 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP-Shapley: Feature-based Modeling for Evaluating the Most Valuable Player in Basketball
Jun 05, 2025The burgeoning growth of the esports and multiplayer online gaming community has highlighted the critical importance of evaluating the Most Valuable Player (MVP). The establishment of an explainable and practical MVP evaluation method is very challenging. In our study, we specifically focus on play-by-play data, which records related events during the game, such as assists and points. We aim to address the challenges by introducing a new MVP evaluation framework, denoted as \oursys, which leverages Shapley values. This approach encompasses feature processing, win-loss model training, Shapley value allocation, and MVP ranking determination based on players' contributions. Additionally, we optimize our algorithm to align with expert voting results from the perspective of causality. Finally, we substantiated the efficacy of our method through validation using the NBA dataset and the Dunk City Dynasty dataset and implemented online deployment in the industry.
Fast-DataShapley: Neural Modeling for Training Data Valuation
Jun 05, 2025The value and copyright of training data are crucial in the artificial intelligence industry. Service platforms should protect data providers' legitimate rights and fairly reward them for their contributions. Shapley value, a potent tool for evaluating contributions, outperforms other methods in theory, but its computational overhead escalates exponentially with the number of data providers. Recent works based on Shapley values attempt to mitigate computation complexity by approximation algorithms. However, they need to retrain for each test sample, leading to intolerable costs. We propose Fast-DataShapley, a one-pass training method that leverages the weighted least squares characterization of the Shapley value to train a reusable explainer model with real-time reasoning speed. Given new test samples, no retraining is required to calculate the Shapley values of the training data. Additionally, we propose three methods with theoretical guarantees to reduce training overhead from two aspects: the approximate calculation of the utility function and the group calculation of the training data. We analyze time complexity to show the efficiency of our methods. The experimental evaluations on various image datasets demonstrate superior performance and efficiency compared to baselines. Specifically, the performance is improved to more than 2.5 times, and the explainer's training speed can be increased by two orders of magnitude.
Unlocking the Potential of Linear Networks for Irregular Multivariate Time Series Forecasting
May 01, 2025Time series forecasting holds significant importance across various industries, including finance, transportation, energy, healthcare, and climate. Despite the widespread use of linear networks due to their low computational cost and effectiveness in modeling temporal dependencies, most existing research has concentrated on regularly sampled and fully observed multivariate time series. However, in practice, we frequently encounter irregular multivariate time series characterized by variable sampling intervals and missing values. The inherent intra-series inconsistency and inter-series asynchrony in such data hinder effective modeling and forecasting with traditional linear networks relying on static weights. To tackle these challenges, this paper introduces a novel model named AiT. AiT utilizes an adaptive linear network capable of dynamically adjusting weights according to observation time points to address intra-series inconsistency, thereby enhancing the accuracy of temporal dependencies modeling. Furthermore, by incorporating the Transformer module on variable semantics embeddings, AiT efficiently captures variable correlations, avoiding the challenge of inter-series asynchrony. Comprehensive experiments across four benchmark datasets demonstrate the superiority of AiT, improving prediction accuracy by 11% and decreasing runtime by 52% compared to existing state-of-the-art methods.
MergeQuant: Accurate 4-bit Static Quantization of Large Language Models by Channel-wise Calibration
Mar 07, 2025Quantization has been widely used to compress and accelerate inference of large language models (LLMs). Existing methods focus on exploring the per-token dynamic calibration to ensure both inference acceleration and model accuracy under 4-bit quantization. However, in autoregressive generation inference of long sequences, the overhead of repeated dynamic quantization and dequantization steps becomes considerably expensive. In this work, we propose MergeQuant, an accurate and efficient per-channel static quantization framework. MergeQuant integrates the per-channel quantization steps with the corresponding scalings and linear mappings through a Quantization Step Migration (QSM) method, thereby eliminating the quantization overheads before and after matrix multiplication. Furthermore, in view of the significant differences between the different channel ranges, we propose dimensional reconstruction and adaptive clipping to address the non-uniformity of quantization scale factors and redistribute the channel variations to the subsequent modules to balance the parameter distribution under QSM. Within the static quantization setting of W4A4, MergeQuant reduces the accuracy gap on zero-shot tasks compared to FP16 baseline to 1.3 points on Llama-2-70B model. On Llama-2-7B model, MergeQuant achieves up to 1.77x speedup in decoding, and up to 2.06x speedup in end-to-end compared to FP16 baseline.
OIPR: Evaluation for Time-series Anomaly Detection Inspired by Operator Interest
Mar 03, 2025



With the growing adoption of time-series anomaly detection (TAD) technology, numerous studies have employed deep learning-based detectors for analyzing time-series data in the fields of Internet services, industrial systems, and sensors. The selection and optimization of anomaly detectors strongly rely on the availability of an effective performance evaluation method for TAD. Since anomalies in time-series data often manifest as a sequence of points, conventional metrics that solely consider the detection of individual point are inadequate. Existing evaluation methods for TAD typically employ point-based or event-based metrics to capture the temporal context. However, point-based metrics tend to overestimate detectors that excel only in detecting long anomalies, while event-based metrics are susceptible to being misled by fragmented detection results. To address these limitations, we propose OIPR, a novel set of TAD evaluation metrics. It models the process of operators receiving detector alarms and handling faults, utilizing area under the operator interest curve to evaluate the performance of TAD algorithms. Furthermore, we build a special scenario dataset to compare the characteristics of different evaluation methods. Through experiments conducted on the special scenario dataset and five real-world datasets, we demonstrate the remarkable performance of OIPR in extreme and complex scenarios. It achieves a balance between point and event perspectives, overcoming their primary limitations and offering applicability to broader situations.
Erasing Without Remembering: Safeguarding Knowledge Forgetting in Large Language Models
Feb 27, 2025



In this paper, we explore machine unlearning from a novel dimension, by studying how to safeguard model unlearning in large language models (LLMs). Our goal is to prevent unlearned models from recalling any related memory of the targeted knowledge.We begin by uncovering a surprisingly simple yet overlooked fact: existing methods typically erase only the exact expressions of the targeted knowledge, leaving paraphrased or related information intact. To rigorously measure such oversights, we introduce UGBench, the first benchmark tailored for evaluating the generalisation performance across 13 state-of-the-art methods.UGBench reveals that unlearned models can still recall paraphrased answers and retain target facts in intermediate layers. To address this, we propose PERMU, a perturbation-based method that significantly enhances the generalisation capabilities for safeguarding LLM unlearning.Experiments demonstrate that PERMU delivers up to a 50.13% improvement in unlearning while maintaining a 43.53% boost in robust generalisation. Our code can be found in https://github.com/MaybeLizzy/UGBench.
Diversified Augmentation with Domain Adaptation for Debiased Video Temporal Grounding
Jan 14, 2025



Temporal sentence grounding in videos (TSGV) faces challenges due to public TSGV datasets containing significant temporal biases, which are attributed to the uneven temporal distributions of target moments. Existing methods generate augmented videos, where target moments are forced to have varying temporal locations. However, since the video lengths of the given datasets have small variations, only changing the temporal locations results in poor generalization ability in videos with varying lengths. In this paper, we propose a novel training framework complemented by diversified data augmentation and a domain discriminator. The data augmentation generates videos with various lengths and target moment locations to diversify temporal distributions. However, augmented videos inevitably exhibit distinct feature distributions which may introduce noise. To address this, we design a domain adaptation auxiliary task to diminish feature discrepancies between original and augmented videos. We also encourage the model to produce distinct predictions for videos with the same text queries but different moment locations to promote debiased training. Experiments on Charades-CD and ActivityNet-CD datasets demonstrate the effectiveness and generalization abilities of our method in multiple grounding structures, achieving state-of-the-art results.
ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
Dec 16, 2024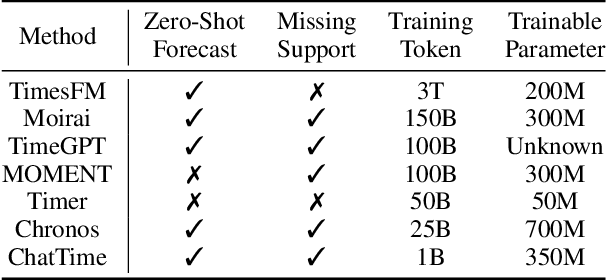
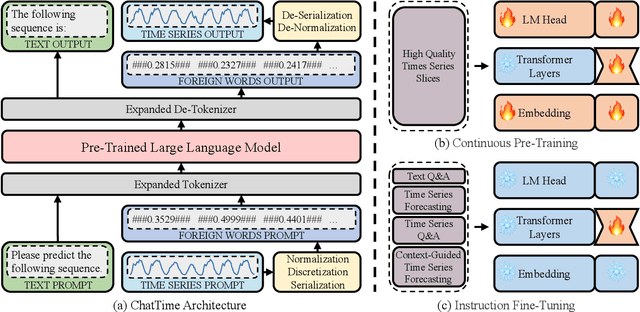

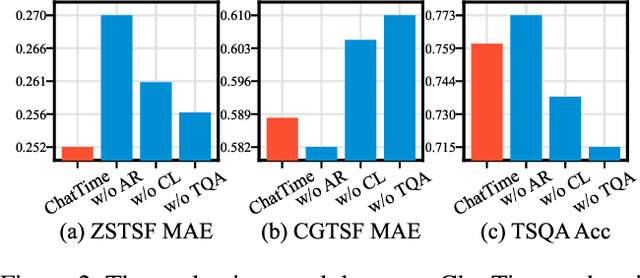
Human experts typically integrate numerical and textual multimodal information to analyze time series. However, most traditional deep learning predictors rely solely on unimodal numerical data, using a fixed-length window for training and prediction on a single dataset, and cannot adapt to different scenarios. The powered pre-trained large language model has introduced new opportunities for time series analysis. Yet, existing methods are either inefficient in training, incapable of handling textual information, or lack zero-shot forecasting capability. In this paper, we innovatively model time series as a foreign language and construct ChatTime, a unified framework for time series and text processing. As an out-of-the-box multimodal time series foundation model, ChatTime provides zero-shot forecasting capability and supports bimodal input/output for both time series and text. We design a series of experiments to verify the superior performance of ChatTime across multiple tasks and scenarios, and create four multimodal datasets to address data gaps. The experimental results demonstrate the potential and utility of ChatTime.
DeepCore: Simple Fingerprint Construction for Differentiating Homologous and Piracy Models
Nov 01, 2024
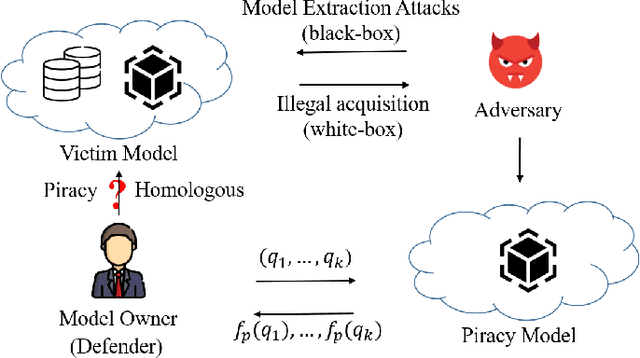

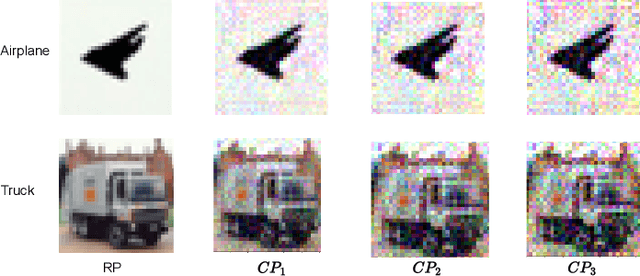
As intellectual property rights, the copyright protection of deep models is becoming increasingly important. Existing work has made many attempts at model watermarking and fingerprinting, but they have ignored homologous models trained with similar structures or training datasets. We highlight challenges in efficiently querying black-box piracy models to protect model copyrights without misidentifying homologous models. To address these challenges, we propose a novel method called DeepCore, which discovers that the classification confidence of the model is positively correlated with the distance of the predicted sample from the model decision boundary and piracy models behave more similarly at high-confidence classified sample points. Then DeepCore constructs core points far away from the decision boundary by optimizing the predicted confidence of a few sample points and leverages behavioral discrepancies between piracy and homologous models to identify piracy models. Finally, we design different model identification methods, including two similarity-based methods and a clustering-based method to identify piracy models using models' predictions of core points. Extensive experiments show the effectiveness of DeepCore in identifying various piracy models, achieving lower missed and false identification rates, and outperforming state-of-the-art methods.
Interdependency Matters: Graph Alignment for Multivariate Time Series Anomaly Detection
Oct 11, 2024


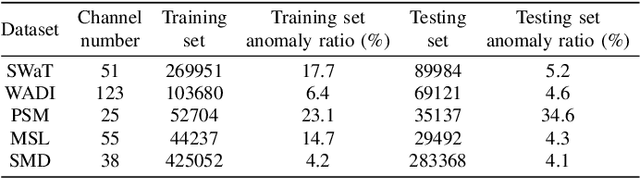
Anomaly detection in multivariate time series (MTS) is crucial for various applications in data mining and industry. Current industrial methods typically approach anomaly detection as an unsupervised learning task, aiming to identify deviations by estimating the normal distribution in noisy, label-free datasets. These methods increasingly incorporate interdependencies between channels through graph structures to enhance accuracy. However, the role of interdependencies is more critical than previously understood, as shifts in interdependencies between MTS channels from normal to anomalous data are significant. This observation suggests that \textit{anomalies could be detected by changes in these interdependency graph series}. To capitalize on this insight, we introduce MADGA (MTS Anomaly Detection via Graph Alignment), which redefines anomaly detection as a graph alignment (GA) problem that explicitly utilizes interdependencies for anomaly detection. MADGA dynamically transforms subsequences into graphs to capture the evolving interdependencies, and Graph alignment is performed between these graphs, optimizing an alignment plan that minimizes cost, effectively minimizing the distance for normal data and maximizing it for anomalous data. Uniquely, our GA approach involves explicit alignment of both nodes and edges, employing Wasserstein distance for nodes and Gromov-Wasserstein distance for edges. To our knowledge, this is the first application of GA to MTS anomaly detection that explicitly leverages interdependency for this purpose. Extensive experiments on diverse real-world datasets validate the effectiveness of MADGA, demonstrating its capability to detect anomalies and differentiate interdependencies, consistently achieving state-of-the-art across various scenarios.