 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
Sep 03, 2024
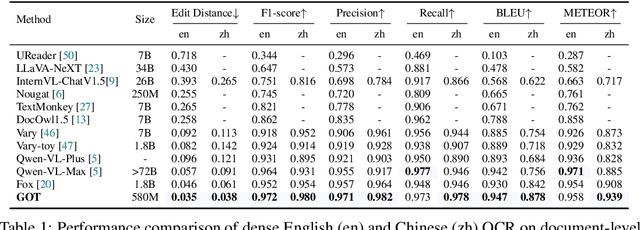
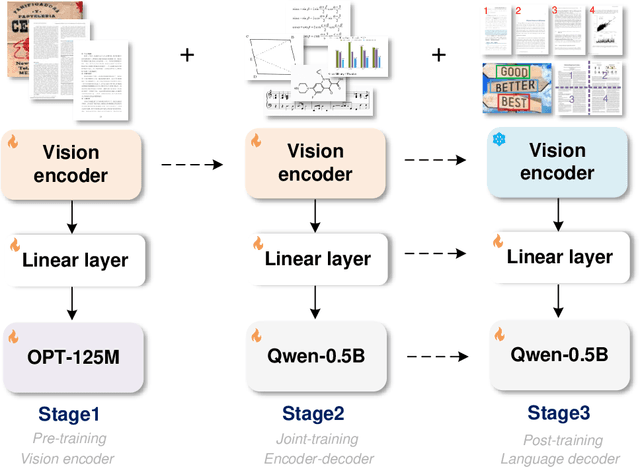

Traditional OCR systems (OCR-1.0) are increasingly unable to meet people's usage due to the growing demand for intelligent processing of man-made optical characters. In this paper, we collectively refer to all artificial optical signals (e.g., plain texts, math/molecular formulas, tables, charts, sheet music, and even geometric shapes) as "characters" and propose the General OCR Theory along with an excellent model, namely GOT, to promote the arrival of OCR-2.0. The GOT, with 580M parameters, is a unified, elegant, and end-to-end model, consisting of a high-compression encoder and a long-contexts decoder. As an OCR-2.0 model, GOT can handle all the above "characters" under various OCR tasks. On the input side, the model supports commonly used scene- and document-style images in slice and whole-page styles. On the output side, GOT can generate plain or formatted results (markdown/tikz/smiles/kern) via an easy prompt. Besides, the model enjoys interactive OCR features, i.e., region-level recognition guided by coordinates or colors. Furthermore, we also adapt dynamic resolution and multi-page OCR technologies to GOT for better practicality. In experiments, we provide sufficient results to prove the superiority of our model.
Focus Anywhere for Fine-grained Multi-page Document Understanding
May 23, 2024



Modern LVLMs still struggle to achieve fine-grained document understanding, such as OCR/translation/caption for regions of interest to the user, tasks that require the context of the entire page, or even multiple pages. Accordingly, this paper proposes Fox, an effective pipeline, hybrid data, and tuning strategy, that catalyzes LVLMs to focus anywhere on single/multi-page documents. We introduce a novel task to boost the document understanding by making LVLMs focus attention on the document-level region, such as redefining full-page OCR as foreground focus. We employ multiple vision vocabularies to extract visual hybrid knowledge for interleaved document pages (e.g., a page containing a photo). Meanwhile, we render cross-vocabulary vision data as the catalyzer to achieve a full reaction of multiple visual vocabularies and in-document figure understanding. Further, without modifying the weights of multiple vision vocabularies, the above catalyzed fine-grained understanding capabilities can be efficiently tuned to multi-page documents, enabling the model to focus anywhere in both format-free and page-free manners. Besides, we build a benchmark including 9 fine-grained sub-tasks (e.g., region-level OCR/summary, color-guided OCR) to promote document analysis in the community. The experimental results verify the superiority of our model.
OneChart: Purify the Chart Structural Extraction via One Auxiliary Token
Apr 15, 2024


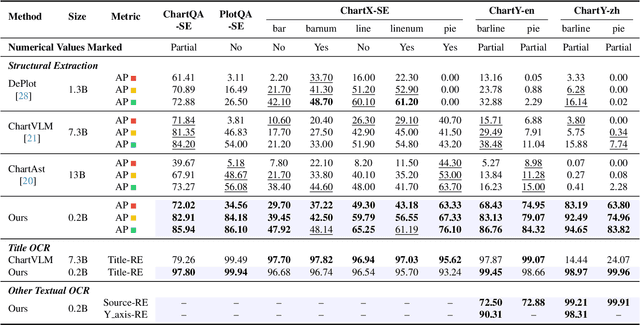
Chart parsing poses a significant challenge due to the diversity of styles, values, texts, and so forth. Even advanced large vision-language models (LVLMs) with billions of parameters struggle to handle such tasks satisfactorily. To address this, we propose OneChart: a reliable agent specifically devised for the structural extraction of chart information. Similar to popular LVLMs, OneChart incorporates an autoregressive main body. Uniquely, to enhance the reliability of the numerical parts of the output, we introduce an auxiliary token placed at the beginning of the total tokens along with an additional decoder. The numerically optimized (auxiliary) token allows subsequent tokens for chart parsing to capture enhanced numerical features through causal attention. Furthermore, with the aid of the auxiliary token, we have devised a self-evaluation mechanism that enables the model to gauge the reliability of its chart parsing results by providing confidence scores for the generated content. Compared to current state-of-the-art (SOTA) chart parsing models, e.g., DePlot, ChartVLM, ChartAst, OneChart significantly outperforms in Average Precision (AP) for chart structural extraction across multiple public benchmarks, despite enjoying only 0.2 billion parameters. Moreover, as a chart parsing agent, it also brings 10%+ accuracy gains for the popular LVLM (LLaVA-1.6) in the downstream ChartQA benchmark.
Small Language Model Meets with Reinforced Vision Vocabulary
Jan 23, 2024Playing Large Vision Language Models (LVLMs) in 2023 is trendy among the AI community. However, the relatively large number of parameters (more than 7B) of popular LVLMs makes it difficult to train and deploy on consumer GPUs, discouraging many researchers with limited resources. Imagine how cool it would be to experience all the features of current LVLMs on an old GTX1080ti (our only game card). Accordingly, we present Vary-toy in this report, a small-size Vary along with Qwen-1.8B as the base ``large'' language model. In Vary-toy, we introduce an improved vision vocabulary, allowing the model to not only possess all features of Vary but also gather more generality. Specifically, we replace negative samples of natural images with positive sample data driven by object detection in the procedure of generating vision vocabulary, more sufficiently utilizing the capacity of the vocabulary network and enabling it to efficiently encode visual information corresponding to natural objects. For experiments, Vary-toy can achieve 65.6% ANLS on DocVQA, 59.1% accuracy on ChartQA, 88.1% accuracy on RefCOCO, and 29% on MMVet. The code will be publicly available on the homepage.
Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Dec 11, 2023



Modern Large Vision-Language Models (LVLMs) enjoy the same vision vocabulary -- CLIP, which can cover most common vision tasks. However, for some special vision task that needs dense and fine-grained vision perception, e.g., document-level OCR or chart understanding, especially in non-English scenarios, the CLIP-style vocabulary may encounter low efficiency in tokenizing the vision knowledge and even suffer out-of-vocabulary problem. Accordingly, we propose Vary, an efficient and effective method to scale up the vision vocabulary of LVLMs. The procedures of Vary are naturally divided into two folds: the generation and integration of a new vision vocabulary. In the first phase, we devise a vocabulary network along with a tiny decoder-only transformer to produce the desired vocabulary via autoregression. In the next, we scale up the vanilla vision vocabulary by merging the new one with the original one (CLIP), enabling the LVLMs can quickly garner new features. Compared to the popular BLIP-2, MiniGPT4, and LLaVA, Vary can maintain its vanilla capabilities while enjoying more excellent fine-grained perception and understanding ability. Specifically, Vary is competent in new document parsing features (OCR or markdown conversion) while achieving 78.2% ANLS in DocVQA and 36.2% in MMVet. Our code will be publicly available on the homepage.