 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
DGAE: Diffusion-Guided Autoencoder for Efficient Latent Representation Learning
Jun 11, 2025Autoencoders empower state-of-the-art image and video generative models by compressing pixels into a latent space through visual tokenization. Although recent advances have alleviated the performance degradation of autoencoders under high compression ratios, addressing the training instability caused by GAN remains an open challenge. While improving spatial compression, we also aim to minimize the latent space dimensionality, enabling more efficient and compact representations. To tackle these challenges, we focus on improving the decoder's expressiveness. Concretely, we propose DGAE, which employs a diffusion model to guide the decoder in recovering informative signals that are not fully decoded from the latent representation. With this design, DGAE effectively mitigates the performance degradation under high spatial compression rates. At the same time, DGAE achieves state-of-the-art performance with a 2x smaller latent space. When integrated with Diffusion Models, DGAE demonstrates competitive performance on image generation for ImageNet-1K and shows that this compact latent representation facilitates faster convergence of the diffusion model.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025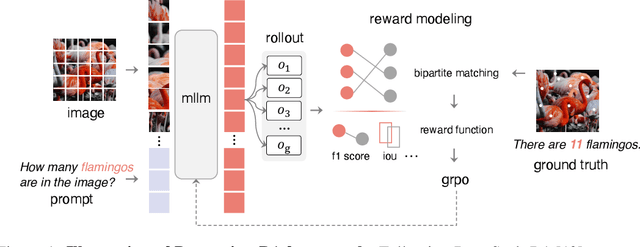
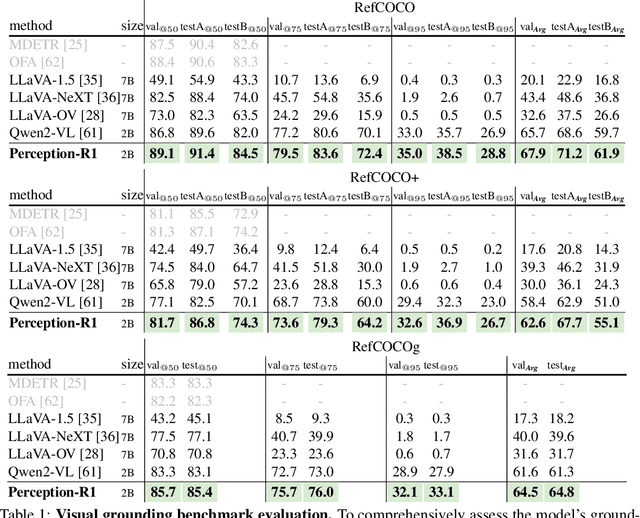
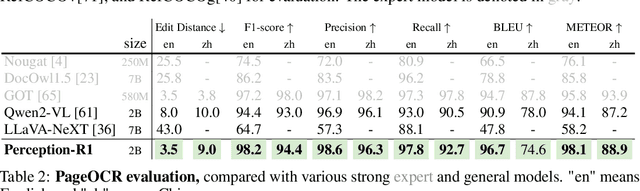
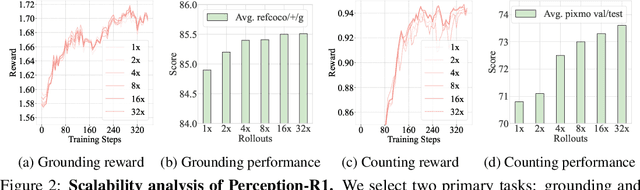
Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
Sep 03, 2024
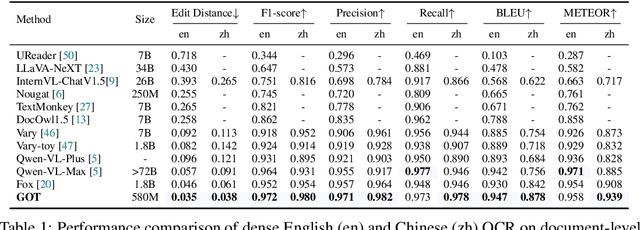
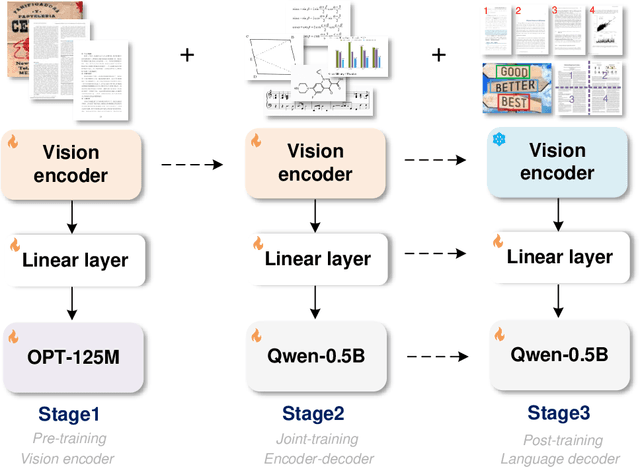

Traditional OCR systems (OCR-1.0) are increasingly unable to meet people's usage due to the growing demand for intelligent processing of man-made optical characters. In this paper, we collectively refer to all artificial optical signals (e.g., plain texts, math/molecular formulas, tables, charts, sheet music, and even geometric shapes) as "characters" and propose the General OCR Theory along with an excellent model, namely GOT, to promote the arrival of OCR-2.0. The GOT, with 580M parameters, is a unified, elegant, and end-to-end model, consisting of a high-compression encoder and a long-contexts decoder. As an OCR-2.0 model, GOT can handle all the above "characters" under various OCR tasks. On the input side, the model supports commonly used scene- and document-style images in slice and whole-page styles. On the output side, GOT can generate plain or formatted results (markdown/tikz/smiles/kern) via an easy prompt. Besides, the model enjoys interactive OCR features, i.e., region-level recognition guided by coordinates or colors. Furthermore, we also adapt dynamic resolution and multi-page OCR technologies to GOT for better practicality. In experiments, we provide sufficient results to prove the superiority of our model.
DreamBench++: A Human-Aligned Benchmark for Personalized Image Generation
Jun 24, 2024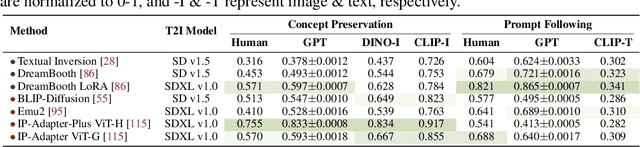



Personalized image generation holds great promise in assisting humans in everyday work and life due to its impressive function in creatively generating personalized content. However, current evaluations either are automated but misalign with humans or require human evaluations that are time-consuming and expensive. In this work, we present DreamBench++, a human-aligned benchmark automated by advanced multimodal GPT models. Specifically, we systematically design the prompts to let GPT be both human-aligned and self-aligned, empowered with task reinforcement. Further, we construct a comprehensive dataset comprising diverse images and prompts. By benchmarking 7 modern generative models, we demonstrate that DreamBench++ results in significantly more human-aligned evaluation, helping boost the community with innovative findings.
Focus Anywhere for Fine-grained Multi-page Document Understanding
May 23, 2024



Modern LVLMs still struggle to achieve fine-grained document understanding, such as OCR/translation/caption for regions of interest to the user, tasks that require the context of the entire page, or even multiple pages. Accordingly, this paper proposes Fox, an effective pipeline, hybrid data, and tuning strategy, that catalyzes LVLMs to focus anywhere on single/multi-page documents. We introduce a novel task to boost the document understanding by making LVLMs focus attention on the document-level region, such as redefining full-page OCR as foreground focus. We employ multiple vision vocabularies to extract visual hybrid knowledge for interleaved document pages (e.g., a page containing a photo). Meanwhile, we render cross-vocabulary vision data as the catalyzer to achieve a full reaction of multiple visual vocabularies and in-document figure understanding. Further, without modifying the weights of multiple vision vocabularies, the above catalyzed fine-grained understanding capabilities can be efficiently tuned to multi-page documents, enabling the model to focus anywhere in both format-free and page-free manners. Besides, we build a benchmark including 9 fine-grained sub-tasks (e.g., region-level OCR/summary, color-guided OCR) to promote document analysis in the community. The experimental results verify the superiority of our model.
OneChart: Purify the Chart Structural Extraction via One Auxiliary Token
Apr 15, 2024


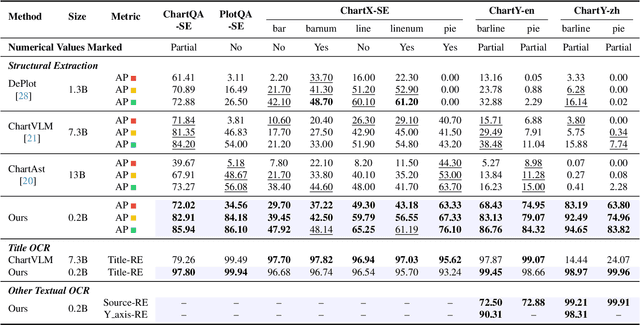
Chart parsing poses a significant challenge due to the diversity of styles, values, texts, and so forth. Even advanced large vision-language models (LVLMs) with billions of parameters struggle to handle such tasks satisfactorily. To address this, we propose OneChart: a reliable agent specifically devised for the structural extraction of chart information. Similar to popular LVLMs, OneChart incorporates an autoregressive main body. Uniquely, to enhance the reliability of the numerical parts of the output, we introduce an auxiliary token placed at the beginning of the total tokens along with an additional decoder. The numerically optimized (auxiliary) token allows subsequent tokens for chart parsing to capture enhanced numerical features through causal attention. Furthermore, with the aid of the auxiliary token, we have devised a self-evaluation mechanism that enables the model to gauge the reliability of its chart parsing results by providing confidence scores for the generated content. Compared to current state-of-the-art (SOTA) chart parsing models, e.g., DePlot, ChartVLM, ChartAst, OneChart significantly outperforms in Average Precision (AP) for chart structural extraction across multiple public benchmarks, despite enjoying only 0.2 billion parameters. Moreover, as a chart parsing agent, it also brings 10%+ accuracy gains for the popular LVLM (LLaVA-1.6) in the downstream ChartQA benchmark.
ShapeLLM: Universal 3D Object Understanding for Embodied Interaction
Mar 06, 2024



This paper presents ShapeLLM, the first 3D Multimodal Large Language Model (LLM) designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. ShapeLLM is built upon an improved 3D encoder by extending ReCon to ReCon++ that benefits from multi-view image distillation for enhanced geometry understanding. By utilizing ReCon++ as the 3D point cloud input encoder for LLMs, ShapeLLM is trained on constructed instruction-following data and tested on our newly human-curated evaluation benchmark, 3D MM-Vet. ReCon++ and ShapeLLM achieve state-of-the-art performance in 3D geometry understanding and language-unified 3D interaction tasks, such as embodied visual grounding.
Small Language Model Meets with Reinforced Vision Vocabulary
Jan 23, 2024Playing Large Vision Language Models (LVLMs) in 2023 is trendy among the AI community. However, the relatively large number of parameters (more than 7B) of popular LVLMs makes it difficult to train and deploy on consumer GPUs, discouraging many researchers with limited resources. Imagine how cool it would be to experience all the features of current LVLMs on an old GTX1080ti (our only game card). Accordingly, we present Vary-toy in this report, a small-size Vary along with Qwen-1.8B as the base ``large'' language model. In Vary-toy, we introduce an improved vision vocabulary, allowing the model to not only possess all features of Vary but also gather more generality. Specifically, we replace negative samples of natural images with positive sample data driven by object detection in the procedure of generating vision vocabulary, more sufficiently utilizing the capacity of the vocabulary network and enabling it to efficiently encode visual information corresponding to natural objects. For experiments, Vary-toy can achieve 65.6% ANLS on DocVQA, 59.1% accuracy on ChartQA, 88.1% accuracy on RefCOCO, and 29% on MMVet. The code will be publicly available on the homepage.