAD model for the highly heterogeneous time series in real-world applications. However, despite the success of existing model selection solutions that train a classification model (especially neural network, NN) using historical data as a selector to predict the correct TSAD model for each series, the NN-based selector learning methods used by existing solutions do not make full use of the knowledge in the historical data and require iterating over all training samples, which limits the accuracy and training speed of the selector. To address these limitations, we propose KDSelector, a novel knowledge-enhanced and data-efficient framework for learning the NN-based TSAD model selector, of which three key components are specifically designed to integrate available knowledge into the selector and dynamically prune less important and redundant samples during the learning. We develop a TSAD model selection system with KDSelector as the internal, to demonstrate how users improve the accuracy and training speed of their selectors by using KDSelector as a plug-and-play module. Our demonstration video is hosted at https://youtu.be/2uqupDWvTF0.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025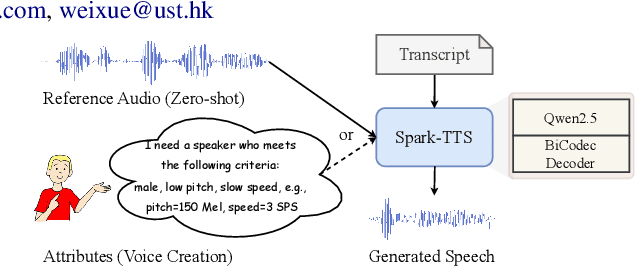
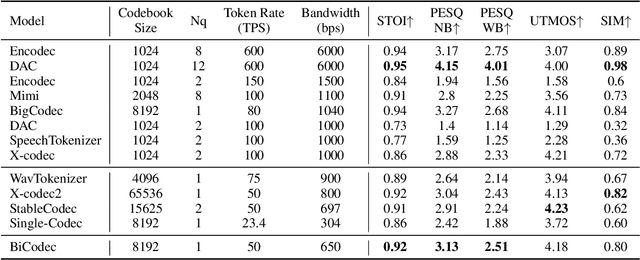
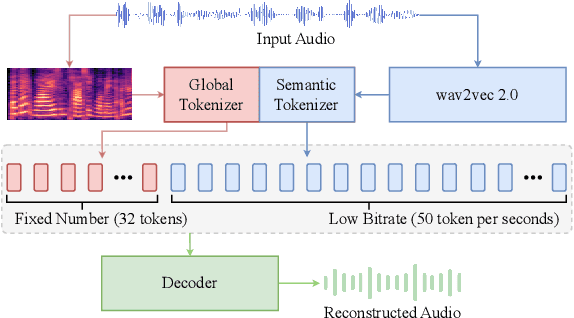
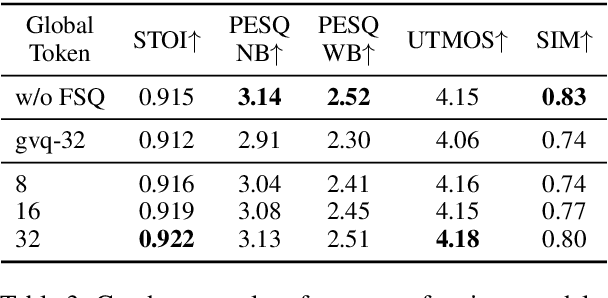
Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Baichuan-Audio: A Unified Framework for End-to-End Speech Interaction
Feb 24, 2025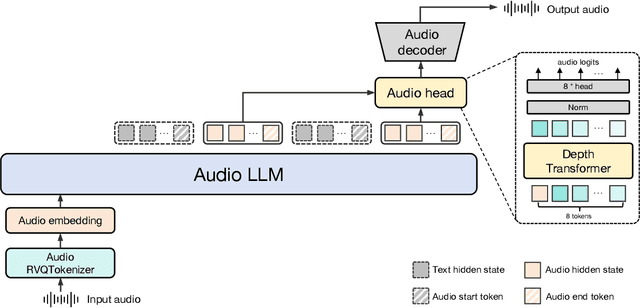
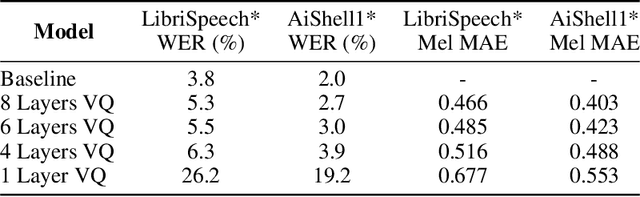
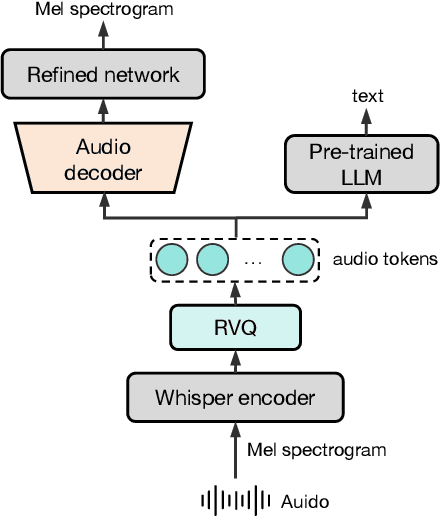
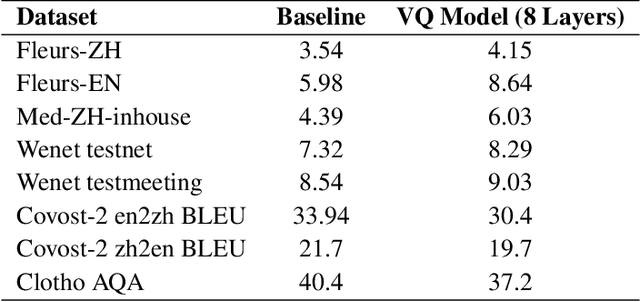
We introduce Baichuan-Audio, an end-to-end audio large language model that seamlessly integrates audio understanding and generation. It features a text-guided aligned speech generation mechanism, enabling real-time speech interaction with both comprehension and generation capabilities. Baichuan-Audio leverages a pre-trained ASR model, followed by multi-codebook discretization of speech at a frame rate of 12.5 Hz. This multi-codebook setup ensures that speech tokens retain both semantic and acoustic information. To further enhance modeling, an independent audio head is employed to process audio tokens, effectively capturing their unique characteristics. To mitigate the loss of intelligence during pre-training and preserve the original capabilities of the LLM, we propose a two-stage pre-training strategy that maintains language understanding while enhancing audio modeling. Following alignment, the model excels in real-time speech-based conversation and exhibits outstanding question-answering capabilities, demonstrating its versatility and efficiency. The proposed model demonstrates superior performance in real-time spoken dialogue and exhibits strong question-answering abilities. Our code, model and training data are available at https://github.com/baichuan-inc/Baichuan-Audio
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Med-R$^2$: Crafting Trustworthy LLM Physicians through Retrieval and Reasoning of Evidence-Based Medicine
Jan 21, 2025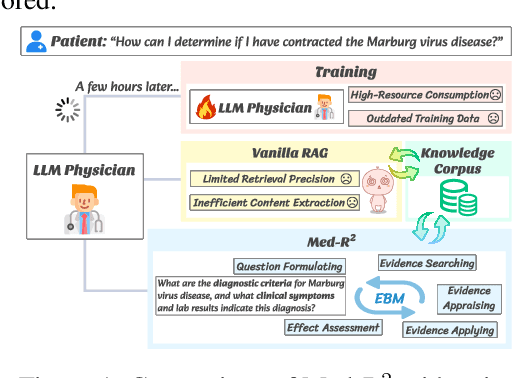
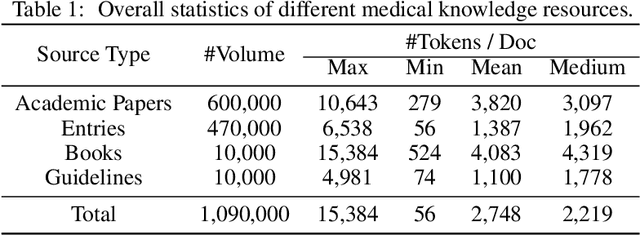
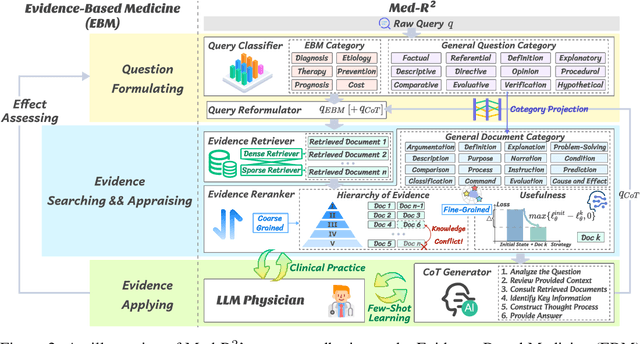
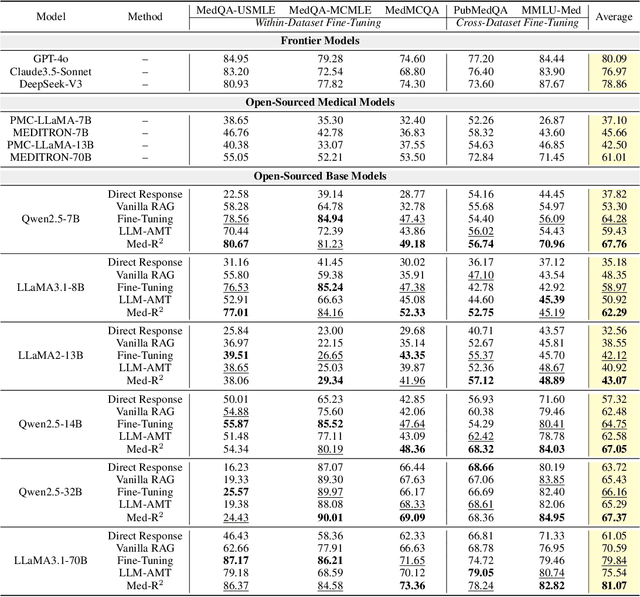
In recent years, Large Language Models (LLMs) have exhibited remarkable capabilities in clinical scenarios. However, despite their potential, existing works face challenges when applying LLMs to medical settings. Strategies relying on training with medical datasets are highly cost-intensive and may suffer from outdated training data. Leveraging external knowledge bases is a suitable alternative, yet it faces obstacles such as limited retrieval precision and poor effectiveness in answer extraction. These issues collectively prevent LLMs from demonstrating the expected level of proficiency in mastering medical expertise. To address these challenges, we introduce Med-R^2, a novel LLM physician framework that adheres to the Evidence-Based Medicine (EBM) process, efficiently integrating retrieval mechanisms as well as the selection and reasoning processes of evidence, thereby enhancing the problem-solving capabilities of LLMs in healthcare scenarios and fostering a trustworthy LLM physician. Our comprehensive experiments indicate that Med-R^2 achieves a 14.87\% improvement over vanilla RAG methods and even a 3.59\% enhancement compared to fine-tuning strategies, without incurring additional training costs.