 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025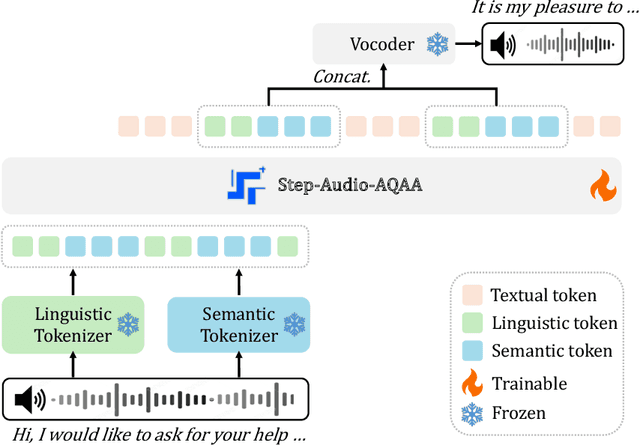
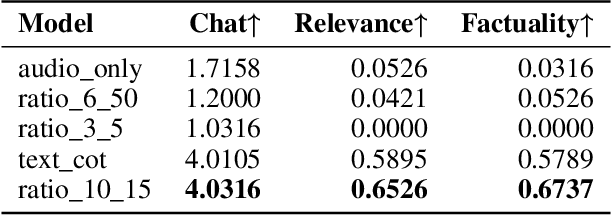
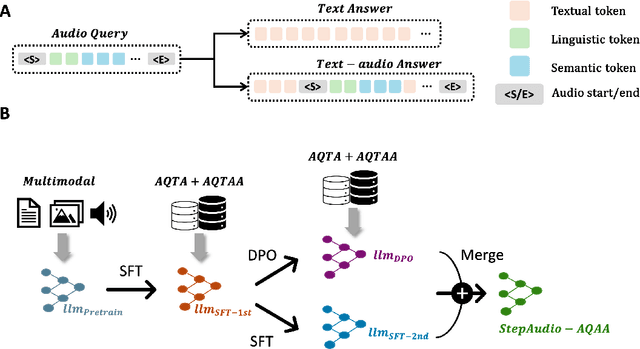

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025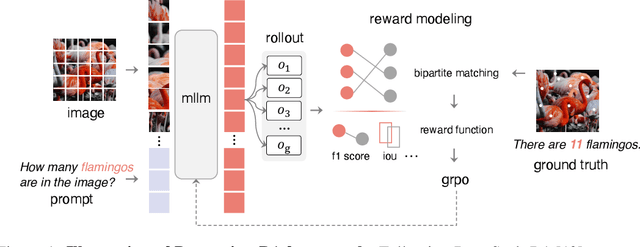
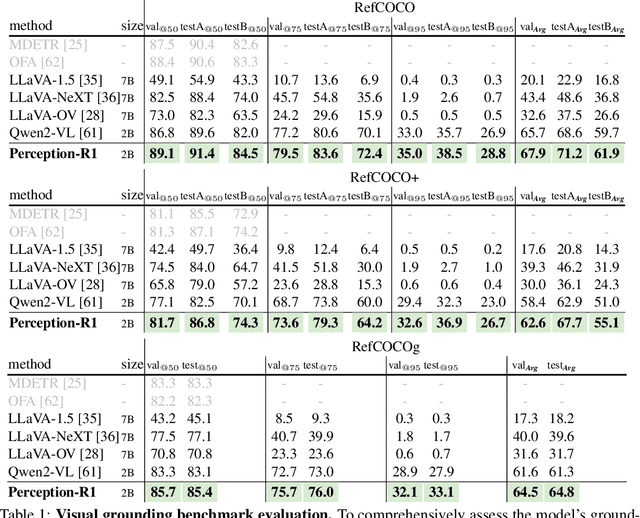
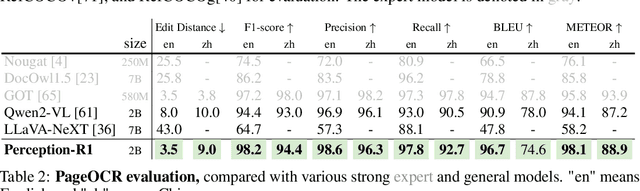
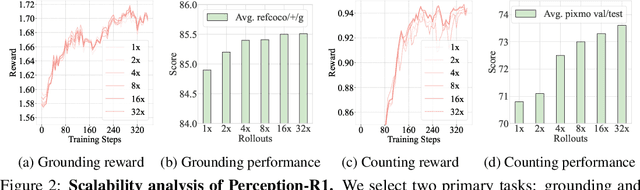
Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
Perception in Reflection
Apr 09, 2025



We present a perception in reflection paradigm designed to transcend the limitations of current large vision-language models (LVLMs), which are expected yet often fail to achieve perfect perception initially. Specifically, we propose Reflective Perception (RePer), a dual-model reflection mechanism that systematically alternates between policy and critic models, enables iterative refinement of visual perception. This framework is powered by Reflective Perceptual Learning (RPL), which reinforces intrinsic reflective capabilities through a methodically constructed visual reflection dataset and reflective unlikelihood training. Comprehensive experimental evaluation demonstrates RePer's quantifiable improvements in image understanding, captioning precision, and hallucination reduction. Notably, RePer achieves strong alignment between model attention patterns and human visual focus, while RPL optimizes fine-grained and free-form preference alignment. These advancements establish perception in reflection as a robust paradigm for future multimodal agents, particularly in tasks requiring complex reasoning and multi-step manipulation.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Unhackable Temporal Rewarding for Scalable Video MLLMs
Feb 17, 2025



In the pursuit of superior video-processing MLLMs, we have encountered a perplexing paradox: the "anti-scaling law", where more data and larger models lead to worse performance. This study unmasks the culprit: "temporal hacking", a phenomenon where models shortcut by fixating on select frames, missing the full video narrative. In this work, we systematically establish a comprehensive theory of temporal hacking, defining it from a reinforcement learning perspective, introducing the Temporal Perplexity (TPL) score to assess this misalignment, and proposing the Unhackable Temporal Rewarding (UTR) framework to mitigate the temporal hacking. Both theoretically and empirically, TPL proves to be a reliable indicator of temporal modeling quality, correlating strongly with frame activation patterns. Extensive experiments reveal that UTR not only counters temporal hacking but significantly elevates video comprehension capabilities. This work not only advances video-AI systems but also illuminates the critical importance of aligning proxy rewards with true objectives in MLLM development.
PerPO: Perceptual Preference Optimization via Discriminative Rewarding
Feb 05, 2025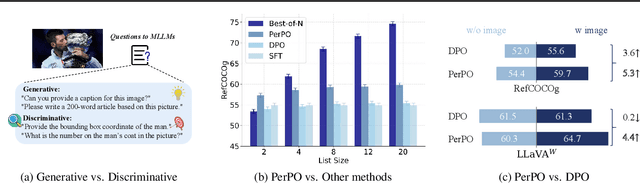
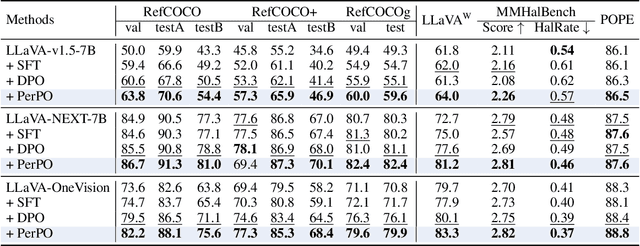
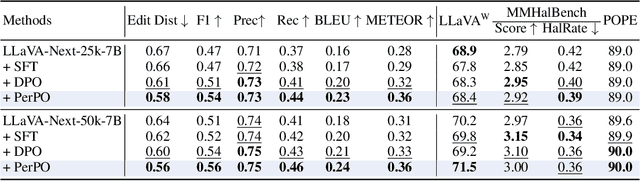
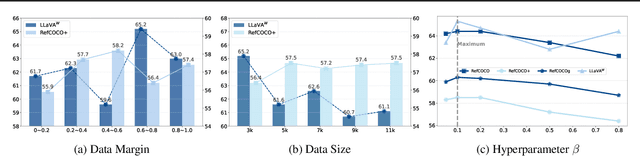
This paper presents Perceptual Preference Optimization (PerPO), a perception alignment method aimed at addressing the visual discrimination challenges in generative pre-trained multimodal large language models (MLLMs). To align MLLMs with human visual perception process, PerPO employs discriminative rewarding to gather diverse negative samples, followed by listwise preference optimization to rank them.By utilizing the reward as a quantitative margin for ranking, our method effectively bridges generative preference optimization and discriminative empirical risk minimization. PerPO significantly enhances MLLMs' visual discrimination capabilities while maintaining their generative strengths, mitigates image-unconditional reward hacking, and ensures consistent performance across visual tasks. This work marks a crucial step towards more perceptually aligned and versatile MLLMs. We also hope that PerPO will encourage the community to rethink MLLM alignment strategies.
Slow Perception: Let's Perceive Geometric Figures Step-by-step
Dec 30, 2024



Recently, "visual o1" began to enter people's vision, with expectations that this slow-thinking design can solve visual reasoning tasks, especially geometric math problems. However, the reality is that current LVLMs (Large Vision Language Models) can hardly even accurately copy a geometric figure, let alone truly understand the complex inherent logic and spatial relationships within geometric shapes. We believe accurate copying (strong perception) is the first step to visual o1. Accordingly, we introduce the concept of "slow perception" (SP), which guides the model to gradually perceive basic point-line combinations, as our humans, reconstruct complex geometric structures progressively. There are two-fold stages in SP: a) perception decomposition. Perception is not instantaneous. In this stage, complex geometric figures are broken down into basic simple units to unify geometry representation. b) perception flow, which acknowledges that accurately tracing a line is not an easy task. This stage aims to avoid "long visual jumps" in regressing line segments by using a proposed "perceptual ruler" to trace each line stroke-by-stroke. Surprisingly, such a human-like perception manner enjoys an inference time scaling law -- the slower, the better. Researchers strive to speed up the model's perception in the past, but we slow it down again, allowing the model to read the image step-by-step and carefully.
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
Sep 03, 2024
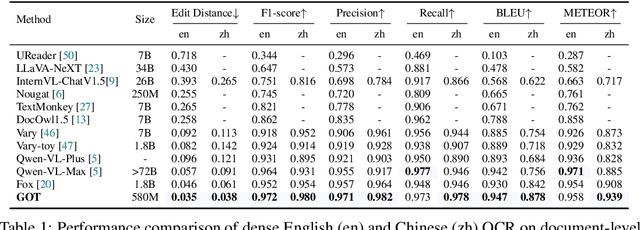

Traditional OCR systems (OCR-1.0) are increasingly unable to meet people's usage due to the growing demand for intelligent processing of man-made optical characters. In this paper, we collectively refer to all artificial optical signals (e.g., plain texts, math/molecular formulas, tables, charts, sheet music, and even geometric shapes) as "characters" and propose the General OCR Theory along with an excellent model, namely GOT, to promote the arrival of OCR-2.0. The GOT, with 580M parameters, is a unified, elegant, and end-to-end model, consisting of a high-compression encoder and a long-contexts decoder. As an OCR-2.0 model, GOT can handle all the above "characters" under various OCR tasks. On the input side, the model supports commonly used scene- and document-style images in slice and whole-page styles. On the output side, GOT can generate plain or formatted results (markdown/tikz/smiles/kern) via an easy prompt. Besides, the model enjoys interactive OCR features, i.e., region-level recognition guided by coordinates or colors. Furthermore, we also adapt dynamic resolution and multi-page OCR technologies to GOT for better practicality. In experiments, we provide sufficient results to prove the superiority of our model.