 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineFT: Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading
Dec 29, 2025Futures are contracts obligating the exchange of an asset at a predetermined date and price, notable for their high leverage and liquidity and, therefore, thrive in the Crypto market. RL has been widely applied in various quantitative tasks. However, most methods focus on the spot and could not be directly applied to the futures market with high leverage because of 2 challenges. First, high leverage amplifies reward fluctuations, making training stochastic and difficult to converge. Second, prior works lacked self-awareness of capability boundaries, exposing them to the risk of significant loss when encountering new market state (e.g.,a black swan event like COVID-19). To tackle these challenges, we propose the Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading (FineFT), a novel three-stage ensemble RL framework with stable training and proper risk management. In stage I, ensemble Q learners are selectively updated by ensemble TD errors to improve convergence. In stage II, we filter the Q-learners based on their profitabilities and train VAEs on market states to identify the capability boundaries of the learners. In stage III, we choose from the filtered ensemble and a conservative policy, guided by trained VAEs, to maintain profitability and mitigate risk with new market states. Through extensive experiments on crypto futures in a high-frequency trading environment with high fidelity and 5x leverage, we demonstrate that FineFT outperforms 12 SOTA baselines in 6 financial metrics, reducing risk by more than 40% while achieving superior profitability compared to the runner-up. Visualization of the selective update mechanism shows that different agents specialize in distinct market dynamics, and ablation studies certify routing with VAEs reduces maximum drawdown effectively, and selective update improves convergence and performance.
Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback
Jul 28, 2025



Multimodal Large Language Models (MLLMs) have exhibited impressive performance across various visual tasks. Subsequent investigations into enhancing their visual reasoning abilities have significantly expanded their performance envelope. However, a critical bottleneck in the advancement of MLLMs toward deep visual reasoning is their heavy reliance on curated image-text supervision. To solve this problem, we introduce a novel framework termed ``Reasoning-Rendering-Visual-Feedback'' (RRVF), which enables MLLMs to learn complex visual reasoning from only raw images. This framework builds on the ``Asymmetry of Verification'' principle to train MLLMs, i.e., verifying the rendered output against a source image is easier than generating it. We demonstrate that this relative ease provides an ideal reward signal for optimization via Reinforcement Learning (RL) training, reducing the reliance on the image-text supervision. Guided by the above principle, RRVF implements a closed-loop iterative process encompassing reasoning, rendering, and visual feedback components, enabling the model to perform self-correction through multi-turn interactions and tool invocation, while this pipeline can be optimized by the GRPO algorithm in an end-to-end manner. Extensive experiments on image-to-code generation for data charts and web interfaces show that RRVF substantially outperforms existing open-source MLLMs and surpasses supervised fine-tuning baselines. Our findings demonstrate that systems driven by purely visual feedback present a viable path toward more robust and generalizable reasoning models without requiring explicit supervision. Code will be available at https://github.com/L-O-I/RRVF.
Fast-DataShapley: Neural Modeling for Training Data Valuation
Jun 05, 2025The value and copyright of training data are crucial in the artificial intelligence industry. Service platforms should protect data providers' legitimate rights and fairly reward them for their contributions. Shapley value, a potent tool for evaluating contributions, outperforms other methods in theory, but its computational overhead escalates exponentially with the number of data providers. Recent works based on Shapley values attempt to mitigate computation complexity by approximation algorithms. However, they need to retrain for each test sample, leading to intolerable costs. We propose Fast-DataShapley, a one-pass training method that leverages the weighted least squares characterization of the Shapley value to train a reusable explainer model with real-time reasoning speed. Given new test samples, no retraining is required to calculate the Shapley values of the training data. Additionally, we propose three methods with theoretical guarantees to reduce training overhead from two aspects: the approximate calculation of the utility function and the group calculation of the training data. We analyze time complexity to show the efficiency of our methods. The experimental evaluations on various image datasets demonstrate superior performance and efficiency compared to baselines. Specifically, the performance is improved to more than 2.5 times, and the explainer's training speed can be increased by two orders of magnitude.
GDI-Bench: A Benchmark for General Document Intelligence with Vision and Reasoning Decoupling
Apr 30, 2025The rapid advancement of multimodal large language models (MLLMs) has profoundly impacted the document domain, creating a wide array of application scenarios. This progress highlights the need for a comprehensive benchmark to evaluate these models' capabilities across various document-specific tasks. However, existing benchmarks often fail to locate specific model weaknesses or guide systematic improvements. To bridge this gap, we introduce a General Document Intelligence Benchmark (GDI-Bench), featuring 1.9k images across 9 key scenarios and 19 document-specific tasks. By decoupling visual complexity and reasoning complexity, the GDI-Bench structures graded tasks that allow performance assessment by difficulty, aiding in model weakness identification and optimization guidance. We evaluate the GDI-Bench on various open-source and closed-source models, conducting decoupled analyses in the visual and reasoning domains. For instance, the GPT-4o model excels in reasoning tasks but exhibits limitations in visual capabilities. To address the diverse tasks and domains in the GDI-Bench, we propose a GDI Model that mitigates the issue of catastrophic forgetting during the supervised fine-tuning (SFT) process through a intelligence-preserving training strategy. Our model achieves state-of-the-art performance on previous benchmarks and the GDI-Bench. Both our benchmark and model will be open source.
GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Dec 16, 2024



Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
Continuously Learning, Adapting, and Improving: A Dual-Process Approach to Autonomous Driving
May 24, 2024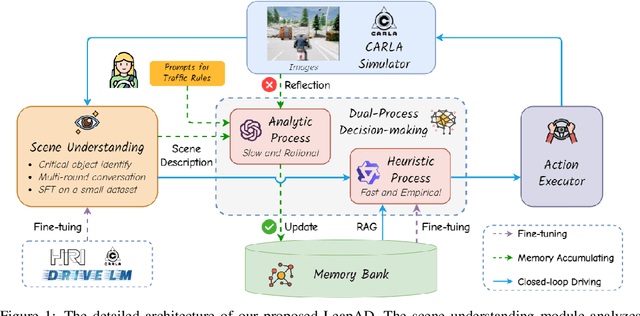
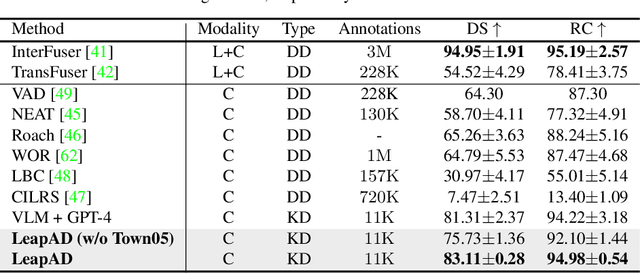
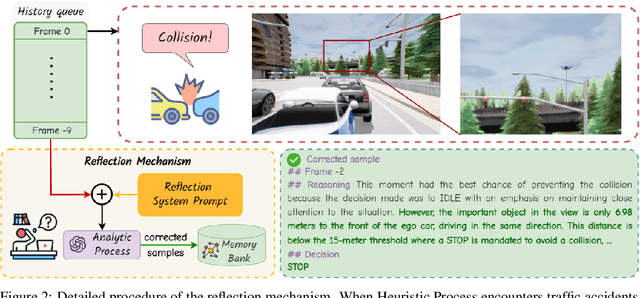
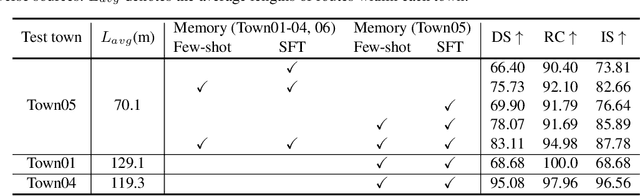
Autonomous driving has advanced significantly due to sensors, machine learning, and artificial intelligence improvements. However, prevailing methods struggle with intricate scenarios and causal relationships, hindering adaptability and interpretability in varied environments. To address the above problems, we introduce LeapAD, a novel paradigm for autonomous driving inspired by the human cognitive process. Specifically, LeapAD emulates human attention by selecting critical objects relevant to driving decisions, simplifying environmental interpretation, and mitigating decision-making complexities. Additionally, LeapAD incorporates an innovative dual-process decision-making module, which consists of an Analytic Process (System-II) for thorough analysis and reasoning, along with a Heuristic Process (System-I) for swift and empirical processing. The Analytic Process leverages its logical reasoning to accumulate linguistic driving experience, which is then transferred to the Heuristic Process by supervised fine-tuning. Through reflection mechanisms and a growing memory bank, LeapAD continuously improves itself from past mistakes in a closed-loop environment. Closed-loop testing in CARLA shows that LeapAD outperforms all methods relying solely on camera input, requiring 1-2 orders of magnitude less labeled data. Experiments also demonstrate that as the memory bank expands, the Heuristic Process with only 1.8B parameters can inherit the knowledge from a GPT-4 powered Analytic Process and achieve continuous performance improvement. Code will be released at https://github.com/PJLab-ADG/LeapAD.
A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
Feb 29, 2024



Financial trading is a crucial component of the markets, informed by a multimodal information landscape encompassing news, prices, and Kline charts, and encompasses diverse tasks such as quantitative trading and high-frequency trading with various assets. While advanced AI techniques like deep learning and reinforcement learning are extensively utilized in finance, their application in financial trading tasks often faces challenges due to inadequate handling of multimodal data and limited generalizability across various tasks. To address these challenges, we present FinAgent, a multimodal foundational agent with tool augmentation for financial trading. FinAgent's market intelligence module processes a diverse range of data-numerical, textual, and visual-to accurately analyze the financial market. Its unique dual-level reflection module not only enables rapid adaptation to market dynamics but also incorporates a diversified memory retrieval system, enhancing the agent's ability to learn from historical data and improve decision-making processes. The agent's emphasis on reasoning for actions fosters trust in its financial decisions. Moreover, FinAgent integrates established trading strategies and expert insights, ensuring that its trading approaches are both data-driven and rooted in sound financial principles. With comprehensive experiments on 6 financial datasets, including stocks and Crypto, FinAgent significantly outperforms 9 state-of-the-art baselines in terms of 6 financial metrics with over 36% average improvement on profit. Specifically, a 92.27% return (a 84.39% relative improvement) is achieved on one dataset. Notably, FinAgent is the first advanced multimodal foundation agent designed for financial trading tasks.
OASim: an Open and Adaptive Simulator based on Neural Rendering for Autonomous Driving
Feb 06, 2024With deep learning and computer vision technology development, autonomous driving provides new solutions to improve traffic safety and efficiency. The importance of building high-quality datasets is self-evident, especially with the rise of end-to-end autonomous driving algorithms in recent years. Data plays a core role in the algorithm closed-loop system. However, collecting real-world data is expensive, time-consuming, and unsafe. With the development of implicit rendering technology and in-depth research on using generative models to produce data at scale, we propose OASim, an open and adaptive simulator and autonomous driving data generator based on implicit neural rendering. It has the following characteristics: (1) High-quality scene reconstruction through neural implicit surface reconstruction technology. (2) Trajectory editing of the ego vehicle and participating vehicles. (3) Rich vehicle model library that can be freely selected and inserted into the scene. (4) Rich sensors model library where you can select specified sensors to generate data. (5) A highly customizable data generation system can generate data according to user needs. We demonstrate the high quality and fidelity of the generated data through perception performance evaluation on the Carla simulator and real-world data acquisition. Code is available at https://github.com/PJLab-ADG/OASim.
Realistic Rainy Weather Simulation for LiDARs in CARLA Simulator
Dec 20, 2023



Employing data augmentation methods to enhance perception performance in adverse weather has attracted considerable attention recently. Most of the LiDAR augmentation methods post-process the existing dataset by physics-based models or machine-learning methods. However, due to the limited environmental annotations and the fixed vehicle trajectories in the existing dataset, it is challenging to edit the scene and expand the diversity of traffic flow and scenario. To this end, we propose a simulator-based physical modeling approach to augment LiDAR data in rainy weather in order to improve the perception performance of LiDAR in this scenario. We complete the modeling task of the rainy weather in the CARLA simulator and establish a pipeline for LiDAR data collection. In particular, we pay special attention to the spray and splash rolled up by the wheels of surrounding vehicles in rain and complete the simulation of this special scenario through the Spray Emitter method we developed. In addition, we examine the influence of different weather conditions on the intensity of the LiDAR echo, develop a prediction network for the intensity of the LiDAR echo, and complete the simulation of 4-feat LiDAR point cloud data. In the experiment, we observe that the model augmented by the synthetic data improves the object detection task's performance in the rainy sequence of the Waymo Open Dataset. Both the code and the dataset will be made publicly available at https://github.com/PJLab-ADG/PCSim#rainypcsim.
Towards Knowledge-driven Autonomous Driving
Dec 12, 2023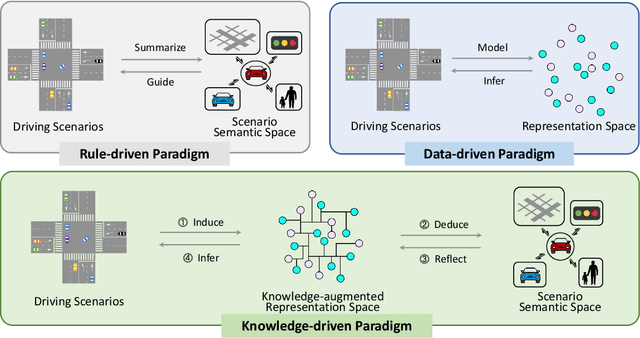
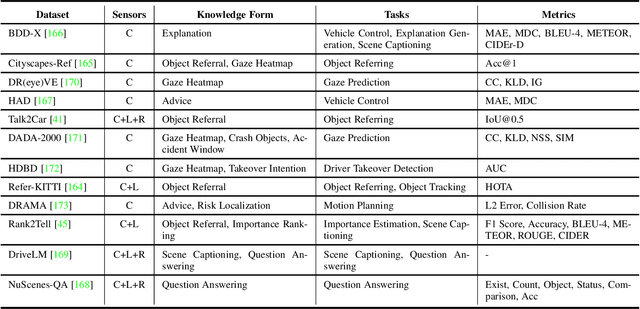
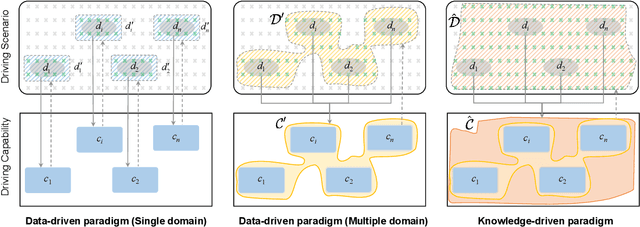
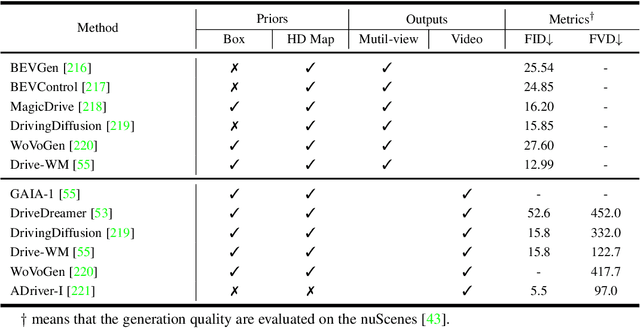
This paper explores the emerging knowledge-driven autonomous driving technologies. Our investigation highlights the limitations of current autonomous driving systems, in particular their sensitivity to data bias, difficulty in handling long-tail scenarios, and lack of interpretability. Conversely, knowledge-driven methods with the abilities of cognition, generalization and life-long learning emerge as a promising way to overcome these challenges. This paper delves into the essence of knowledge-driven autonomous driving and examines its core components: dataset \& benchmark, environment, and driver agent. By leveraging large language models, world models, neural rendering, and other advanced artificial intelligence techniques, these components collectively contribute to a more holistic, adaptive, and intelligent autonomous driving system. The paper systematically organizes and reviews previous research efforts in this area, and provides insights and guidance for future research and practical applications of autonomous driving. We will continually share the latest updates on cutting-edge developments in knowledge-driven autonomous driving along with the relevant valuable open-source resources at: \url{https://github.com/PJLab-ADG/awesome-knowledge-driven-AD}.