 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolter-to-Sleep: AI-Enabled Repurposing of Single-Lead ECG for Sleep Phenotyping
Mar 19, 2026Sleep disturbances are tightly linked to cardiovascular risk, yet polysomnography (PSG)-the clinical reference standard-remains resource-intensive and poorly suited for multi-night, home-based, and large-scale screening. Single-lead electrocardiography (ECG), already ubiquitous in Holter and patch-based devices, enables comfortable long-term acquisition and encodes sleep-relevant physiology through autonomic modulation and cardiorespiratory coupling. Here, we present a proof-of-concept Holter-to-Sleep framework that, using single-lead ECG as the sole input, jointly supports overnight sleep phenotyping and Holter-grade cardiac phenotyping within the same recording, and further provides an explicit analytic pathway for scalable cardio-sleep association studies. The framework is developed and validated on a pooled multi-center PSG sample of 10,439 studies spanning four public cohorts, with independent external evaluation to assess cross-cohort generalizability, and additional real-world feasibility assessment using overnight patch-ECG recordings via objective-subjective consistency analysis. This integrated design enables robust extraction of clinically meaningful overnight sleep phenotypes under heterogeneous populations and acquisition conditions, and facilitates systematic linkage between ECG-derived sleep metrics and arrhythmia-related Holter phenotypes. Collectively, the Holter-to-Sleep paradigm offers a practical foundation for low-burden, home-deployable, and scalable cardio-sleep monitoring and research beyond traditional PSG-centric workflows.
Dual-Stage Safe Herding Framework for Adversarial Attacker in Dynamic Environment
Sep 10, 2025Recent advances in robotics have enabled the widespread deployment of autonomous robotic systems in complex operational environments, presenting both unprecedented opportunities and significant security problems. Traditional shepherding approaches based on fixed formations are often ineffective or risky in urban and obstacle-rich scenarios, especially when facing adversarial agents with unknown and adaptive behaviors. This paper addresses this challenge as an extended herding problem, where defensive robotic systems must safely guide adversarial agents with unknown strategies away from protected areas and into predetermined safe regions, while maintaining collision-free navigation in dynamic environments. We propose a hierarchical hybrid framework based on reach-avoid game theory and local motion planning, incorporating a virtual containment boundary and event-triggered pursuit mechanisms to enable scalable and robust multi-agent coordination. Simulation results demonstrate that the proposed approach achieves safe and efficient guidance of adversarial agents to designated regions.
Efficient Extreme Operating Condition Search for Online Relay Setting Calculation in Renewable Power Systems Based on Parallel Graph Neural Network
Jun 24, 2025The Extreme Operating Conditions Search (EOCS) problem is one of the key problems in relay setting calculation, which is used to ensure that the setting values of protection relays can adapt to the changing operating conditions of power systems over a period of time after deployment. The high penetration of renewable energy and the wide application of inverter-based resources make the operating conditions of renewable power systems more volatile, which urges the adoption of the online relay setting calculation strategy. However, the computation speed of existing EOCS methods based on local enumeration, heuristic algorithms, and mathematical programming cannot meet the efficiency requirement of online relay setting calculation. To reduce the time overhead, this paper, for the first time, proposes an efficient deep learning-based EOCS method suitable for online relay setting calculation. First, the power system information is formulated as four layers, i.e., a component parameter layer, a topological connection layer, an electrical distance layer, and a graph distance layer, which are fed into a parallel graph neural network (PGNN) model for feature extraction. Then, the four feature layers corresponding to each node are spliced and stretched, and then fed into the decision network to predict the extreme operating condition of the system. Finally, the proposed PGNN method is validated on the modified IEEE 39-bus and 118-bus test systems, where some of the synchronous generators are replaced by renewable generation units. The nonlinear fault characteristics of renewables are fully considered when computing fault currents. The experiment results show that the proposed PGNN method achieves higher accuracy than the existing methods in solving the EOCS problem. Meanwhile, it also provides greater improvements in online computation time.
ChronoSteer: Bridging Large Language Model and Time Series Foundation Model via Synthetic Data
May 15, 2025



Conventional forecasting methods rely on unimodal time series data, limiting their ability to exploit rich textual information. Recently, large language models (LLMs) and time series foundation models (TSFMs) have demonstrated powerful capability in textual reasoning and temporal modeling, respectively. Integrating the strengths of both to construct a multimodal model that concurrently leverages both temporal and textual information for future inference has emerged as a critical research challenge. To address the scarcity of event-series paired data, we propose a decoupled framework: an LLM is employed to transform textual events into revision instructions, which are then used to steer the output of TSFM. To implement this framework, we introduce ChronoSteer, a multimodal TSFM that can be steered through textual revision instructions, effectively bridging LLM and TSFM. Moreover, to mitigate the shortage of cross-modal instruction-series paired data, we devise a two-stage training strategy based on synthetic data. In addition, we also construct a high-quality multimodal time series forecasting benchmark to address the information leakage concerns during evaluation. After integrating with an LLM, ChronoSteer, which is trained exclusively on synthetic data, achieves a 25.7% improvement in prediction accuracy compared to the unimodal backbone and a 22.5% gain over the previous state-of-the-art multimodal method.
Unlocking the Potential of Linear Networks for Irregular Multivariate Time Series Forecasting
May 01, 2025Time series forecasting holds significant importance across various industries, including finance, transportation, energy, healthcare, and climate. Despite the widespread use of linear networks due to their low computational cost and effectiveness in modeling temporal dependencies, most existing research has concentrated on regularly sampled and fully observed multivariate time series. However, in practice, we frequently encounter irregular multivariate time series characterized by variable sampling intervals and missing values. The inherent intra-series inconsistency and inter-series asynchrony in such data hinder effective modeling and forecasting with traditional linear networks relying on static weights. To tackle these challenges, this paper introduces a novel model named AiT. AiT utilizes an adaptive linear network capable of dynamically adjusting weights according to observation time points to address intra-series inconsistency, thereby enhancing the accuracy of temporal dependencies modeling. Furthermore, by incorporating the Transformer module on variable semantics embeddings, AiT efficiently captures variable correlations, avoiding the challenge of inter-series asynchrony. Comprehensive experiments across four benchmark datasets demonstrate the superiority of AiT, improving prediction accuracy by 11% and decreasing runtime by 52% compared to existing state-of-the-art methods.
Simultaneous Polysomnography and Cardiotocography Reveal Temporal Correlation Between Maternal Obstructive Sleep Apnea and Fetal Hypoxia
Apr 17, 2025Background: Obstructive sleep apnea syndrome (OSAS) during pregnancy is common and can negatively affect fetal outcomes. However, studies on the immediate effects of maternal hypoxia on fetal heart rate (FHR) changes are lacking. Methods: We used time-synchronized polysomnography (PSG) and cardiotocography (CTG) data from two cohorts to analyze the correlation between maternal hypoxia and FHR changes (accelerations or decelerations). Maternal hypoxic event characteristics were analyzed using generalized linear modeling (GLM) to assess their associations with different FHR changes. Results: A total of 118 pregnant women participated. FHR changes were significantly associated with maternal hypoxia, primarily characterized by accelerations. A longer hypoxic duration correlated with more significant FHR accelerations (P < 0.05), while prolonged hypoxia and greater SpO2 drop were linked to FHR decelerations (P < 0.05). Both cohorts showed a transient increase in FHR during maternal hypoxia, which returned to baseline after the event resolved. Conclusion: Maternal hypoxia significantly affects FHR, suggesting that maternal OSAS may contribute to fetal hypoxia. These findings highlight the importance of maternal-fetal interactions and provide insights for future interventions.
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025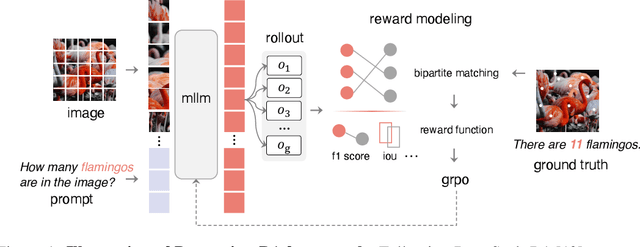
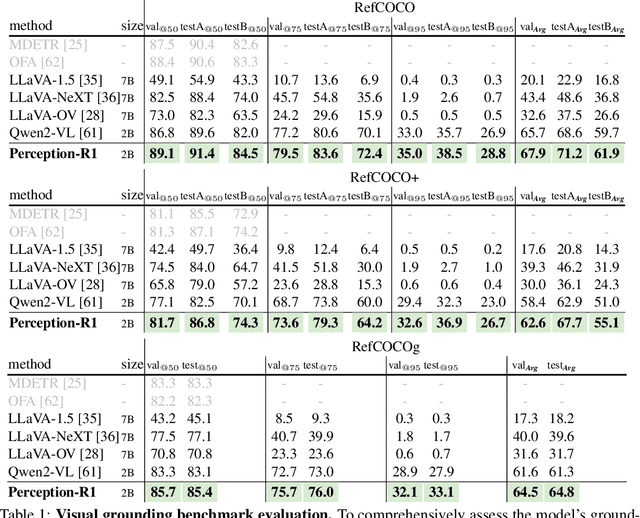
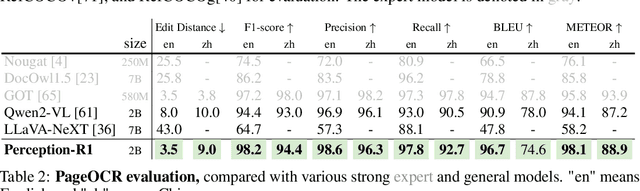
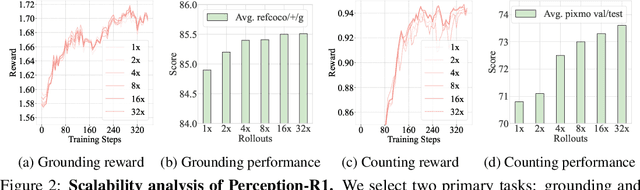
Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
MergeQuant: Accurate 4-bit Static Quantization of Large Language Models by Channel-wise Calibration
Mar 07, 2025Quantization has been widely used to compress and accelerate inference of large language models (LLMs). Existing methods focus on exploring the per-token dynamic calibration to ensure both inference acceleration and model accuracy under 4-bit quantization. However, in autoregressive generation inference of long sequences, the overhead of repeated dynamic quantization and dequantization steps becomes considerably expensive. In this work, we propose MergeQuant, an accurate and efficient per-channel static quantization framework. MergeQuant integrates the per-channel quantization steps with the corresponding scalings and linear mappings through a Quantization Step Migration (QSM) method, thereby eliminating the quantization overheads before and after matrix multiplication. Furthermore, in view of the significant differences between the different channel ranges, we propose dimensional reconstruction and adaptive clipping to address the non-uniformity of quantization scale factors and redistribute the channel variations to the subsequent modules to balance the parameter distribution under QSM. Within the static quantization setting of W4A4, MergeQuant reduces the accuracy gap on zero-shot tasks compared to FP16 baseline to 1.3 points on Llama-2-70B model. On Llama-2-7B model, MergeQuant achieves up to 1.77x speedup in decoding, and up to 2.06x speedup in end-to-end compared to FP16 baseline.
OIPR: Evaluation for Time-series Anomaly Detection Inspired by Operator Interest
Mar 03, 2025



With the growing adoption of time-series anomaly detection (TAD) technology, numerous studies have employed deep learning-based detectors for analyzing time-series data in the fields of Internet services, industrial systems, and sensors. The selection and optimization of anomaly detectors strongly rely on the availability of an effective performance evaluation method for TAD. Since anomalies in time-series data often manifest as a sequence of points, conventional metrics that solely consider the detection of individual point are inadequate. Existing evaluation methods for TAD typically employ point-based or event-based metrics to capture the temporal context. However, point-based metrics tend to overestimate detectors that excel only in detecting long anomalies, while event-based metrics are susceptible to being misled by fragmented detection results. To address these limitations, we propose OIPR, a novel set of TAD evaluation metrics. It models the process of operators receiving detector alarms and handling faults, utilizing area under the operator interest curve to evaluate the performance of TAD algorithms. Furthermore, we build a special scenario dataset to compare the characteristics of different evaluation methods. Through experiments conducted on the special scenario dataset and five real-world datasets, we demonstrate the remarkable performance of OIPR in extreme and complex scenarios. It achieves a balance between point and event perspectives, overcoming their primary limitations and offering applicability to broader situations.
Erasing Without Remembering: Safeguarding Knowledge Forgetting in Large Language Models
Feb 27, 2025



In this paper, we explore machine unlearning from a novel dimension, by studying how to safeguard model unlearning in large language models (LLMs). Our goal is to prevent unlearned models from recalling any related memory of the targeted knowledge.We begin by uncovering a surprisingly simple yet overlooked fact: existing methods typically erase only the exact expressions of the targeted knowledge, leaving paraphrased or related information intact. To rigorously measure such oversights, we introduce UGBench, the first benchmark tailored for evaluating the generalisation performance across 13 state-of-the-art methods.UGBench reveals that unlearned models can still recall paraphrased answers and retain target facts in intermediate layers. To address this, we propose PERMU, a perturbation-based method that significantly enhances the generalisation capabilities for safeguarding LLM unlearning.Experiments demonstrate that PERMU delivers up to a 50.13% improvement in unlearning while maintaining a 43.53% boost in robust generalisation. Our code can be found in https://github.com/MaybeLizzy/UGBench.