 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-preserving contrastive learning for spatial time series
Feb 10, 2025



Informative representations enhance model performance and generalisability in downstream tasks. However, learning self-supervised representations for spatially characterised time series, like traffic interactions, poses challenges as it requires maintaining fine-grained similarity relations in the latent space. In this study, we incorporate two structure-preserving regularisers for the contrastive learning of spatial time series: one regulariser preserves the topology of similarities between instances, and the other preserves the graph geometry of similarities across spatial and temporal dimensions. To balance contrastive learning and structure preservation, we propose a dynamic mechanism that adaptively weighs the trade-off and stabilises training. We conduct experiments on multivariate time series classification, as well as macroscopic and microscopic traffic prediction. For all three tasks, our approach preserves the structures of similarity relations more effectively and improves state-of-the-art task performances. The proposed approach can be applied to an arbitrary encoder and is particularly beneficial for time series with spatial or geographical features. Furthermore, this study suggests that higher similarity structure preservation indicates more informative and useful representations. This may help to understand the contribution of representation learning in pattern recognition with neural networks. Our code is made openly accessible with all resulting data at https://github.com/yiru-jiao/spclt.
A unified theory and statistical learning approach for traffic conflict detection
Jul 15, 2024



This study proposes a unified theory and statistical learning approach for traffic conflict detection, addressing the long-existing call for a consistent and comprehensive methodology to evaluate the collision risk emerged in road user interactions. The proposed theory assumes a context-dependent probabilistic collision risk and frames conflict detection as estimating the risk by statistical learning from observed proximities and contextual variables. Three primary tasks are integrated: representing interaction context from selected observables, inferring proximity distributions in different contexts, and applying extreme value theory to relate conflict intensity with conflict probability. As a result, this methodology is adaptable to various road users and interaction scenarios, enhancing its applicability without the need for pre-labelled conflict data. Demonstration experiments are executed using real-world trajectory data, with the unified metric trained on lane-changing interactions on German highways and applied to near-crash events from the 100-Car Naturalistic Driving Study in the U.S. The experiments demonstrate the methodology's ability to provide effective collision warnings, generalise across different datasets and traffic environments, cover a broad range of conflicts, and deliver a long-tailed distribution of conflict intensity. This study contributes to traffic safety by offering a consistent and explainable methodology for conflict detection applicable across various scenarios. Its societal implications include enhanced safety evaluations of traffic infrastructures, more effective collision warning systems for autonomous and driving assistance systems, and a deeper understanding of road user behaviour in different traffic conditions, contributing to a potential reduction in accident rates and improving overall traffic safety.
Pattern retrieval of traffic congestion using graph-based associations of traffic domain-specific features
Nov 28, 2023



The fast-growing amount of traffic data brings many opportunities for revealing more insightful information about traffic dynamics. However, it also demands an effective database management system in which information retrieval is arguably an important feature. The ability to locate similar patterns in big datasets potentially paves the way for further valuable analyses in traffic management. This paper proposes a content-based retrieval system for spatiotemporal patterns of highway traffic congestion. There are two main components in our framework, namely pattern representation and similarity measurement. To effectively interpret retrieval outcomes, the paper proposes a graph-based approach (relation-graph) for the former component, in which fundamental traffic phenomena are encoded as nodes and their spatiotemporal relationships as edges. In the latter component, the similarities between congestion patterns are customizable with various aspects according to user expectations. We evaluated the proposed framework by applying it to a dataset of hundreds of patterns with various complexities (temporally and spatially). The example queries indicate the effectiveness of the proposed method, i.e. the obtained patterns present similar traffic phenomena as in the given examples. In addition, the success of the proposed approach directly derives a new opportunity for semantic retrieval, in which expected patterns are described by adopting the relation-graph notion to associate fundamental traffic phenomena.
Day-to-day and seasonal regularity of network passenger delay for metro networks
Jul 07, 2021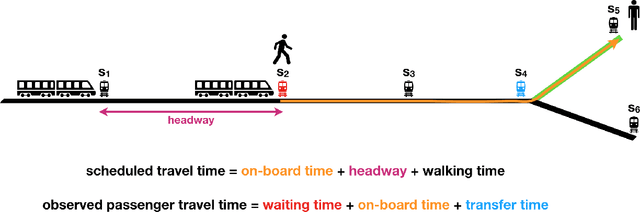
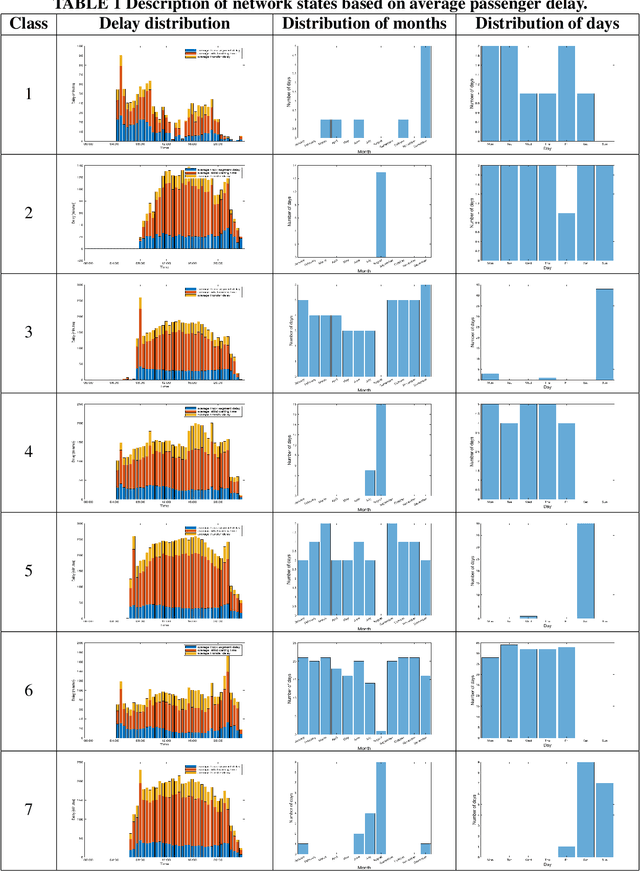
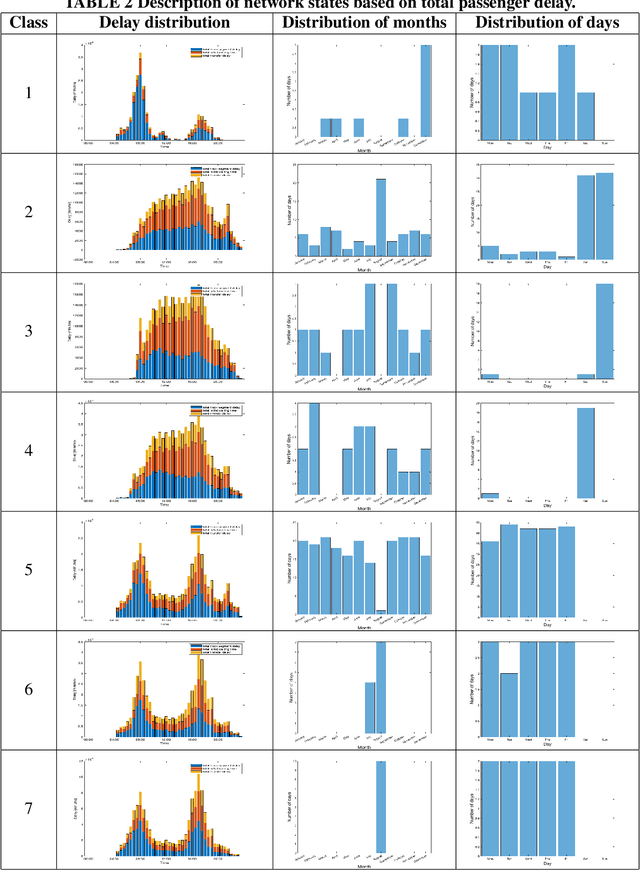
In an effort to improve user satisfaction and transit image, transit service providers worldwide offer delay compensations. Smart card data enables the estimation of passenger delays throughout the network and aid in monitoring service performance. Notwithstanding, in order to prioritize measures for improving service reliability and hence reducing passenger delays, it is paramount to identify the system components - stations and track segments - where most passenger delay occurs. To this end, we propose a novel method for estimating network passenger delay from individual trajectories. We decompose the delay along a passenger trajectory into its corresponding track segment delay, initial waiting time and transfer delay. We distinguish between two different types of passenger delay in relation to the public transit network: average passenger delay and total passenger delay. We employ temporal clustering on these two quantities to reveal daily and seasonal regularity in delay patterns of the transit network. The estimation and clustering methods are demonstrated on one year of data from Washington metro network. The data consists of schedule information and smart card data which includes passenger-train assignment of the metro network for the months of August 2017 to August 2018. Our findings show that the average passenger delay is relatively stable throughout the day. The temporal clustering reveals pronounced and recurrent and thus predictable daily and weekly patterns with distinct characteristics for certain months.