 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Contextual Attribute Density in Referring Expression Counting
Paper and Code

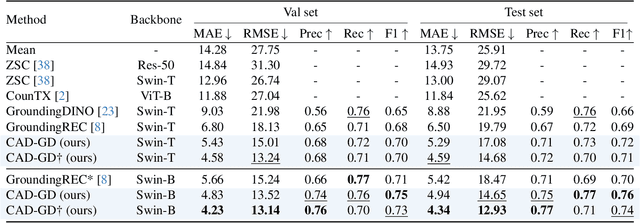
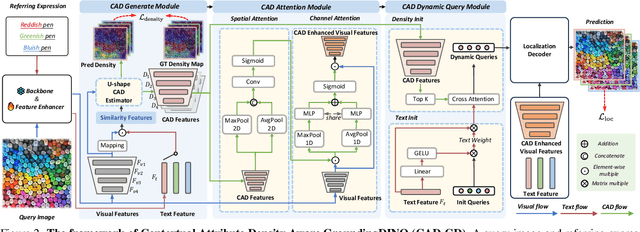
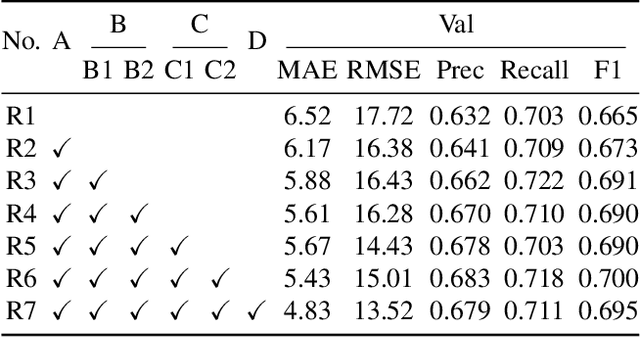
Referring expression counting (REC) algorithms are for more flexible and interactive counting ability across varied fine-grained text expressions. However, the requirement for fine-grained attribute understanding poses challenges for prior arts, as they struggle to accurately align attribute information with correct visual patterns. Given the proven importance of ''visual density'', it is presumed that the limitations of current REC approaches stem from an under-exploration of ''contextual attribute density'' (CAD). In the scope of REC, we define CAD as the measure of the information intensity of one certain fine-grained attribute in visual regions. To model the CAD, we propose a U-shape CAD estimator in which referring expression and multi-scale visual features from GroundingDINO can interact with each other. With additional density supervision, we can effectively encode CAD, which is subsequently decoded via a novel attention procedure with CAD-refined queries. Integrating all these contributions, our framework significantly outperforms state-of-the-art REC methods, achieves $30\%$ error reduction in counting metrics and a $10\%$ improvement in localization accuracy. The surprising results shed light on the significance of contextual attribute density for REC. Code will be at github.com/Xu3XiWang/CAD-GD.