 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOP-Q: Safety-First Reinforcement Learning for Robot Control via Cholesky-Ordered Projection
Jun 03, 2026Safe robot control requires maximizing return while satisfying safety constraints. In off-policy safe reinforcement learning, reward and safety Q-values are commonly learned by separate critic ensembles, with uncertainty handled independently for each objective. This objective-wise treatment neglects inter-objective correlation and can lead to overly conservative value estimates, thereby reducing sample efficiency. To address this issue, we propose Cholesky-Ordered Projection Q-learning (COP-Q), a safety-first method that incorporates inter-objective covariance into vector-valued Q-value estimation. COP-Q constructs a generalized confidence bound in the joint Q-value space and uses Cholesky factorization to encode objective priority in a sequential form. This preserves conservatism on safety while adaptively reducing excessive conservatism on the reward objective. The resulting estimate is used in both temporal-difference target computation and actor optimization. COP-Q incurs minimal computational overhead and is readily compatible with most existing deep Q-learning frameworks. Experiments on robot locomotion in Brax and safe navigation in Safety-Gymnasium, covering both hard- and soft-safety settings, demonstrate that COP-Q achieves strong safety performance together with competitive or improved sample efficiency relative to representative baselines.
Off-Policy Safe Reinforcement Learning with Constrained Optimistic Exploration
Mar 25, 2026When safety is formulated as a limit of cumulative cost, safe reinforcement learning (RL) aims to learn policies that maximize return subject to the cost constraint in data collection and deployment. Off-policy safe RL methods, although offering high sample efficiency, suffer from constraint violations due to cost-agnostic exploration and estimation bias in cumulative cost. To address this issue, we propose Constrained Optimistic eXploration Q-learning (COX-Q), an off-policy safe RL algorithm that integrates cost-bounded online exploration and conservative offline distributional value learning. First, we introduce a novel cost-constrained optimistic exploration strategy that resolves gradient conflicts between reward and cost in the action space and adaptively adjusts the trust region to control the training cost. Second, we adopt truncated quantile critics to stabilize the cost value learning. Quantile critics also quantify epistemic uncertainty to guide exploration. Experiments on safe velocity, safe navigation, and autonomous driving tasks demonstrate that COX-Q achieves high sample efficiency, competitive test safety performance, and controlled data collection cost. The results highlight COX-Q as a promising RL method for safety-critical applications.
PEARL: Personalized Streaming Video Understanding Model
Mar 20, 2026Human cognition of new concepts is inherently a streaming process: we continuously recognize new objects or identities and update our memories over time. However, current multimodal personalization methods are largely limited to static images or offline videos. This disconnects continuous visual input from instant real-world feedback, limiting their ability to provide the real-time, interactive personalized responses essential for future AI assistants. To bridge this gap, we first propose and formally define the novel task of Personalized Streaming Video Understanding (PSVU). To facilitate research in this new direction, we introduce PEARL-Bench, the first comprehensive benchmark designed specifically to evaluate this challenging setting. It evaluates a model's ability to respond to personalized concepts at exact timestamps under two modes: (1) Frame-level, focusing on a specific person or object in discrete frames, and (2) a novel Video-level, focusing on personalized actions unfolding across continuous frames. PEARL-Bench comprises 132 unique videos and 2,173 fine-grained annotations with precise timestamps. Concept diversity and annotation quality are strictly ensured through a combined pipeline of automated generation and human verification. To tackle this challenging new setting, we further propose PEARL, a plug-and-play, training-free strategy that serves as a strong baseline. Extensive evaluations across 8 offline and online models demonstrate that PEARL achieves state-of-the-art performance. Notably, it brings consistent PSVU improvements when applied to 3 distinct architectures, proving to be a highly effective and robust strategy. We hope this work advances vision-language model (VLM) personalization and inspires further research into streaming personalized AI assistants. Code is available at https://github.com/Yuanhong-Zheng/PEARL.
GENIUS: Generative Fluid Intelligence Evaluation Suite
Feb 11, 2026Unified Multimodal Models (UMMs) have shown remarkable progress in visual generation. Yet, existing benchmarks predominantly assess $\textit{Crystallized Intelligence}$, which relies on recalling accumulated knowledge and learned schemas. This focus overlooks $\textit{Generative Fluid Intelligence (GFI)}$: the capacity to induce patterns, reason through constraints, and adapt to novel scenarios on the fly. To rigorously assess this capability, we introduce $\textbf{GENIUS}$ ($\textbf{GEN}$ Fluid $\textbf{I}$ntelligence Eval$\textbf{U}$ation $\textbf{S}$uite). We formalize $\textit{GFI}$ as a synthesis of three primitives. These include $\textit{Inducing Implicit Patterns}$ (e.g., inferring personalized visual preferences), $\textit{Executing Ad-hoc Constraints}$ (e.g., visualizing abstract metaphors), and $\textit{Adapting to Contextual Knowledge}$ (e.g., simulating counter-intuitive physics). Collectively, these primitives challenge models to solve problems grounded entirely in the immediate context. Our systematic evaluation of 12 representative models reveals significant performance deficits in these tasks. Crucially, our diagnostic analysis disentangles these failure modes. It demonstrates that deficits stem from limited context comprehension rather than insufficient intrinsic generative capability. To bridge this gap, we propose a training-free attention intervention strategy. Ultimately, $\textbf{GENIUS}$ establishes a rigorous standard for $\textit{GFI}$, guiding the field beyond knowledge utilization toward dynamic, general-purpose reasoning. Our dataset and code will be released at: $\href{https://github.com/arctanxarc/GENIUS}{https://github.com/arctanxarc/GENIUS}$.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
GEBench: Benchmarking Image Generation Models as GUI Environments
Feb 09, 2026Recent advancements in image generation models have enabled the prediction of future Graphical User Interface (GUI) states based on user instructions. However, existing benchmarks primarily focus on general domain visual fidelity, leaving the evaluation of state transitions and temporal coherence in GUI-specific contexts underexplored. To address this gap, we introduce GEBench, a comprehensive benchmark for evaluating dynamic interaction and temporal coherence in GUI generation. GEBench comprises 700 carefully curated samples spanning five task categories, covering both single-step interactions and multi-step trajectories across real-world and fictional scenarios, as well as grounding point localization. To support systematic evaluation, we propose GE-Score, a novel five-dimensional metric that assesses Goal Achievement, Interaction Logic, Content Consistency, UI Plausibility, and Visual Quality. Extensive evaluations on current models indicate that while they perform well on single-step transitions, they struggle significantly with maintaining temporal coherence and spatial grounding over longer interaction sequences. Our findings identify icon interpretation, text rendering, and localization precision as critical bottlenecks. This work provides a foundation for systematic assessment and suggests promising directions for future research toward building high-fidelity generative GUI environments. The code is available at: https://github.com/stepfun-ai/GEBench.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Astraea: A State-Aware Scheduling Engine for LLM-Powered Agents
Dec 16, 2025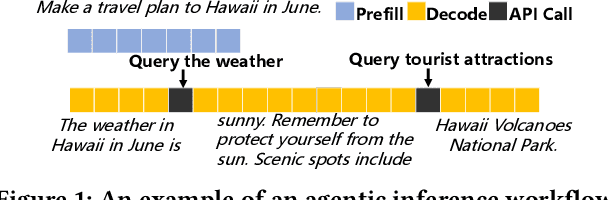
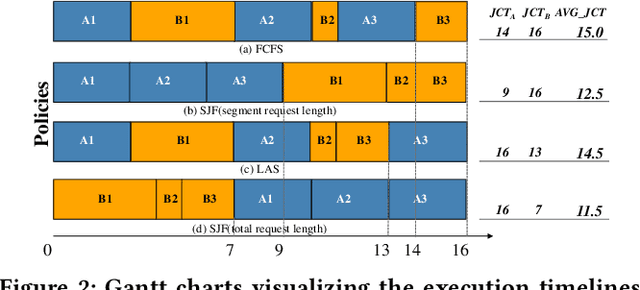
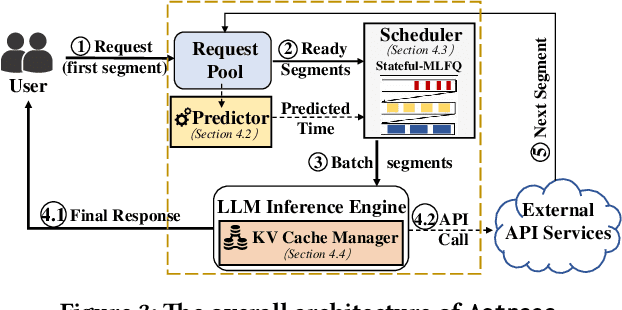
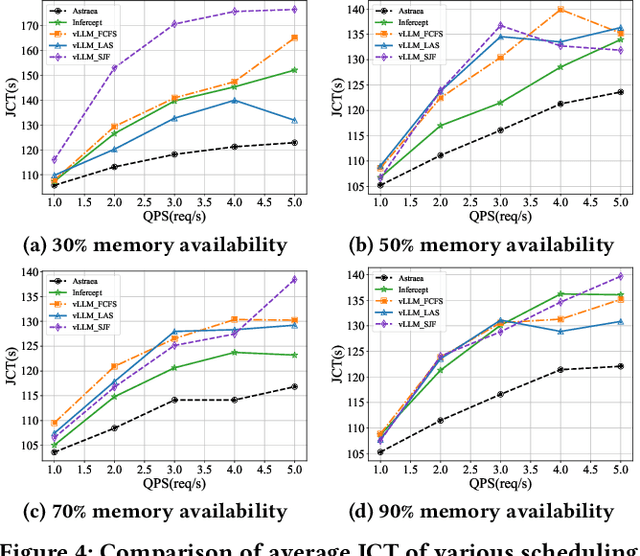
Large Language Models (LLMs) are increasingly being deployed as intelligent agents. Their multi-stage workflows, which alternate between local computation and calls to external network services like Web APIs, introduce a mismatch in their execution pattern and the scheduling granularity of existing inference systems such as vLLM. Existing systems typically focus on per-segment optimization which prevents them from minimizing the end-to-end latency of the complete agentic workflow, i.e., the global Job Completion Time (JCT) over the entire request lifecycle. To address this limitation, we propose Astraea, a service engine designed to shift the optimization from local segments to the global request lifecycle. Astraea employs a state-aware, hierarchical scheduling algorithm that integrates a request's historical state with future predictions. It dynamically classifies requests by their I/O and compute intensive nature and uses an enhanced HRRN policy to balance efficiency and fairness. Astraea also implements an adaptive KV cache manager that intelligently handles the agent state during I/O waits based on the system memory pressure. Extensive experiments show that Astraea reduces average JCT by up to 25.5\% compared to baseline methods. Moreover, our approach demonstrates strong robustness and stability under high load across various model scales.