 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLVE: Synergy of Language-Vision and End-to-End Networks for Autonomous Driving
May 22, 2025The integration of Vision-Language Models (VLMs) into autonomous driving systems has shown promise in addressing key challenges such as learning complexity, interpretability, and common-sense reasoning. However, existing approaches often struggle with efficient integration and realtime decision-making due to computational demands. In this paper, we introduce SOLVE, an innovative framework that synergizes VLMs with end-to-end (E2E) models to enhance autonomous vehicle planning. Our approach emphasizes knowledge sharing at the feature level through a shared visual encoder, enabling comprehensive interaction between VLM and E2E components. We propose a Trajectory Chain-of-Thought (T-CoT) paradigm, which progressively refines trajectory predictions, reducing uncertainty and improving accuracy. By employing a temporal decoupling strategy, SOLVE achieves efficient cooperation by aligning high-quality VLM outputs with E2E real-time performance. Evaluated on the nuScenes dataset, our method demonstrates significant improvements in trajectory prediction accuracy, paving the way for more robust and reliable autonomous driving systems.
Large Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025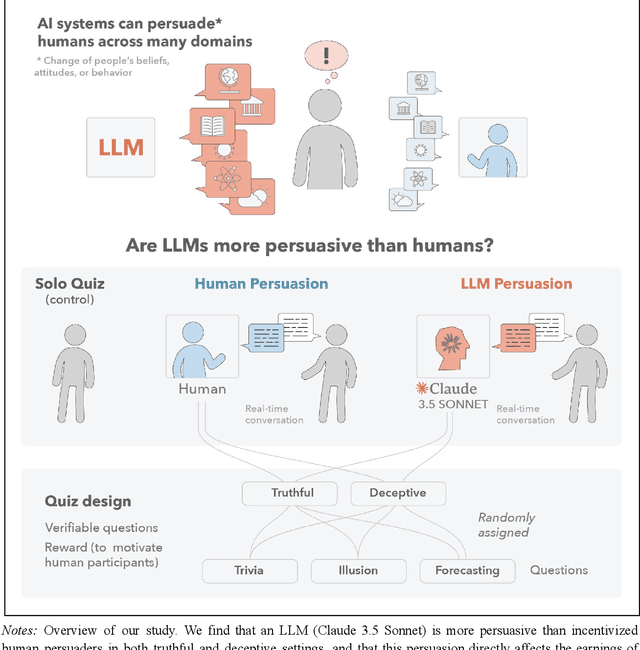
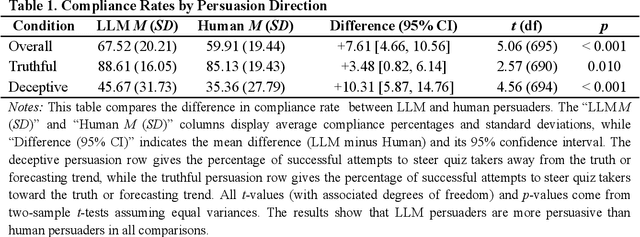
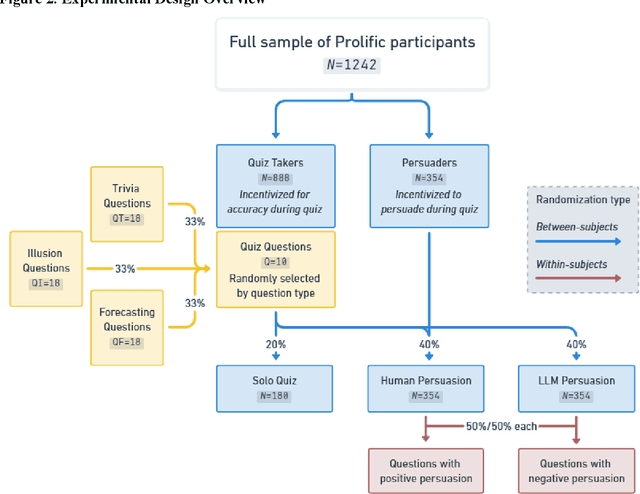
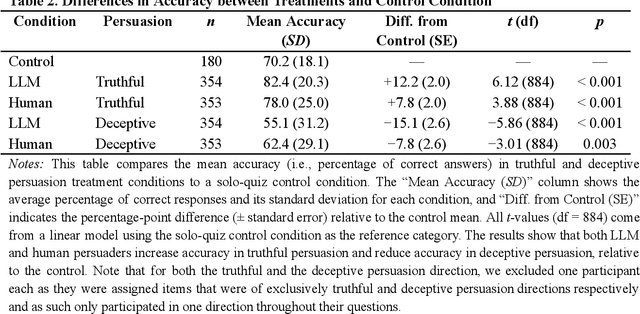
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
ZOPP: A Framework of Zero-shot Offboard Panoptic Perception for Autonomous Driving
Nov 08, 2024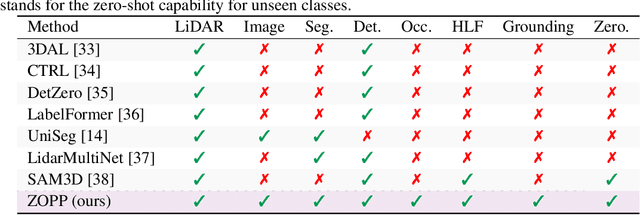
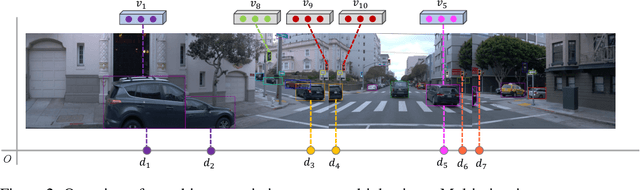


Offboard perception aims to automatically generate high-quality 3D labels for autonomous driving (AD) scenes. Existing offboard methods focus on 3D object detection with closed-set taxonomy and fail to match human-level recognition capability on the rapidly evolving perception tasks. Due to heavy reliance on human labels and the prevalence of data imbalance and sparsity, a unified framework for offboard auto-labeling various elements in AD scenes that meets the distinct needs of perception tasks is not being fully explored. In this paper, we propose a novel multi-modal Zero-shot Offboard Panoptic Perception (ZOPP) framework for autonomous driving scenes. ZOPP integrates the powerful zero-shot recognition capabilities of vision foundation models and 3D representations derived from point clouds. To the best of our knowledge, ZOPP represents a pioneering effort in the domain of multi-modal panoptic perception and auto labeling for autonomous driving scenes. We conduct comprehensive empirical studies and evaluations on Waymo open dataset to validate the proposed ZOPP on various perception tasks. To further explore the usability and extensibility of our proposed ZOPP, we also conduct experiments in downstream applications. The results further demonstrate the great potential of our ZOPP for real-world scenarios.
To Switch or Not to Switch? Balanced Policy Switching in Offline Reinforcement Learning
Jul 01, 2024Reinforcement learning (RL) -- finding the optimal behaviour (also referred to as policy) maximizing the collected long-term cumulative reward -- is among the most influential approaches in machine learning with a large number of successful applications. In several decision problems, however, one faces the possibility of policy switching -- changing from the current policy to a new one -- which incurs a non-negligible cost (examples include the shifting of the currently applied educational technology, modernization of a computing cluster, and the introduction of a new webpage design), and in the decision one is limited to using historical data without the availability for further online interaction. Despite the inevitable importance of this offline learning scenario, to our best knowledge, very little effort has been made to tackle the key problem of balancing between the gain and the cost of switching in a flexible and principled way. Leveraging ideas from the area of optimal transport, we initialize the systematic study of policy switching in offline RL. We establish fundamental properties and design a Net Actor-Critic algorithm for the proposed novel switching formulation. Numerical experiments demonstrate the efficiency of our approach on multiple benchmarks of the Gymnasium.
Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG
Jun 17, 2024

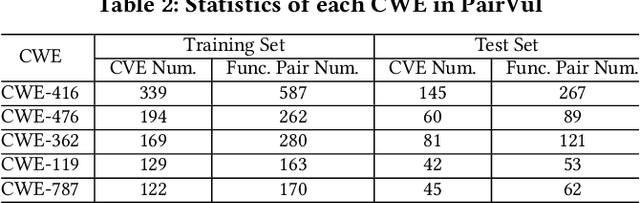
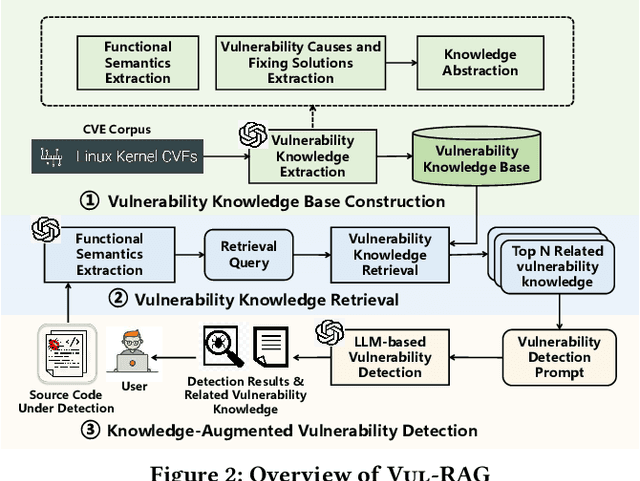
Vulnerability detection is essential for software quality assurance. In recent years, deep learning models (especially large language models) have shown promise in vulnerability detection. In this work, we propose a novel LLM-based vulnerability detection technique Vul-RAG, which leverages knowledge-level retrieval-augmented generation (RAG) framework to detect vulnerability for the given code in three phases. First, Vul-RAG constructs a vulnerability knowledge base by extracting multi-dimension knowledge via LLMs from existing CVE instances; second, for a given code snippet, Vul-RAG} retrieves the relevant vulnerability knowledge from the constructed knowledge base based on functional semantics; third, Vul-RAG leverages LLMs to check the vulnerability of the given code snippet by reasoning the presence of vulnerability causes and fixing solutions of the retrieved vulnerability knowledge. Our evaluation of Vul-RAG on our constructed benchmark PairVul shows that Vul-RAG substantially outperforms all baselines by 12.96\%/110\% relative improvement in accuracy/pairwise-accuracy. In addition, our user study shows that the vulnerability knowledge generated by Vul-RAG can serve as high-quality explanations which can improve the manual detection accuracy from 0.60 to 0.77.
Asphalt Concrete Characterization Using Digital Image Correlation: A Systematic Review of Best Practices, Applications, and Future Vision
Feb 26, 2024



Digital Image Correlation (DIC) is an optical technique that measures displacement and strain by tracking pattern movement in a sequence of captured images during testing. DIC has gained recognition in asphalt pavement engineering since the early 2000s. However, users often perceive the DIC technique as an out-of-box tool and lack a thorough understanding of its operational and measurement principles. This article presents a state-of-art review of DIC as a crucial tool for laboratory testing of asphalt concrete (AC), primarily focusing on the widely utilized 2D-DIC and 3D-DIC techniques. To address frequently asked questions from users, the review thoroughly examines the optimal methods for preparing speckle patterns, configuring single-camera or dual-camera imaging systems, conducting DIC analyses, and exploring various applications. Furthermore, emerging DIC methodologies such as Digital Volume Correlation and deep-learning-based DIC are introduced, highlighting their potential for future applications in pavement engineering. The article also provides a comprehensive and reliable flowchart for implementing DIC in AC characterization. Finally, critical directions for future research are presented.
Real-Time Asphalt Pavement Layer Thickness Prediction Using Ground-Penetrating Radar Based on a Modified Extended Common Mid-Point (XCMP) Approach
Jan 07, 2024
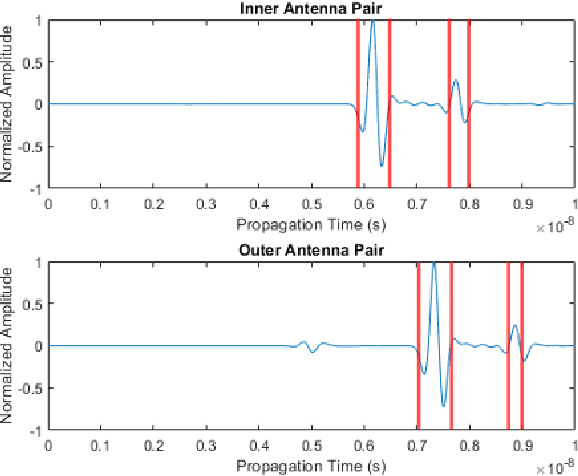


The conventional surface reflection method has been widely used to measure the asphalt pavement layer dielectric constant using ground-penetrating radar (GPR). This method may be inaccurate for in-service pavement thickness estimation with dielectric constant variation through the depth, which could be addressed using the extended common mid-point method (XCMP) with air-coupled GPR antennas. However, the factors affecting the XCMP method on thickness prediction accuracy haven't been studied. Manual acquisition of key factors is required, which hinders its real-time applications. This study investigates the affecting factors and develops a modified XCMP method to allow automatic thickness prediction of in-service asphalt pavement with non-uniform dielectric properties through depth. A sensitivity analysis was performed, necessitating the accurate estimation of time of flights (TOFs) from antenna pairs. A modified XCMP method based on edge detection was proposed to allow real-time TOFs estimation, then dielectric constant and thickness predictions. Field tests using a multi-channel GPR system were performed for validation. Both the surface reflection and XCMP setups were conducted. Results show that the modified XCMP method is recommended with a mean prediction error of 1.86%, which is more accurate than the surface reflection method (5.73%).
Towards Knowledge-driven Autonomous Driving
Dec 12, 2023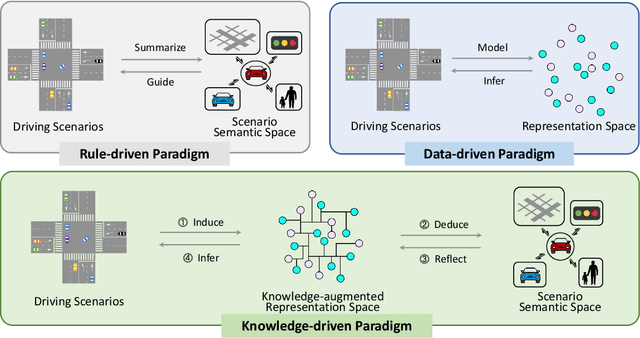
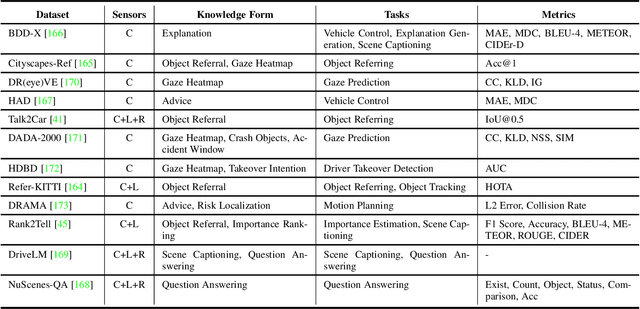
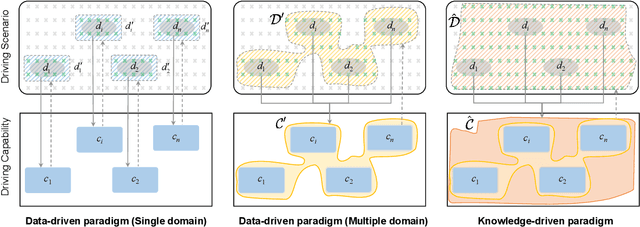
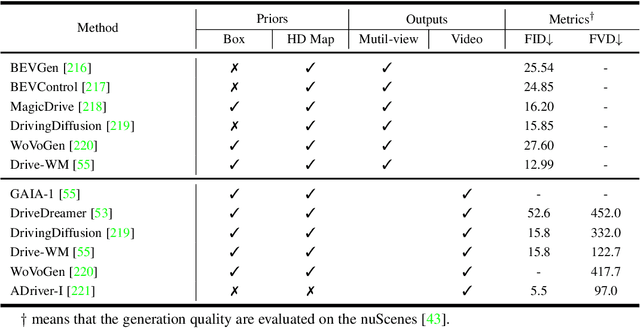
This paper explores the emerging knowledge-driven autonomous driving technologies. Our investigation highlights the limitations of current autonomous driving systems, in particular their sensitivity to data bias, difficulty in handling long-tail scenarios, and lack of interpretability. Conversely, knowledge-driven methods with the abilities of cognition, generalization and life-long learning emerge as a promising way to overcome these challenges. This paper delves into the essence of knowledge-driven autonomous driving and examines its core components: dataset \& benchmark, environment, and driver agent. By leveraging large language models, world models, neural rendering, and other advanced artificial intelligence techniques, these components collectively contribute to a more holistic, adaptive, and intelligent autonomous driving system. The paper systematically organizes and reviews previous research efforts in this area, and provides insights and guidance for future research and practical applications of autonomous driving. We will continually share the latest updates on cutting-edge developments in knowledge-driven autonomous driving along with the relevant valuable open-source resources at: \url{https://github.com/PJLab-ADG/awesome-knowledge-driven-AD}.
On the Road with GPT-4V: Early Explorations of Visual-Language Model on Autonomous Driving
Nov 28, 2023The pursuit of autonomous driving technology hinges on the sophisticated integration of perception, decision-making, and control systems. Traditional approaches, both data-driven and rule-based, have been hindered by their inability to grasp the nuance of complex driving environments and the intentions of other road users. This has been a significant bottleneck, particularly in the development of common sense reasoning and nuanced scene understanding necessary for safe and reliable autonomous driving. The advent of Visual Language Models (VLM) represents a novel frontier in realizing fully autonomous vehicle driving. This report provides an exhaustive evaluation of the latest state-of-the-art VLM, GPT-4V(ision), and its application in autonomous driving scenarios. We explore the model's abilities to understand and reason about driving scenes, make decisions, and ultimately act in the capacity of a driver. Our comprehensive tests span from basic scene recognition to complex causal reasoning and real-time decision-making under varying conditions. Our findings reveal that GPT-4V demonstrates superior performance in scene understanding and causal reasoning compared to existing autonomous systems. It showcases the potential to handle out-of-distribution scenarios, recognize intentions, and make informed decisions in real driving contexts. However, challenges remain, particularly in direction discernment, traffic light recognition, vision grounding, and spatial reasoning tasks. These limitations underscore the need for further research and development. Project is now available on GitHub for interested parties to access and utilize: \url{https://github.com/PJLab-ADG/GPT4V-AD-Exploration}
DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models
Oct 12, 2023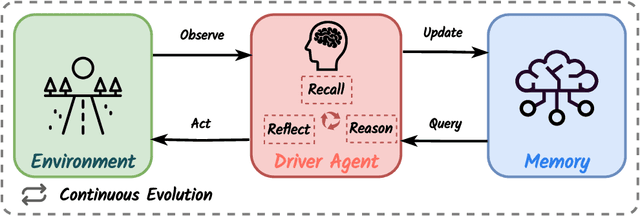
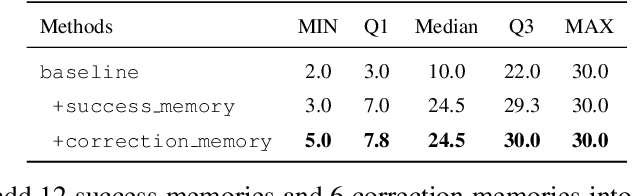
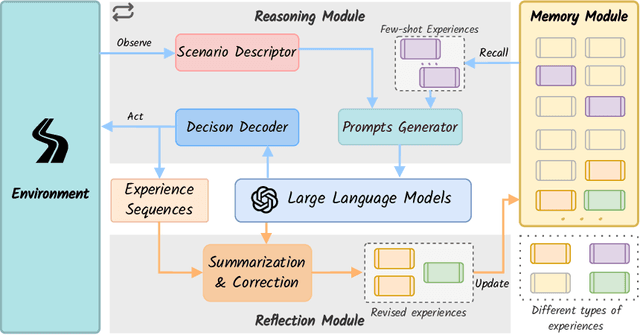
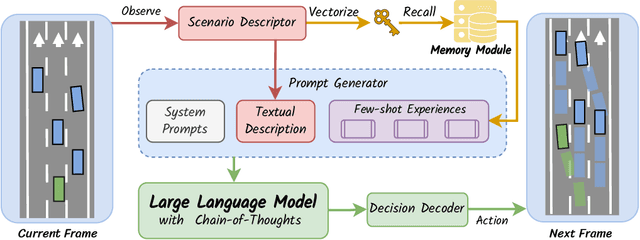
Recent advancements in autonomous driving have relied on data-driven approaches, which are widely adopted but face challenges including dataset bias, overfitting, and uninterpretability. Drawing inspiration from the knowledge-driven nature of human driving, we explore the question of how to instill similar capabilities into autonomous driving systems and summarize a paradigm that integrates an interactive environment, a driver agent, as well as a memory component to address this question. Leveraging large language models with emergent abilities, we propose the DiLu framework, which combines a Reasoning and a Reflection module to enable the system to perform decision-making based on common-sense knowledge and evolve continuously. Extensive experiments prove DiLu's capability to accumulate experience and demonstrate a significant advantage in generalization ability over reinforcement learning-based methods. Moreover, DiLu is able to directly acquire experiences from real-world datasets which highlights its potential to be deployed on practical autonomous driving systems. To the best of our knowledge, we are the first to instill knowledge-driven capability into autonomous driving systems from the perspective of how humans drive.