 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABot-Earth 0.5: Generative 3D Earth Model
Jun 08, 2026We present ABot-Earth 0.5, a generative 3D framework designed to synthesize vast, seamless 3D environments from ubiquitous, geospatially referenced satellite imagery. To achieve this, we propose a novel generative model formulated directly with the 3D Gaussian Splatting (3DGS) representation. The model is trained on a diverse corpus of existing real-world urban reconstructions, learning to generate realistic geometry and textures. At inference, it synthesizes novel 3D scenes conditioned solely on satellite imagery at a scalable rate of under 10 minutes per square kilometer, while demonstrating exceptional realism. The framework is designed for accessibility, with integrated hierarchical level-of-detail (LOD) structures that permit real-time, interactive visualization on web-based map engines. This high-fidelity simulation sandbox effectively mitigates the sim-to-real domain gap, enabling critical downstream Embodied AI applications like closed-loop UAV navigation. By providing an ultra-low-cost and high-efficiency solution, ABot-Earth 0.5 significantly lowers the technical and financial barriers to large-scale 3D reconstruction and empowers the future of global digital earth visualization.
Sat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image
May 14, 2026Generating a street-level 3D scene from a single satellite image is a crucial yet challenging task. Current methods present a stark trade-off: geometry-colorization models achieve high geometric fidelity but are typically building-focused and lack semantic diversity. In contrast, proxy-based models use feed-forward image-to-3D frameworks to generate holistic scenes by jointly learning geometry and texture, a process that yields rich content but coarse and unstable geometry. We attribute these geometric failures to the extreme viewpoint gap and sparse, inconsistent supervision inherent in satellite-to-street data. We introduce Sat3DGen to address these fundamental challenges, which embodies a geometry-first methodology. This methodology enhances the feed-forward paradigm by integrating novel geometric constraints with a perspective-view training strategy, explicitly countering the primary sources of geometric error. This geometry-centric strategy yields a dramatic leap in both 3D accuracy and photorealism. For validation, we first constructed a new benchmark by pairing the VIGOR-OOD test set with high-resolution DSM data. On this benchmark, our method improves geometric RMSE from 6.76m to 5.20m. Crucially, this geometric leap also boosts photorealism, reducing the Fréchet Inception Distance (FID) from $\sim$40 to 19 against the leading method, Sat2Density++, despite using no extra tailored image-quality modules. We demonstrate the versatility of our high-quality 3D assets through diverse downstream applications, including semantic-map-to-3D synthesis, multi-camera video generation, large-scale meshing, and unsupervised single-image Digital Surface Model (DSM) estimation. The code has been released on https://github.com/qianmingduowan/Sat3DGen.
Seeing through Satellite Images at Street Views
May 22, 2025This paper studies the task of SatStreet-view synthesis, which aims to render photorealistic street-view panorama images and videos given any satellite image and specified camera positions or trajectories. We formulate to learn neural radiance field from paired images captured from satellite and street viewpoints, which comes to be a challenging learning problem due to the sparse-view natural and the extremely-large viewpoint changes between satellite and street-view images. We tackle the challenges based on a task-specific observation that street-view specific elements, including the sky and illumination effects are only visible in street-view panoramas, and present a novel approach Sat2Density++ to accomplish the goal of photo-realistic street-view panoramas rendering by modeling these street-view specific in neural networks. In the experiments, our method is testified on both urban and suburban scene datasets, demonstrating that Sat2Density++ is capable of rendering photorealistic street-view panoramas that are consistent across multiple views and faithful to the satellite image.
Multi-View Attentive Contextualization for Multi-View 3D Object Detection
May 20, 2024



We present Multi-View Attentive Contextualization (MvACon), a simple yet effective method for improving 2D-to-3D feature lifting in query-based multi-view 3D (MV3D) object detection. Despite remarkable progress witnessed in the field of query-based MV3D object detection, prior art often suffers from either the lack of exploiting high-resolution 2D features in dense attention-based lifting, due to high computational costs, or from insufficiently dense grounding of 3D queries to multi-scale 2D features in sparse attention-based lifting. Our proposed MvACon hits the two birds with one stone using a representationally dense yet computationally sparse attentive feature contextualization scheme that is agnostic to specific 2D-to-3D feature lifting approaches. In experiments, the proposed MvACon is thoroughly tested on the nuScenes benchmark, using both the BEVFormer and its recent 3D deformable attention (DFA3D) variant, as well as the PETR, showing consistent detection performance improvement, especially in enhancing performance in location, orientation, and velocity prediction. It is also tested on the Waymo-mini benchmark using BEVFormer with similar improvement. We qualitatively and quantitatively show that global cluster-based contexts effectively encode dense scene-level contexts for MV3D object detection. The promising results of our proposed MvACon reinforces the adage in computer vision -- ``(contextualized) feature matters".
Unleashing Unlabeled Data: A Paradigm for Cross-View Geo-Localization
Mar 21, 2024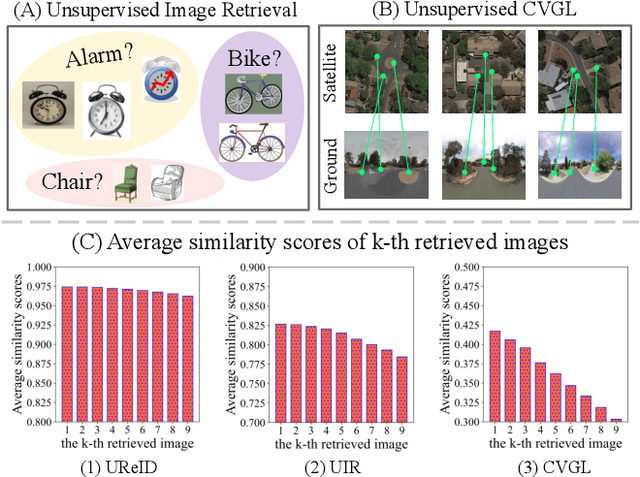
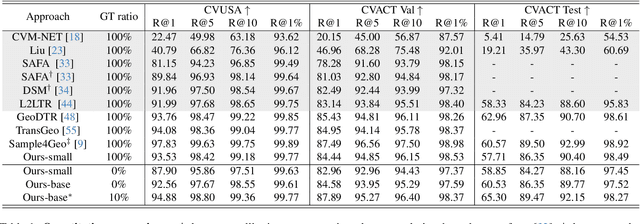
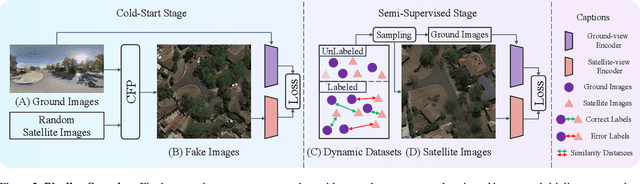
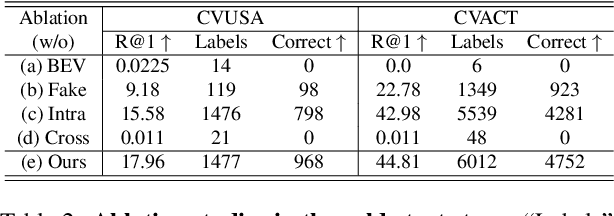
This paper investigates the effective utilization of unlabeled data for large-area cross-view geo-localization (CVGL), encompassing both unsupervised and semi-supervised settings. Common approaches to CVGL rely on ground-satellite image pairs and employ label-driven supervised training. However, the cost of collecting precise cross-view image pairs hinders the deployment of CVGL in real-life scenarios. Without the pairs, CVGL will be more challenging to handle the significant imaging and spatial gaps between ground and satellite images. To this end, we propose an unsupervised framework including a cross-view projection to guide the model for retrieving initial pseudo-labels and a fast re-ranking mechanism to refine the pseudo-labels by leveraging the fact that ``the perfectly paired ground-satellite image is located in a unique and identical scene". The framework exhibits competitive performance compared with supervised works on three open-source benchmarks. Our code and models will be released on https://github.com/liguopeng0923/UCVGL.
Depth and DOF Cues Make A Better Defocus Blur Detector
Jun 20, 2023


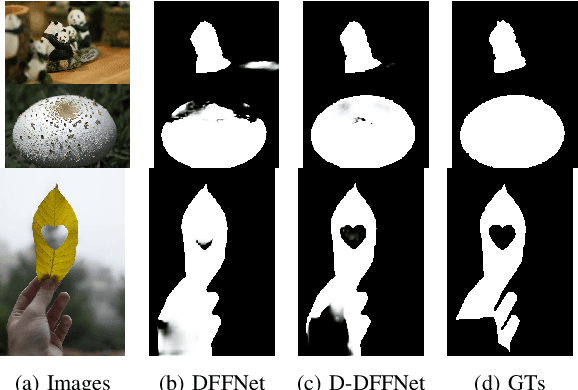
Defocus blur detection (DBD) separates in-focus and out-of-focus regions in an image. Previous approaches mistakenly mistook homogeneous areas in focus for defocus blur regions, likely due to not considering the internal factors that cause defocus blur. Inspired by the law of depth, depth of field (DOF), and defocus, we propose an approach called D-DFFNet, which incorporates depth and DOF cues in an implicit manner. This allows the model to understand the defocus phenomenon in a more natural way. Our method proposes a depth feature distillation strategy to obtain depth knowledge from a pre-trained monocular depth estimation model and uses a DOF-edge loss to understand the relationship between DOF and depth. Our approach outperforms state-of-the-art methods on public benchmarks and a newly collected large benchmark dataset, EBD. Source codes and EBD dataset are available at: https:github.com/yuxinjin-whu/D-DFFNet.
Sat2Density: Faithful Density Learning from Satellite-Ground Image Pairs
Mar 26, 2023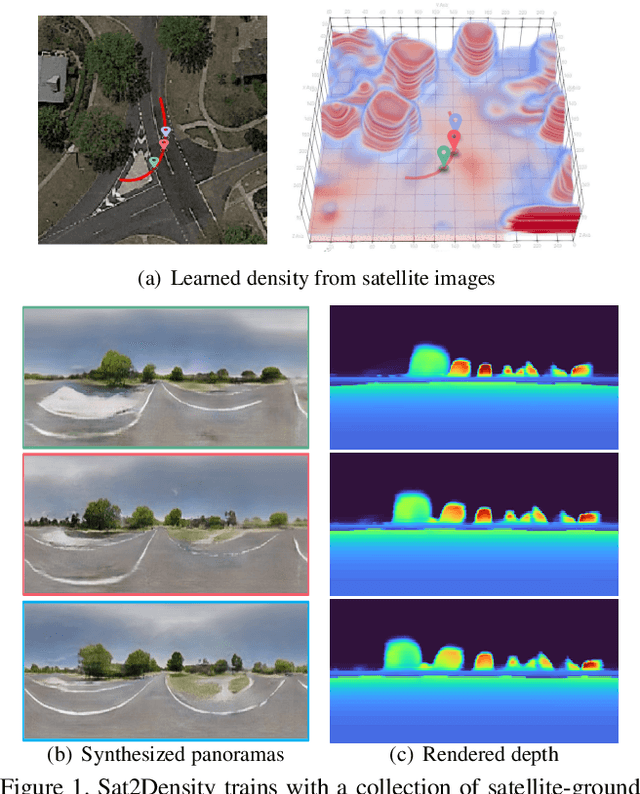
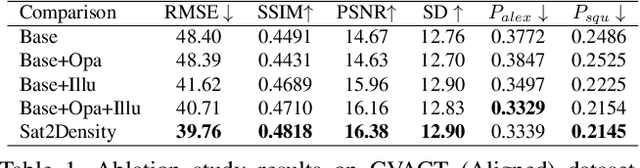
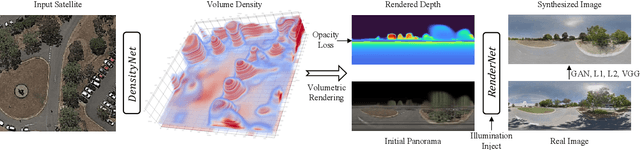

This paper aims to develop an accurate 3D geometry representation of satellite images using satellite-ground image pairs. Our focus is on the challenging problem of generating ground-view panoramas from satellite images. We draw inspiration from the density field representation used in volumetric neural rendering and propose a new approach, called Sat2Density. Our method utilizes the properties of ground-view panoramas for the sky and non-sky regions to learn faithful density fields of 3D scenes in a geometric perspective. Unlike other methods that require extra 3D information during training, our Sat2Density can automatically learn the accurate and faithful 3D geometry via density representation from 2D-only supervision. This advancement significantly improves the ground-view panorama synthesis task. Additionally, our study provides a new geometric perspective to understand the relationship between satellite and ground-view images in 3D space.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021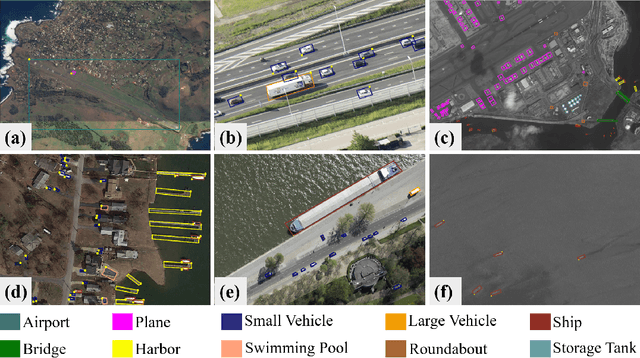

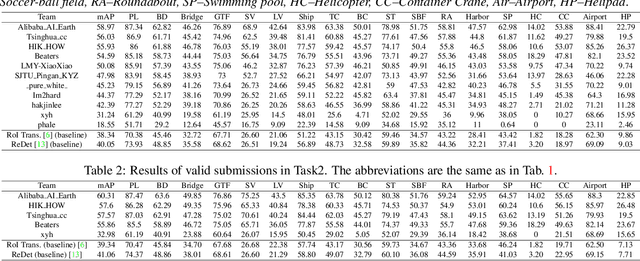
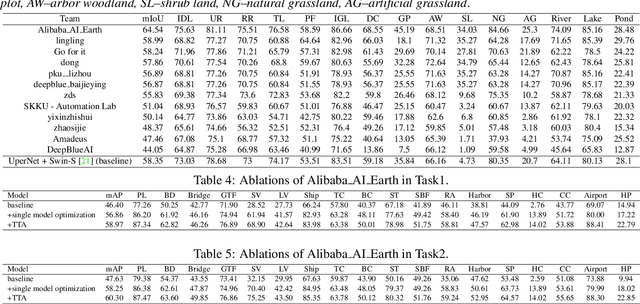
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.
Defocus Blur Detection via Salient Region Detection Prior
Nov 19, 2020
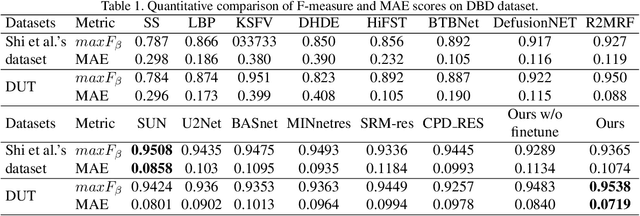


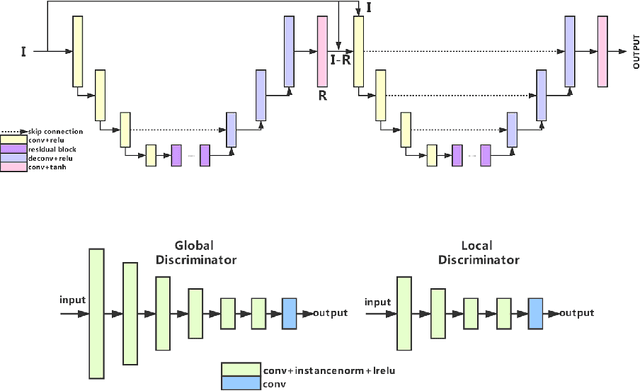
Defocus blur always occurred in photos when people take photos by Digital Single Lens Reflex Camera(DSLR), giving salient region and aesthetic pleasure. Defocus blur Detection aims to separate the out-of-focus and depth-of-field areas in photos, which is an important work in computer vision. Current works for defocus blur detection mainly focus on the designing of networks, the optimizing of the loss function, and the application of multi-stream strategy, meanwhile, these works do not pay attention to the shortage of training data. In this work, to address the above data-shortage problem, we turn to rethink the relationship between two tasks: defocus blur detection and salient region detection. In an image with bokeh effect, it is obvious that the salient region and the depth-of-field area overlap in most cases. So we first train our network on the salient region detection tasks, then transfer the pre-trained model to the defocus blur detection tasks. Besides, we propose a novel network for defocus blur detection. Experiments show that our transfer strategy works well on many current models, and demonstrate the superiority of our network.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020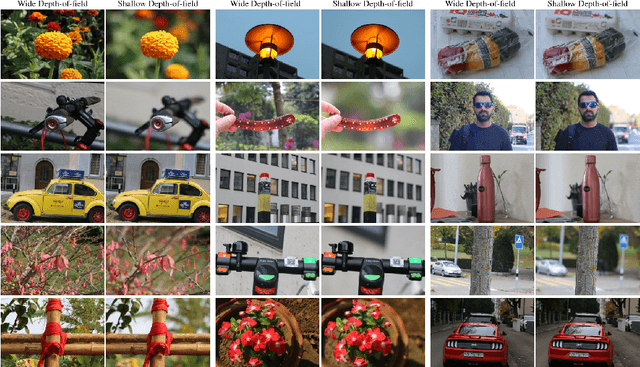


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.