 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCha:End-to-End Video Character Replacement without Structural Guidance
Jan 14, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
End-to-End Video Character Replacement without Structural Guidance
Jan 13, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
Generative Photographic Control for Scene-Consistent Video Cinematic Editing
Nov 17, 2025Cinematic storytelling is profoundly shaped by the artful manipulation of photographic elements such as depth of field and exposure. These effects are crucial in conveying mood and creating aesthetic appeal. However, controlling these effects in generative video models remains highly challenging, as most existing methods are restricted to camera motion control. In this paper, we propose CineCtrl, the first video cinematic editing framework that provides fine control over professional camera parameters (e.g., bokeh, shutter speed). We introduce a decoupled cross-attention mechanism to disentangle camera motion from photographic inputs, allowing fine-grained, independent control without compromising scene consistency. To overcome the shortage of training data, we develop a comprehensive data generation strategy that leverages simulated photographic effects with a dedicated real-world collection pipeline, enabling the construction of a large-scale dataset for robust model training. Extensive experiments demonstrate that our model generates high-fidelity videos with precisely controlled, user-specified photographic camera effects.
Semi-Supervised High Dynamic Range Image Reconstructing via Bi-Level Uncertain Area Masking
Nov 17, 2025Reconstructing high dynamic range (HDR) images from low dynamic range (LDR) bursts plays an essential role in the computational photography. Impressive progress has been achieved by learning-based algorithms which require LDR-HDR image pairs. However, these pairs are hard to obtain, which motivates researchers to delve into the problem of annotation-efficient HDR image reconstructing: how to achieve comparable performance with limited HDR ground truths (GTs). This work attempts to address this problem from the view of semi-supervised learning where a teacher model generates pseudo HDR GTs for the LDR samples without GTs and a student model learns from pseudo GTs. Nevertheless, the confirmation bias, i.e., the student may learn from the artifacts in pseudo HDR GTs, presents an impediment. To remove this impediment, an uncertainty-based masking process is proposed to discard unreliable parts of pseudo GTs at both pixel and patch levels, then the trusted areas can be learned from by the student. With this novel masking process, our semi-supervised HDR reconstructing method not only outperforms previous annotation-efficient algorithms, but also achieves comparable performance with up-to-date fully-supervised methods by using only 6.7% HDR GTs.
Can Moran Eigenvectors Improve Machine Learning of Spatial Data? Insights from Synthetic Data Validation
Apr 16, 2025Moran Eigenvector Spatial Filtering (ESF) approaches have shown promise in accounting for spatial effects in statistical models. Can this extend to machine learning? This paper examines the effectiveness of using Moran Eigenvectors as additional spatial features in machine learning models. We generate synthetic datasets with known processes involving spatially varying and nonlinear effects across two different geometries. Moran Eigenvectors calculated from different spatial weights matrices, with and without a priori eigenvector selection, are tested. We assess the performance of popular machine learning models, including Random Forests, LightGBM, XGBoost, and TabNet, and benchmark their accuracies in terms of cross-validated R2 values against models that use only coordinates as features. We also extract coefficients and functions from the models using GeoShapley and compare them with the true processes. Results show that machine learning models using only location coordinates achieve better accuracies than eigenvector-based approaches across various experiments and datasets. Furthermore, we discuss that while these findings are relevant for spatial processes that exhibit positive spatial autocorrelation, they do not necessarily apply when modeling network autocorrelation and cases with negative spatial autocorrelation, where Moran Eigenvectors would still be useful.
Exploring Contextual Attribute Density in Referring Expression Counting
Mar 16, 2025
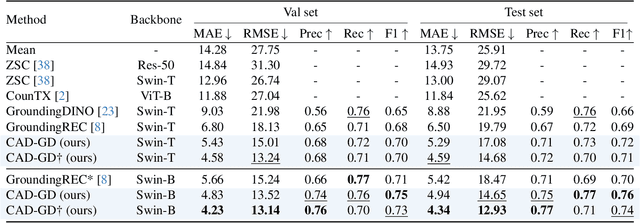
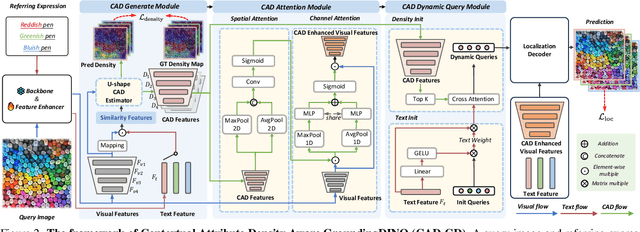
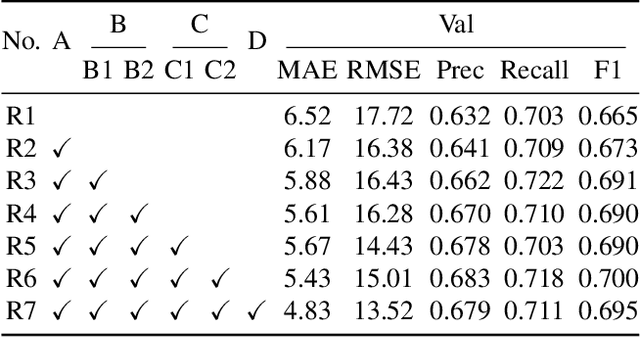
Referring expression counting (REC) algorithms are for more flexible and interactive counting ability across varied fine-grained text expressions. However, the requirement for fine-grained attribute understanding poses challenges for prior arts, as they struggle to accurately align attribute information with correct visual patterns. Given the proven importance of ''visual density'', it is presumed that the limitations of current REC approaches stem from an under-exploration of ''contextual attribute density'' (CAD). In the scope of REC, we define CAD as the measure of the information intensity of one certain fine-grained attribute in visual regions. To model the CAD, we propose a U-shape CAD estimator in which referring expression and multi-scale visual features from GroundingDINO can interact with each other. With additional density supervision, we can effectively encode CAD, which is subsequently decoded via a novel attention procedure with CAD-refined queries. Integrating all these contributions, our framework significantly outperforms state-of-the-art REC methods, achieves $30\%$ error reduction in counting metrics and a $10\%$ improvement in localization accuracy. The surprising results shed light on the significance of contextual attribute density for REC. Code will be at github.com/Xu3XiWang/CAD-GD.
Exposure Completing for Temporally Consistent Neural High Dynamic Range Video Rendering
Jul 18, 2024High dynamic range (HDR) video rendering from low dynamic range (LDR) videos where frames are of alternate exposure encounters significant challenges, due to the exposure change and absence at each time stamp. The exposure change and absence make existing methods generate flickering HDR results. In this paper, we propose a novel paradigm to render HDR frames via completing the absent exposure information, hence the exposure information is complete and consistent. Our approach involves interpolating neighbor LDR frames in the time dimension to reconstruct LDR frames for the absent exposures. Combining the interpolated and given LDR frames, the complete set of exposure information is available at each time stamp. This benefits the fusing process for HDR results, reducing noise and ghosting artifacts therefore improving temporal consistency. Extensive experimental evaluations on standard benchmarks demonstrate that our method achieves state-of-the-art performance, highlighting the importance of absent exposure completing in HDR video rendering. The code is available at https://github.com/cuijiahao666/NECHDR.
Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields
Apr 26, 2024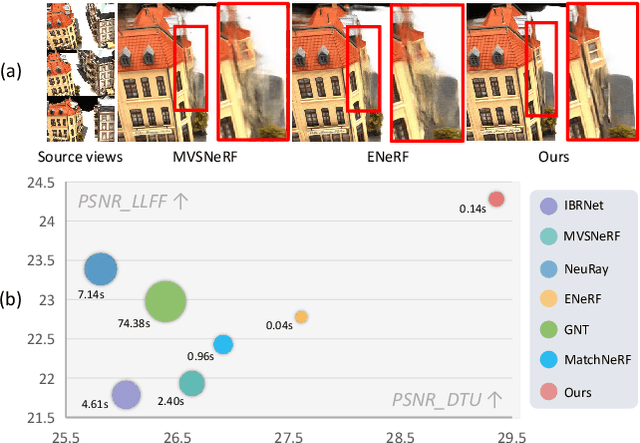
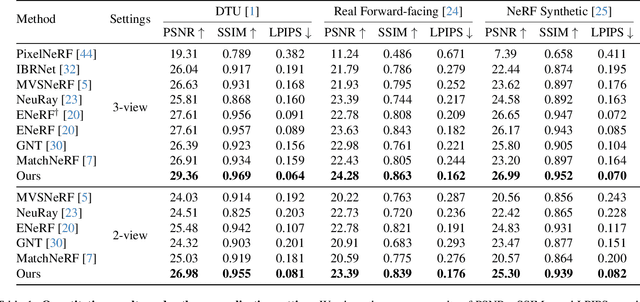
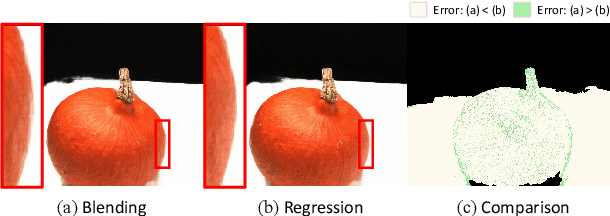
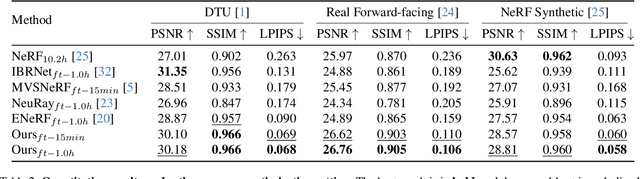
Generalizable NeRF aims to synthesize novel views for unseen scenes. Common practices involve constructing variance-based cost volumes for geometry reconstruction and encoding 3D descriptors for decoding novel views. However, existing methods show limited generalization ability in challenging conditions due to inaccurate geometry, sub-optimal descriptors, and decoding strategies. We address these issues point by point. First, we find the variance-based cost volume exhibits failure patterns as the features of pixels corresponding to the same point can be inconsistent across different views due to occlusions or reflections. We introduce an Adaptive Cost Aggregation (ACA) approach to amplify the contribution of consistent pixel pairs and suppress inconsistent ones. Unlike previous methods that solely fuse 2D features into descriptors, our approach introduces a Spatial-View Aggregator (SVA) to incorporate 3D context into descriptors through spatial and inter-view interaction. When decoding the descriptors, we observe the two existing decoding strategies excel in different areas, which are complementary. A Consistency-Aware Fusion (CAF) strategy is proposed to leverage the advantages of both. We incorporate the above ACA, SVA, and CAF into a coarse-to-fine framework, termed Geometry-aware Reconstruction and Fusion-refined Rendering (GeFu). GeFu attains state-of-the-art performance across multiple datasets. Code is available at https://github.com/TQTQliu/GeFu .
3D Multi-frame Fusion for Video Stabilization
Apr 19, 2024
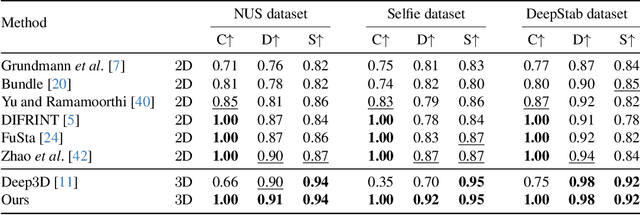
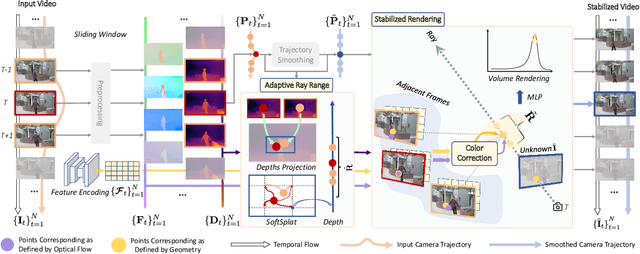

In this paper, we present RStab, a novel framework for video stabilization that integrates 3D multi-frame fusion through volume rendering. Departing from conventional methods, we introduce a 3D multi-frame perspective to generate stabilized images, addressing the challenge of full-frame generation while preserving structure. The core of our approach lies in Stabilized Rendering (SR), a volume rendering module, which extends beyond the image fusion by incorporating feature fusion. The core of our RStab framework lies in Stabilized Rendering (SR), a volume rendering module, fusing multi-frame information in 3D space. Specifically, SR involves warping features and colors from multiple frames by projection, fusing them into descriptors to render the stabilized image. However, the precision of warped information depends on the projection accuracy, a factor significantly influenced by dynamic regions. In response, we introduce the Adaptive Ray Range (ARR) module to integrate depth priors, adaptively defining the sampling range for the projection process. Additionally, we propose Color Correction (CC) assisting geometric constraints with optical flow for accurate color aggregation. Thanks to the three modules, our RStab demonstrates superior performance compared with previous stabilizers in the field of view (FOV), image quality, and video stability across various datasets.
Fast Full-frame Video Stabilization with Iterative Optimization
Jul 31, 2023



Video stabilization refers to the problem of transforming a shaky video into a visually pleasing one. The question of how to strike a good trade-off between visual quality and computational speed has remained one of the open challenges in video stabilization. Inspired by the analogy between wobbly frames and jigsaw puzzles, we propose an iterative optimization-based learning approach using synthetic datasets for video stabilization, which consists of two interacting submodules: motion trajectory smoothing and full-frame outpainting. First, we develop a two-level (coarse-to-fine) stabilizing algorithm based on the probabilistic flow field. The confidence map associated with the estimated optical flow is exploited to guide the search for shared regions through backpropagation. Second, we take a divide-and-conquer approach and propose a novel multiframe fusion strategy to render full-frame stabilized views. An important new insight brought about by our iterative optimization approach is that the target video can be interpreted as the fixed point of nonlinear mapping for video stabilization. We formulate video stabilization as a problem of minimizing the amount of jerkiness in motion trajectories, which guarantees convergence with the help of fixed-point theory. Extensive experimental results are reported to demonstrate the superiority of the proposed approach in terms of computational speed and visual quality. The code will be available on GitHub.