 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Multi-frame Fusion for Video Stabilization
Apr 19, 2024
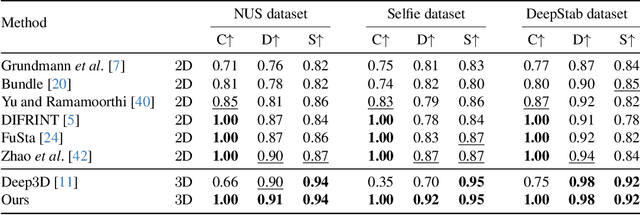
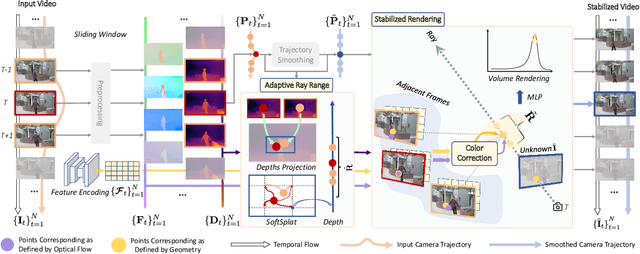

In this paper, we present RStab, a novel framework for video stabilization that integrates 3D multi-frame fusion through volume rendering. Departing from conventional methods, we introduce a 3D multi-frame perspective to generate stabilized images, addressing the challenge of full-frame generation while preserving structure. The core of our approach lies in Stabilized Rendering (SR), a volume rendering module, which extends beyond the image fusion by incorporating feature fusion. The core of our RStab framework lies in Stabilized Rendering (SR), a volume rendering module, fusing multi-frame information in 3D space. Specifically, SR involves warping features and colors from multiple frames by projection, fusing them into descriptors to render the stabilized image. However, the precision of warped information depends on the projection accuracy, a factor significantly influenced by dynamic regions. In response, we introduce the Adaptive Ray Range (ARR) module to integrate depth priors, adaptively defining the sampling range for the projection process. Additionally, we propose Color Correction (CC) assisting geometric constraints with optical flow for accurate color aggregation. Thanks to the three modules, our RStab demonstrates superior performance compared with previous stabilizers in the field of view (FOV), image quality, and video stability across various datasets.
When Epipolar Constraint Meets Non-local Operators in Multi-View Stereo
Sep 29, 2023



Learning-based multi-view stereo (MVS) method heavily relies on feature matching, which requires distinctive and descriptive representations. An effective solution is to apply non-local feature aggregation, e.g., Transformer. Albeit useful, these techniques introduce heavy computation overheads for MVS. Each pixel densely attends to the whole image. In contrast, we propose to constrain non-local feature augmentation within a pair of lines: each point only attends the corresponding pair of epipolar lines. Our idea takes inspiration from the classic epipolar geometry, which shows that one point with different depth hypotheses will be projected to the epipolar line on the other view. This constraint reduces the 2D search space into the epipolar line in stereo matching. Similarly, this suggests that the matching of MVS is to distinguish a series of points lying on the same line. Inspired by this point-to-line search, we devise a line-to-point non-local augmentation strategy. We first devise an optimized searching algorithm to split the 2D feature maps into epipolar line pairs. Then, an Epipolar Transformer (ET) performs non-local feature augmentation among epipolar line pairs. We incorporate the ET into a learning-based MVS baseline, named ET-MVSNet. ET-MVSNet achieves state-of-the-art reconstruction performance on both the DTU and Tanks-and-Temples benchmark with high efficiency. Code is available at https://github.com/TQTQliu/ET-MVSNet.
Fast Full-frame Video Stabilization with Iterative Optimization
Jul 31, 2023



Video stabilization refers to the problem of transforming a shaky video into a visually pleasing one. The question of how to strike a good trade-off between visual quality and computational speed has remained one of the open challenges in video stabilization. Inspired by the analogy between wobbly frames and jigsaw puzzles, we propose an iterative optimization-based learning approach using synthetic datasets for video stabilization, which consists of two interacting submodules: motion trajectory smoothing and full-frame outpainting. First, we develop a two-level (coarse-to-fine) stabilizing algorithm based on the probabilistic flow field. The confidence map associated with the estimated optical flow is exploited to guide the search for shared regions through backpropagation. Second, we take a divide-and-conquer approach and propose a novel multiframe fusion strategy to render full-frame stabilized views. An important new insight brought about by our iterative optimization approach is that the target video can be interpreted as the fixed point of nonlinear mapping for video stabilization. We formulate video stabilization as a problem of minimizing the amount of jerkiness in motion trajectories, which guarantees convergence with the help of fixed-point theory. Extensive experimental results are reported to demonstrate the superiority of the proposed approach in terms of computational speed and visual quality. The code will be available on GitHub.
Constraining Depth Map Geometry for Multi-View Stereo: A Dual-Depth Approach with Saddle-shaped Depth Cells
Jul 18, 2023Learning-based multi-view stereo (MVS) methods deal with predicting accurate depth maps to achieve an accurate and complete 3D representation. Despite the excellent performance, existing methods ignore the fact that a suitable depth geometry is also critical in MVS. In this paper, we demonstrate that different depth geometries have significant performance gaps, even using the same depth prediction error. Therefore, we introduce an ideal depth geometry composed of Saddle-Shaped Cells, whose predicted depth map oscillates upward and downward around the ground-truth surface, rather than maintaining a continuous and smooth depth plane. To achieve it, we develop a coarse-to-fine framework called Dual-MVSNet (DMVSNet), which can produce an oscillating depth plane. Technically, we predict two depth values for each pixel (Dual-Depth), and propose a novel loss function and a checkerboard-shaped selecting strategy to constrain the predicted depth geometry. Compared to existing methods,DMVSNet achieves a high rank on the DTU benchmark and obtains the top performance on challenging scenes of Tanks and Temples, demonstrating its strong performance and generalization ability. Our method also points to a new research direction for considering depth geometry in MVS.
A2B: Anchor to Barycentric Coordinate for Robust Correspondence
Jun 07, 2023There is a long-standing problem of repeated patterns in correspondence problems, where mismatches frequently occur because of inherent ambiguity. The unique position information associated with repeated patterns makes coordinate representations a useful supplement to appearance representations for improving feature correspondences. However, the issue of appropriate coordinate representation has remained unresolved. In this study, we demonstrate that geometric-invariant coordinate representations, such as barycentric coordinates, can significantly reduce mismatches between features. The first step is to establish a theoretical foundation for geometrically invariant coordinates. We present a seed matching and filtering network (SMFNet) that combines feature matching and consistency filtering with a coarse-to-fine matching strategy in order to acquire reliable sparse correspondences. We then introduce DEGREE, a novel anchor-to-barycentric (A2B) coordinate encoding approach, which generates multiple affine-invariant correspondence coordinates from paired images. DEGREE can be used as a plug-in with standard descriptors, feature matchers, and consistency filters to improve the matching quality. Extensive experiments in synthesized indoor and outdoor datasets demonstrate that DEGREE alleviates the problem of repeated patterns and helps achieve state-of-the-art performance. Furthermore, DEGREE also reports competitive performance in the third Image Matching Challenge at CVPR 2021. This approach offers a new perspective to alleviate the problem of repeated patterns and emphasizes the importance of choosing coordinate representations for feature correspondences.
Learning Probabilistic Coordinate Fields for Robust Correspondences
Jun 07, 2023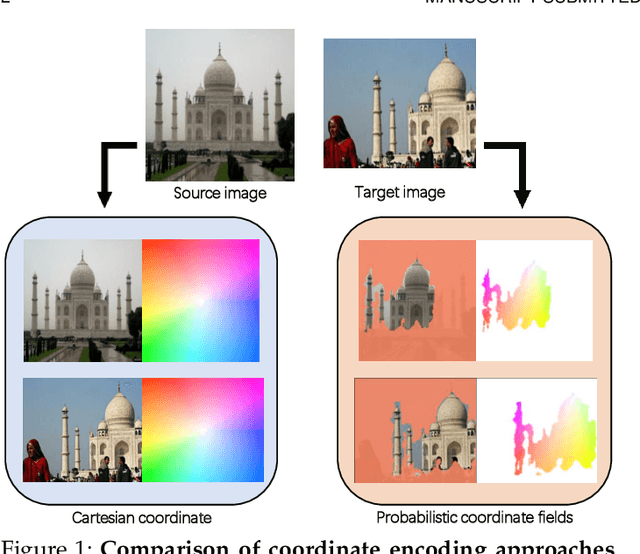


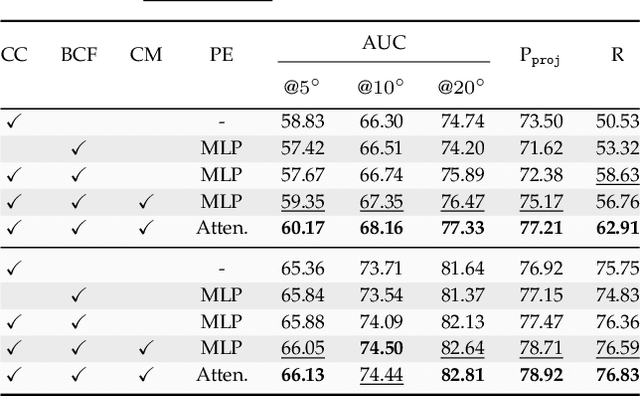
We introduce Probabilistic Coordinate Fields (PCFs), a novel geometric-invariant coordinate representation for image correspondence problems. In contrast to standard Cartesian coordinates, PCFs encode coordinates in correspondence-specific barycentric coordinate systems (BCS) with affine invariance. To know \textit{when and where to trust} the encoded coordinates, we implement PCFs in a probabilistic network termed PCF-Net, which parameterizes the distribution of coordinate fields as Gaussian mixture models. By jointly optimizing coordinate fields and their confidence conditioned on dense flows, PCF-Net can work with various feature descriptors when quantifying the reliability of PCFs by confidence maps. An interesting observation of this work is that the learned confidence map converges to geometrically coherent and semantically consistent regions, which facilitates robust coordinate representation. By delivering the confident coordinates to keypoint/feature descriptors, we show that PCF-Net can be used as a plug-in to existing correspondence-dependent approaches. Extensive experiments on both indoor and outdoor datasets suggest that accurate geometric invariant coordinates help to achieve the state of the art in several correspondence problems, such as sparse feature matching, dense image registration, camera pose estimation, and consistency filtering. Further, the interpretable confidence map predicted by PCF-Net can also be leveraged to other novel applications from texture transfer to multi-homography classification.
Point-and-Shoot All-in-Focus Photo Synthesis from Smartphone Camera Pair
Apr 11, 2023



All-in-Focus (AIF) photography is expected to be a commercial selling point for modern smartphones. Standard AIF synthesis requires manual, time-consuming operations such as focal stack compositing, which is unfriendly to ordinary people. To achieve point-and-shoot AIF photography with a smartphone, we expect that an AIF photo can be generated from one shot of the scene, instead of from multiple photos captured by the same camera. Benefiting from the multi-camera module in modern smartphones, we introduce a new task of AIF synthesis from main (wide) and ultra-wide cameras. The goal is to recover sharp details from defocused regions in the main-camera photo with the help of the ultra-wide-camera one. The camera setting poses new challenges such as parallax-induced occlusions and inconsistent color between cameras. To overcome the challenges, we introduce a predict-and-refine network to mitigate occlusions and propose dynamic frequency-domain alignment for color correction. To enable effective training and evaluation, we also build an AIF dataset with 2686 unique scenes. Each scene includes two photos captured by the main camera, one photo captured by the ultrawide camera, and a synthesized AIF photo. Results show that our solution, termed EasyAIF, can produce high-quality AIF photos and outperforms strong baselines quantitatively and qualitatively. For the first time, we demonstrate point-and-shoot AIF photo synthesis successfully from main and ultra-wide cameras.
Learning Second-Order Attentive Context for Efficient Correspondence Pruning
Mar 28, 2023Correspondence pruning aims to search consistent correspondences (inliers) from a set of putative correspondences. It is challenging because of the disorganized spatial distribution of numerous outliers, especially when putative correspondences are largely dominated by outliers. It's more challenging to ensure effectiveness while maintaining efficiency. In this paper, we propose an effective and efficient method for correspondence pruning. Inspired by the success of attentive context in correspondence problems, we first extend the attentive context to the first-order attentive context and then introduce the idea of attention in attention (ANA) to model second-order attentive context for correspondence pruning. Compared with first-order attention that focuses on feature-consistent context, second-order attention dedicates to attention weights itself and provides an additional source to encode consistent context from the attention map. For efficiency, we derive two approximate formulations for the naive implementation of second-order attention to optimize the cubic complexity to linear complexity, such that second-order attention can be used with negligible computational overheads. We further implement our formulations in a second-order context layer and then incorporate the layer in an ANA block. Extensive experiments demonstrate that our method is effective and efficient in pruning outliers, especially in high-outlier-ratio cases. Compared with the state-of-the-art correspondence pruning approach LMCNet, our method runs 14 times faster while maintaining a competitive accuracy.