 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Label Cleaning for Reliable Detection of Electron Dense Deposits in Transmission Electron Microscopy Images
Feb 05, 2026Automated detection of electron dense deposits (EDD) in glomerular disease is hindered by the scarcity of high-quality labeled data. While crowdsourcing reduces annotation cost, it introduces label noise. We propose an active label cleaning method to efficiently denoise crowdsourced datasets. Our approach uses active learning to select the most valuable noisy samples for expert re-annotation, building high-accuracy cleaning models. A Label Selection Module leverages discrepancies between crowdsourced labels and model predictions for both sample selection and instance-level noise grading. Experiments show our method achieves 67.18% AP\textsubscript{50} on a private dataset, an 18.83% improvement over training on noisy labels. This performance reaches 95.79% of that with full expert annotation while reducing annotation cost by 73.30%. The method provides a practical, cost-effective solution for developing reliable medical AI with limited expert resources.
Nearly Optimal Bayesian Inference for Structural Missingness
Jan 27, 2026Structural missingness breaks 'just impute and train': values can be undefined by causal or logical constraints, and the mask may depend on observed variables, unobserved variables (MNAR), and other missingness indicators. It simultaneously brings (i) a catch-22 situation with causal loop, prediction needs the missing features, yet inferring them depends on the missingness mechanism, (ii) under MNAR, the unseen are different, the missing part can come from a shifted distribution, and (iii) plug-in imputation, a single fill-in can lock in uncertainty and yield overconfident, biased decisions. In the Bayesian view, prediction via the posterior predictive distribution integrates over the full model posterior uncertainty, rather than relying on a single point estimate. This framework decouples (i) learning an in-model missing-value posterior from (ii) label prediction by optimizing the predictive posterior distribution, enabling posterior integration. This decoupling yields an in-model almost-free-lunch: once the posterior is learned, prediction is plug-and-play while preserving uncertainty propagation. It achieves SOTA on 43 classification and 15 imputation benchmarks, with finite-sample near Bayes-optimality guarantees under our SCM prior.
RubikSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System
Aug 25, 2025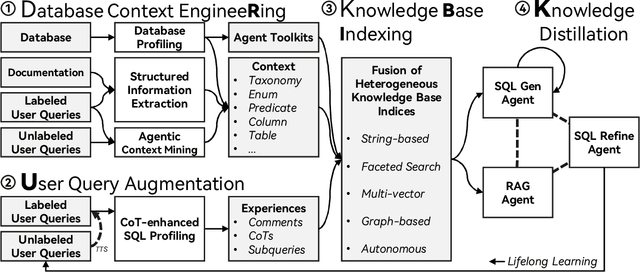
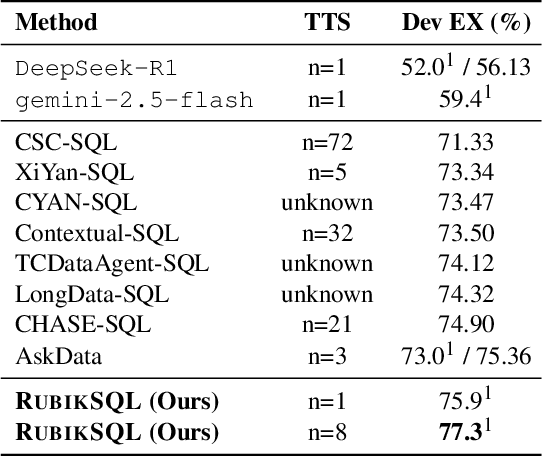
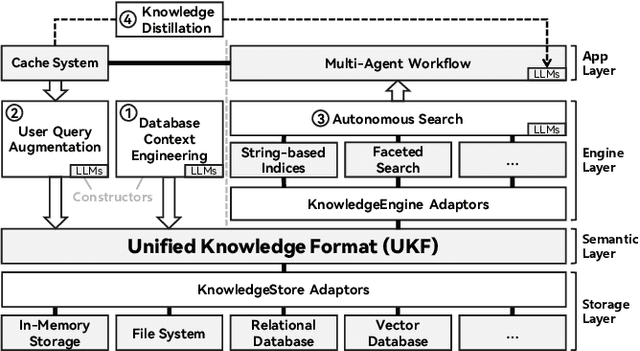
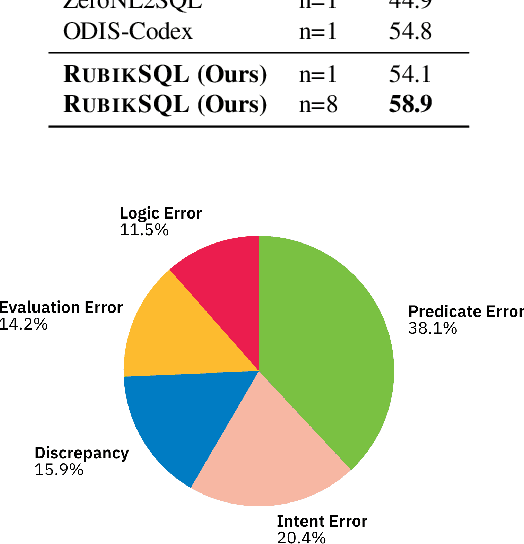
We present RubikSQL, a novel NL2SQL system designed to address key challenges in real-world enterprise-level NL2SQL, such as implicit intents and domain-specific terminology. RubikSQL frames NL2SQL as a lifelong learning task, demanding both Knowledge Base (KB) maintenance and SQL generation. RubikSQL systematically builds and refines its KB through techniques including database profiling, structured information extraction, agentic rule mining, and Chain-of-Thought (CoT)-enhanced SQL profiling. RubikSQL then employs a multi-agent workflow to leverage this curated KB, generating accurate SQLs. RubikSQL achieves SOTA performance on both the KaggleDBQA and BIRD Mini-Dev datasets. Finally, we release the RubikBench benchmark, a new benchmark specifically designed to capture vital traits of industrial NL2SQL scenarios, providing a valuable resource for future research.
Improving the Computational Efficiency and Explainability of GeoAggregator
Jul 23, 2025Accurate modeling and explaining geospatial tabular data (GTD) are critical for understanding geospatial phenomena and their underlying processes. Recent work has proposed a novel transformer-based deep learning model named GeoAggregator (GA) for this purpose, and has demonstrated that it outperforms other statistical and machine learning approaches. In this short paper, we further improve GA by 1) developing an optimized pipeline that accelerates the dataloading process and streamlines the forward pass of GA to achieve better computational efficiency; and 2) incorporating a model ensembling strategy and a post-hoc model explanation function based on the GeoShapley framework to enhance model explainability. We validate the functionality and efficiency of the proposed strategies by applying the improved GA model to synthetic datasets. Experimental results show that our implementation improves the prediction accuracy and inference speed of GA compared to the original implementation. Moreover, explanation experiments indicate that GA can effectively captures the inherent spatial effects in the designed synthetic dataset. The complete pipeline has been made publicly available for community use (https://github.com/ruid7181/GA-sklearn).
Explainable AI in Spatial Analysis
May 01, 2025This chapter discusses the opportunities of eXplainable Artificial Intelligence (XAI) within the realm of spatial analysis. A key objective in spatial analysis is to model spatial relationships and infer spatial processes to generate knowledge from spatial data, which has been largely based on spatial statistical methods. More recently, machine learning offers scalable and flexible approaches that complement traditional methods and has been increasingly applied in spatial data science. Despite its advantages, machine learning is often criticized for being a black box, which limits our understanding of model behavior and output. Recognizing this limitation, XAI has emerged as a pivotal field in AI that provides methods to explain the output of machine learning models to enhance transparency and understanding. These methods are crucial for model diagnosis, bias detection, and ensuring the reliability of results obtained from machine learning models. This chapter introduces key concepts and methods in XAI with a focus on Shapley value-based approaches, which is arguably the most popular XAI method, and their integration with spatial analysis. An empirical example of county-level voting behaviors in the 2020 Presidential election is presented to demonstrate the use of Shapley values and spatial analysis with a comparison to multi-scale geographically weighted regression. The chapter concludes with a discussion on the challenges and limitations of current XAI techniques and proposes new directions.
Can Moran Eigenvectors Improve Machine Learning of Spatial Data? Insights from Synthetic Data Validation
Apr 16, 2025Moran Eigenvector Spatial Filtering (ESF) approaches have shown promise in accounting for spatial effects in statistical models. Can this extend to machine learning? This paper examines the effectiveness of using Moran Eigenvectors as additional spatial features in machine learning models. We generate synthetic datasets with known processes involving spatially varying and nonlinear effects across two different geometries. Moran Eigenvectors calculated from different spatial weights matrices, with and without a priori eigenvector selection, are tested. We assess the performance of popular machine learning models, including Random Forests, LightGBM, XGBoost, and TabNet, and benchmark their accuracies in terms of cross-validated R2 values against models that use only coordinates as features. We also extract coefficients and functions from the models using GeoShapley and compare them with the true processes. Results show that machine learning models using only location coordinates achieve better accuracies than eigenvector-based approaches across various experiments and datasets. Furthermore, we discuss that while these findings are relevant for spatial processes that exhibit positive spatial autocorrelation, they do not necessarily apply when modeling network autocorrelation and cases with negative spatial autocorrelation, where Moran Eigenvectors would still be useful.
DistJoin: A Decoupled Join Cardinality Estimator based on Adaptive Neural Predicate Modulation
Mar 12, 2025Research on learned cardinality estimation has achieved significant progress in recent years. However, existing methods still face distinct challenges that hinder their practical deployment in production environments. We conceptualize these challenges as the "Trilemma of Cardinality Estimation", where learned cardinality estimation methods struggle to balance generality, accuracy, and updatability. To address these challenges, we introduce DistJoin, a join cardinality estimator based on efficient distribution prediction using multi-autoregressive models. Our contributions are threefold: (1) We propose a method for estimating both equi and non-equi join cardinality by leveraging the conditional probability distributions of individual tables in a decoupled manner. (2) To meet the requirements of efficient training and inference for DistJoin, we develop Adaptive Neural Predicate Modulation (ANPM), a high-throughput conditional probability distribution estimation model. (3) We formally analyze the variance of existing similar methods and demonstrate that such approaches suffer from variance accumulation issues. To mitigate this problem, DistJoin employs a selectivity-based approach rather than a count-based approach to infer join cardinality, effectively reducing variance. In summary, DistJoin not only represents the first data-driven method to effectively support both equi and non-equi joins but also demonstrates superior accuracy while enabling fast and flexible updates. We evaluate DistJoin on JOB-light and JOB-light-ranges, extending the evaluation to non-equi join conditions. The results demonstrate that our approach achieves the highest accuracy, robustness to data updates, generality, and comparable update and inference speed relative to existing methods.
GeoAggregator: An Efficient Transformer Model for Geo-Spatial Tabular Data
Feb 20, 2025



Modeling geospatial tabular data with deep learning has become a promising alternative to traditional statistical and machine learning approaches. However, existing deep learning models often face challenges related to scalability and flexibility as datasets grow. To this end, this paper introduces GeoAggregator, an efficient and lightweight algorithm based on transformer architecture designed specifically for geospatial tabular data modeling. GeoAggregators explicitly account for spatial autocorrelation and spatial heterogeneity through Gaussian-biased local attention and global positional awareness. Additionally, we introduce a new attention mechanism that uses the Cartesian product to manage the size of the model while maintaining strong expressive power. We benchmark GeoAggregator against spatial statistical models, XGBoost, and several state-of-the-art geospatial deep learning methods using both synthetic and empirical geospatial datasets. The results demonstrate that GeoAggregators achieve the best or second-best performance compared to their competitors on nearly all datasets. GeoAggregator's efficiency is underscored by its reduced model size, making it both scalable and lightweight. Moreover, ablation experiments offer insights into the effectiveness of the Gaussian bias and Cartesian attention mechanism, providing recommendations for further optimizing the GeoAggregator's performance.
MERLIN: Multi-stagE query performance prediction for dynamic paRallel oLap pIpeliNe
Dec 01, 2024High-performance OLAP database technology has emerged with the growing demand for massive data analysis. To achieve much higher performance, many DBMSs adopt sophisticated designs including SIMD operators, parallel execution, and dynamic pipeline modification. However, such advanced OLAP query execution mechanisms still lack targeted Query Performance Prediction (QPP) methods because most existing methods target conventional tree-shaped query plans and static serial executors. To address this problem, in this paper, we proposed MERLIN a multi-stage query performance prediction method for high-performance OLAP DBMSs. MERLIN first establishes resource cost models for each physical operator. Then, it constructs a DAG that consists of a data-flow tree backbone and resource competition relationships among concurrent operators. After using a GAT with an extra attention mechanism to calibrate the cost, the cost vector tree is extracted and summarized by a TCN, ultimately enabling effective query performance prediction. Experimental results demonstrate that MERLIN yields higher performance prediction precision than existing methods.
All-in-one Weather-degraded Image Restoration via Adaptive Degradation-aware Self-prompting Model
Nov 12, 2024



Existing approaches for all-in-one weather-degraded image restoration suffer from inefficiencies in leveraging degradation-aware priors, resulting in sub-optimal performance in adapting to different weather conditions. To this end, we develop an adaptive degradation-aware self-prompting model (ADSM) for all-in-one weather-degraded image restoration. Specifically, our model employs the contrastive language-image pre-training model (CLIP) to facilitate the training of our proposed latent prompt generators (LPGs), which represent three types of latent prompts to characterize the degradation type, degradation property and image caption. Moreover, we integrate the acquired degradation-aware prompts into the time embedding of diffusion model to improve degradation perception. Meanwhile, we employ the latent caption prompt to guide the reverse sampling process using the cross-attention mechanism, thereby guiding the accurate image reconstruction. Furthermore, to accelerate the reverse sampling procedure of diffusion model and address the limitations of frequency perception, we introduce a wavelet-oriented noise estimating network (WNE-Net). Extensive experiments conducted on eight publicly available datasets demonstrate the effectiveness of our proposed approach in both task-specific and all-in-one applications.