 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Camera All-in-Focus Neural Radiance Fields
Apr 23, 2025We present the first framework capable of synthesizing the all-in-focus neural radiance field (NeRF) from inputs without manual refocusing. Without refocusing, the camera will automatically focus on the fixed object for all views, and current NeRF methods typically using one camera fail due to the consistent defocus blur and a lack of sharp reference. To restore the all-in-focus NeRF, we introduce the dual-camera from smartphones, where the ultra-wide camera has a wider depth-of-field (DoF) and the main camera possesses a higher resolution. The dual camera pair saves the high-fidelity details from the main camera and uses the ultra-wide camera's deep DoF as reference for all-in-focus restoration. To this end, we first implement spatial warping and color matching to align the dual camera, followed by a defocus-aware fusion module with learnable defocus parameters to predict a defocus map and fuse the aligned camera pair. We also build a multi-view dataset that includes image pairs of the main and ultra-wide cameras in a smartphone. Extensive experiments on this dataset verify that our solution, termed DC-NeRF, can produce high-quality all-in-focus novel views and compares favorably against strong baselines quantitatively and qualitatively. We further show DoF applications of DC-NeRF with adjustable blur intensity and focal plane, including refocusing and split diopter.
iControl3D: An Interactive System for Controllable 3D Scene Generation
Aug 03, 2024

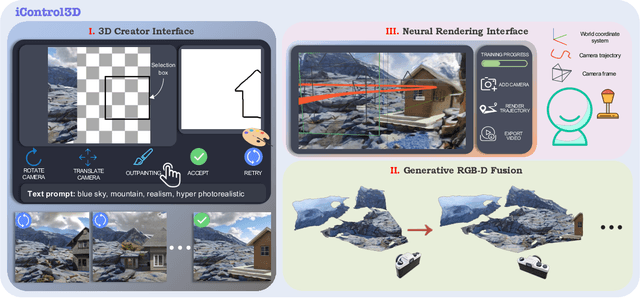
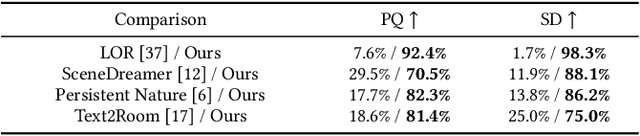
3D content creation has long been a complex and time-consuming process, often requiring specialized skills and resources. While recent advancements have allowed for text-guided 3D object and scene generation, they still fall short of providing sufficient control over the generation process, leading to a gap between the user's creative vision and the generated results. In this paper, we present iControl3D, a novel interactive system that empowers users to generate and render customizable 3D scenes with precise control. To this end, a 3D creator interface has been developed to provide users with fine-grained control over the creation process. Technically, we leverage 3D meshes as an intermediary proxy to iteratively merge individual 2D diffusion-generated images into a cohesive and unified 3D scene representation. To ensure seamless integration of 3D meshes, we propose to perform boundary-aware depth alignment before fusing the newly generated mesh with the existing one in 3D space. Additionally, to effectively manage depth discrepancies between remote content and foreground, we propose to model remote content separately with an environment map instead of 3D meshes. Finally, our neural rendering interface enables users to build a radiance field of their scene online and navigate the entire scene. Extensive experiments have been conducted to demonstrate the effectiveness of our system. The code will be made available at https://github.com/xingyi-li/iControl3D.
Dynamic Neural Radiance Field From Defocused Monocular Video
Jul 08, 2024Dynamic Neural Radiance Field (NeRF) from monocular videos has recently been explored for space-time novel view synthesis and achieved excellent results. However, defocus blur caused by depth variation often occurs in video capture, compromising the quality of dynamic reconstruction because the lack of sharp details interferes with modeling temporal consistency between input views. To tackle this issue, we propose D2RF, the first dynamic NeRF method designed to restore sharp novel views from defocused monocular videos. We introduce layered Depth-of-Field (DoF) volume rendering to model the defocus blur and reconstruct a sharp NeRF supervised by defocused views. The blur model is inspired by the connection between DoF rendering and volume rendering. The opacity in volume rendering aligns with the layer visibility in DoF rendering.To execute the blurring, we modify the layered blur kernel to the ray-based kernel and employ an optimized sparse kernel to gather the input rays efficiently and render the optimized rays with our layered DoF volume rendering. We synthesize a dataset with defocused dynamic scenes for our task, and extensive experiments on our dataset show that our method outperforms existing approaches in synthesizing all-in-focus novel views from defocus blur while maintaining spatial-temporal consistency in the scene.
Make-It-4D: Synthesizing a Consistent Long-Term Dynamic Scene Video from a Single Image
Aug 20, 2023
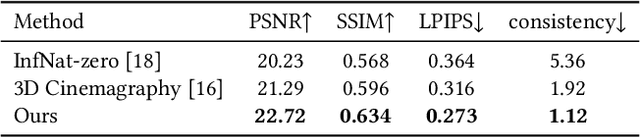
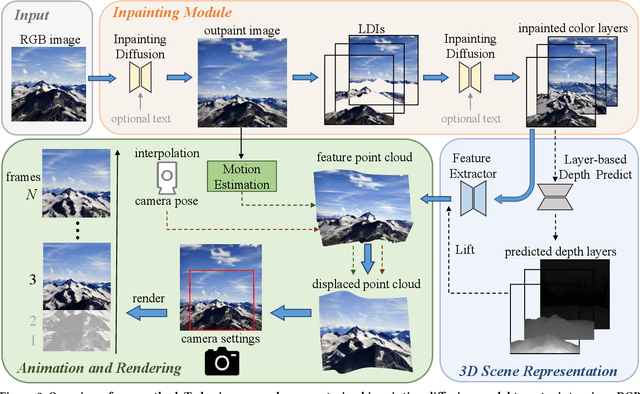
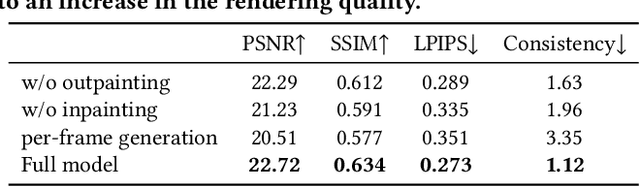
We study the problem of synthesizing a long-term dynamic video from only a single image. This is challenging since it requires consistent visual content movements given large camera motions. Existing methods either hallucinate inconsistent perpetual views or struggle with long camera trajectories. To address these issues, it is essential to estimate the underlying 4D (including 3D geometry and scene motion) and fill in the occluded regions. To this end, we present Make-It-4D, a novel method that can generate a consistent long-term dynamic video from a single image. On the one hand, we utilize layered depth images (LDIs) to represent a scene, and they are then unprojected to form a feature point cloud. To animate the visual content, the feature point cloud is displaced based on the scene flow derived from motion estimation and the corresponding camera pose. Such 4D representation enables our method to maintain the global consistency of the generated dynamic video. On the other hand, we fill in the occluded regions by using a pretrained diffusion model to inpaint and outpaint the input image. This enables our method to work under large camera motions. Benefiting from our design, our method can be training-free which saves a significant amount of training time. Experimental results demonstrate the effectiveness of our approach, which showcases compelling rendering results.
Defocus to focus: Photo-realistic bokeh rendering by fusing defocus and radiance priors
Jun 07, 2023



We consider the problem of realistic bokeh rendering from a single all-in-focus image. Bokeh rendering mimics aesthetic shallow depth-of-field (DoF) in professional photography, but these visual effects generated by existing methods suffer from simple flat background blur and blurred in-focus regions, giving rise to unrealistic rendered results. In this work, we argue that realistic bokeh rendering should (i) model depth relations and distinguish in-focus regions, (ii) sustain sharp in-focus regions, and (iii) render physically accurate Circle of Confusion (CoC). To this end, we present a Defocus to Focus (D2F) framework to learn realistic bokeh rendering by fusing defocus priors with the all-in-focus image and by implementing radiance priors in layered fusion. Since no depth map is provided, we introduce defocus hallucination to integrate depth by learning to focus. The predicted defocus map implies the blur amount of bokeh and is used to guide weighted layered rendering. In layered rendering, we fuse images blurred by different kernels based on the defocus map. To increase the reality of the bokeh, we adopt radiance virtualization to simulate scene radiance. The scene radiance used in weighted layered rendering reassigns weights in the soft disk kernel to produce the CoC. To ensure the sharpness of in-focus regions, we propose to fuse upsampled bokeh images and original images. We predict the initial fusion mask from our defocus map and refine the mask with a deep network. We evaluate our model on a large-scale bokeh dataset. Extensive experiments show that our approach is capable of rendering visually pleasing bokeh effects in complex scenes. In particular, our solution receives the runner-up award in the AIM 2020 Rendering Realistic Bokeh Challenge.
* Published at Information Fusion 2023 https://www.sciencedirect.com/science/article/pii/S1566253522001221
Point-and-Shoot All-in-Focus Photo Synthesis from Smartphone Camera Pair
Apr 11, 2023



All-in-Focus (AIF) photography is expected to be a commercial selling point for modern smartphones. Standard AIF synthesis requires manual, time-consuming operations such as focal stack compositing, which is unfriendly to ordinary people. To achieve point-and-shoot AIF photography with a smartphone, we expect that an AIF photo can be generated from one shot of the scene, instead of from multiple photos captured by the same camera. Benefiting from the multi-camera module in modern smartphones, we introduce a new task of AIF synthesis from main (wide) and ultra-wide cameras. The goal is to recover sharp details from defocused regions in the main-camera photo with the help of the ultra-wide-camera one. The camera setting poses new challenges such as parallax-induced occlusions and inconsistent color between cameras. To overcome the challenges, we introduce a predict-and-refine network to mitigate occlusions and propose dynamic frequency-domain alignment for color correction. To enable effective training and evaluation, we also build an AIF dataset with 2686 unique scenes. Each scene includes two photos captured by the main camera, one photo captured by the ultrawide camera, and a synthesized AIF photo. Results show that our solution, termed EasyAIF, can produce high-quality AIF photos and outperforms strong baselines quantitatively and qualitatively. For the first time, we demonstrate point-and-shoot AIF photo synthesis successfully from main and ultra-wide cameras.
DoF-NeRF: Depth-of-Field Meets Neural Radiance Fields
Aug 01, 2022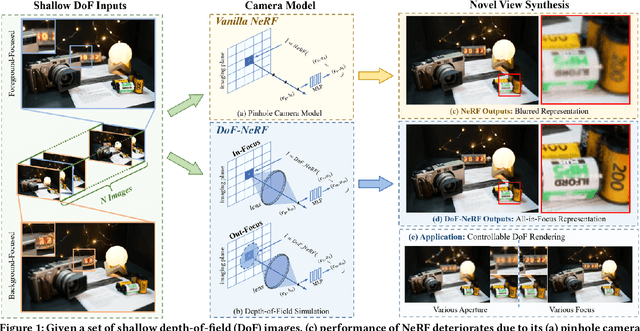
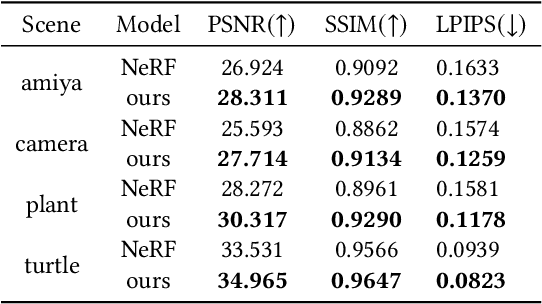
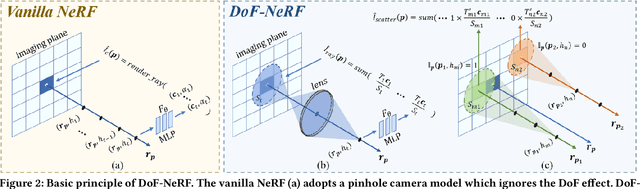
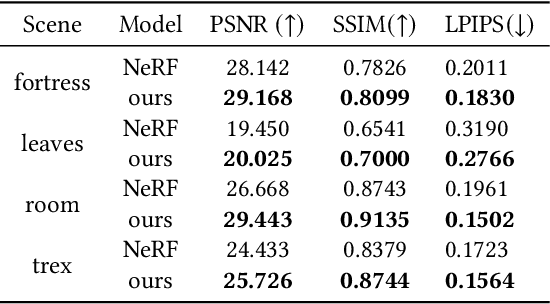
Neural Radiance Field (NeRF) and its variants have exhibited great success on representing 3D scenes and synthesizing photo-realistic novel views. However, they are generally based on the pinhole camera model and assume all-in-focus inputs. This limits their applicability as images captured from the real world often have finite depth-of-field (DoF). To mitigate this issue, we introduce DoF-NeRF, a novel neural rendering approach that can deal with shallow DoF inputs and can simulate DoF effect. In particular, it extends NeRF to simulate the aperture of lens following the principles of geometric optics. Such a physical guarantee allows DoF-NeRF to operate views with different focus configurations. Benefiting from explicit aperture modeling, DoF-NeRF also enables direct manipulation of DoF effect by adjusting virtual aperture and focus parameters. It is plug-and-play and can be inserted into NeRF-based frameworks. Experiments on synthetic and real-world datasets show that, DoF-NeRF not only performs comparably with NeRF in the all-in-focus setting, but also can synthesize all-in-focus novel views conditioned on shallow DoF inputs. An interesting application of DoF-NeRF to DoF rendering is also demonstrated. The source code will be made available at https://github.com/zijinwuzijin/DoF-NeRF.
MPIB: An MPI-Based Bokeh Rendering Framework for Realistic Partial Occlusion Effects
Jul 18, 2022
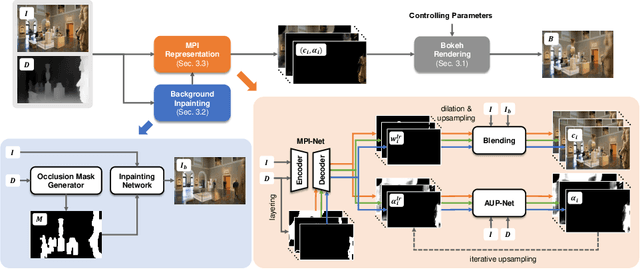

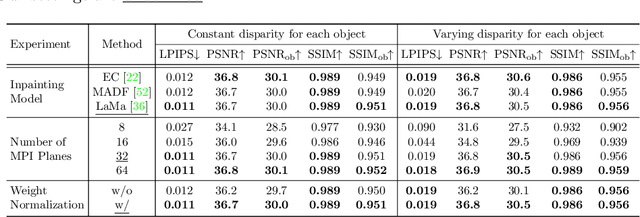
Partial occlusion effects are a phenomenon that blurry objects near a camera are semi-transparent, resulting in partial appearance of occluded background. However, it is challenging for existing bokeh rendering methods to simulate realistic partial occlusion effects due to the missing information of the occluded area in an all-in-focus image. Inspired by the learnable 3D scene representation, Multiplane Image (MPI), we attempt to address the partial occlusion by introducing a novel MPI-based high-resolution bokeh rendering framework, termed MPIB. To this end, we first present an analysis on how to apply the MPI representation to bokeh rendering. Based on this analysis, we propose an MPI representation module combined with a background inpainting module to implement high-resolution scene representation. This representation can then be reused to render various bokeh effects according to the controlling parameters. To train and test our model, we also design a ray-tracing-based bokeh generator for data generation. Extensive experiments on synthesized and real-world images validate the effectiveness and flexibility of this framework.
BokehMe: When Neural Rendering Meets Classical Rendering
Jun 25, 2022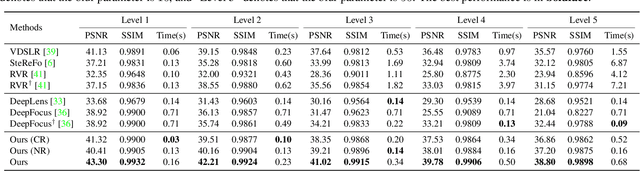
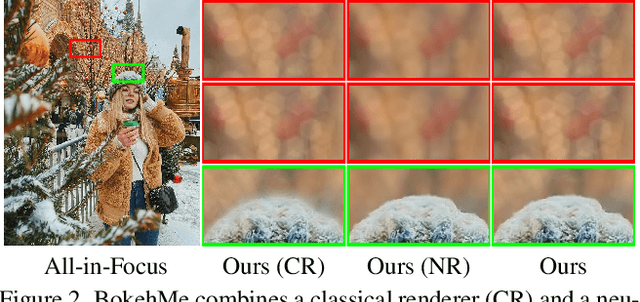
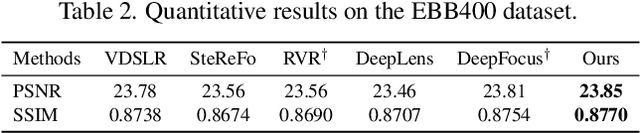
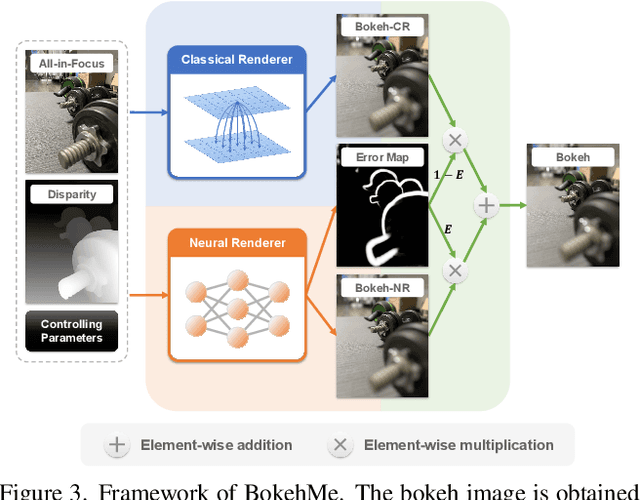
We propose BokehMe, a hybrid bokeh rendering framework that marries a neural renderer with a classical physically motivated renderer. Given a single image and a potentially imperfect disparity map, BokehMe generates high-resolution photo-realistic bokeh effects with adjustable blur size, focal plane, and aperture shape. To this end, we analyze the errors from the classical scattering-based method and derive a formulation to calculate an error map. Based on this formulation, we implement the classical renderer by a scattering-based method and propose a two-stage neural renderer to fix the erroneous areas from the classical renderer. The neural renderer employs a dynamic multi-scale scheme to efficiently handle arbitrary blur sizes, and it is trained to handle imperfect disparity input. Experiments show that our method compares favorably against previous methods on both synthetic image data and real image data with predicted disparity. A user study is further conducted to validate the advantage of our method.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.