 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven ensemble prediction of the global ocean
Mar 20, 2026Data-driven models have advanced deterministic ocean forecasting, but extending machine learning to probabilistic global ocean prediction remains an open challenge. Here we introduce FuXi-ONS, the first machine-learning ensemble forecasting system for the global ocean, providing 5-day forecasts on a global 1° grid up to 365 days for sea-surface temperature, sea-surface height, subsurface temperature, salinity and ocean currents. Rather than relying on repeated integration of computationally expensive numerical models, FuXi-ONS learns physically structured perturbations and incorporates an atmospheric encoding module to stabilize long-range forecasts. Evaluated against GLORYS12 reanalysis, FuXi-ONS improves both ensemble-mean skill and probabilistic forecast quality relative to deterministic and noise-perturbed baselines, and shows competitive performance against established seasonal forecast references for SST and Niño3.4 variability, while running orders of magnitude faster than conventional ensemble systems. These results provide a strong example of machine learning advancing a core problem in ocean science, and establish a practical path toward efficient probabilistic ocean forecasting and climate risk assessment.
AviaSafe: A Physics-Informed Data-Driven Model for Aviation Safety-Critical Cloud Forecasts
Feb 25, 2026Current AI weather forecasting models predict conventional atmospheric variables but cannot distinguish between cloud microphysical species critical for aviation safety. We introduce AviaSafe, a hierarchical, physics-informed neural forecaster that produces global, six-hourly predictions of these four hydrometeor species for lead times up to 7 days. Our approach addresses the unique challenges of cloud prediction: extreme sparsity, discontinuous distributions, and complex microphysical interactions between species. We integrate the Icing Condition (IC) index from aviation meteorology as a physics-based constraint that identifies regions where supercooled water fuels explosive ice crystal growth. The model employs a hierarchical architecture that first predicts cloud spatial distribution through masked attention, then quantifies species concentrations within identified regions. Training on ERA5 reanalysis data, our model achieves lower RMSE for cloud species compared to baseline and outperforms operational numerical models on certain key variables at 7-day lead times. The ability to forecast individual cloud species enables new applications in aviation route optimization where distinguishing between ice and liquid water determines engine icing risk.
A unified multimodal understanding and generation model for cross-disciplinary scientific research
Jan 04, 2026Scientific discovery increasingly relies on integrating heterogeneous, high-dimensional data across disciplines nowadays. While AI models have achieved notable success across various scientific domains, they typically remain domain-specific or lack the capability of simultaneously understanding and generating multimodal scientific data, particularly for high-dimensional data. Yet, many pressing global challenges and scientific problems are inherently cross-disciplinary and require coordinated progress across multiple fields. Here, we present FuXi-Uni, a native unified multimodal model for scientific understanding and high-fidelity generation across scientific domains within a single architecture. Specifically, FuXi-Uni aligns cross-disciplinary scientific tokens within natural language tokens and employs science decoder to reconstruct scientific tokens, thereby supporting both natural language conversation and scientific numerical prediction. Empirically, we validate FuXi-Uni in Earth science and Biomedicine. In Earth system modeling, the model supports global weather forecasting, tropical cyclone (TC) forecast editing, and spatial downscaling driven by only language instructions. FuXi-Uni generates 10-day global forecasts at 0.25° resolution that outperform the SOTA physical forecasting system. It shows superior performance for both TC track and intensity prediction relative to the SOTA physical model, and generates high-resolution regional weather fields that surpass standard interpolation baselines. Regarding biomedicine, FuXi-Uni outperforms leading multimodal large language models on multiple biomedical visual question answering benchmarks. By unifying heterogeneous scientific modalities within a native shared latent space while maintaining strong domain-specific performance, FuXi-Uni provides a step forward more general-purpose, multimodal scientific models.
FuXi-RTM: A Physics-Guided Prediction Framework with Radiative Transfer Modeling
Mar 25, 2025



Similar to conventional video generation, current deep learning-based weather prediction frameworks often lack explicit physical constraints, leading to unphysical outputs that limit their reliability for operational forecasting. Among various physical processes requiring proper representation, radiation plays a fundamental role as it drives Earth's weather and climate systems. However, accurate simulation of radiative transfer processes remains challenging for traditional numerical weather prediction (NWP) models due to their inherent complexity and high computational costs. Here, we propose FuXi-RTM, a hybrid physics-guided deep learning framework designed to enhance weather forecast accuracy while enforcing physical consistency. FuXi-RTM integrates a primary forecasting model (FuXi) with a fixed deep learning-based radiative transfer model (DLRTM) surrogate that efficiently replaces conventional radiation parameterization schemes. This represents the first deep learning-based weather forecasting framework to explicitly incorporate physical process modeling. Evaluated over a comprehensive 5-year dataset, FuXi-RTM outperforms its unconstrained counterpart in 88.51% of 3320 variable and lead time combinations, with improvements in radiative flux predictions. By incorporating additional physical processes, FuXi-RTM paves the way for next-generation weather forecasting systems that are both accurate and physically consistent.
ZOPP: A Framework of Zero-shot Offboard Panoptic Perception for Autonomous Driving
Nov 08, 2024
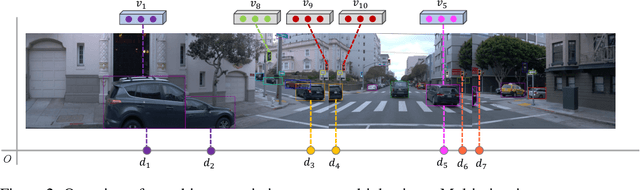


Offboard perception aims to automatically generate high-quality 3D labels for autonomous driving (AD) scenes. Existing offboard methods focus on 3D object detection with closed-set taxonomy and fail to match human-level recognition capability on the rapidly evolving perception tasks. Due to heavy reliance on human labels and the prevalence of data imbalance and sparsity, a unified framework for offboard auto-labeling various elements in AD scenes that meets the distinct needs of perception tasks is not being fully explored. In this paper, we propose a novel multi-modal Zero-shot Offboard Panoptic Perception (ZOPP) framework for autonomous driving scenes. ZOPP integrates the powerful zero-shot recognition capabilities of vision foundation models and 3D representations derived from point clouds. To the best of our knowledge, ZOPP represents a pioneering effort in the domain of multi-modal panoptic perception and auto labeling for autonomous driving scenes. We conduct comprehensive empirical studies and evaluations on Waymo open dataset to validate the proposed ZOPP on various perception tasks. To further explore the usability and extensibility of our proposed ZOPP, we also conduct experiments in downstream applications. The results further demonstrate the great potential of our ZOPP for real-world scenarios.
OASim: an Open and Adaptive Simulator based on Neural Rendering for Autonomous Driving
Feb 06, 2024With deep learning and computer vision technology development, autonomous driving provides new solutions to improve traffic safety and efficiency. The importance of building high-quality datasets is self-evident, especially with the rise of end-to-end autonomous driving algorithms in recent years. Data plays a core role in the algorithm closed-loop system. However, collecting real-world data is expensive, time-consuming, and unsafe. With the development of implicit rendering technology and in-depth research on using generative models to produce data at scale, we propose OASim, an open and adaptive simulator and autonomous driving data generator based on implicit neural rendering. It has the following characteristics: (1) High-quality scene reconstruction through neural implicit surface reconstruction technology. (2) Trajectory editing of the ego vehicle and participating vehicles. (3) Rich vehicle model library that can be freely selected and inserted into the scene. (4) Rich sensors model library where you can select specified sensors to generate data. (5) A highly customizable data generation system can generate data according to user needs. We demonstrate the high quality and fidelity of the generated data through perception performance evaluation on the Carla simulator and real-world data acquisition. Code is available at https://github.com/PJLab-ADG/OASim.
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation
Mar 16, 2022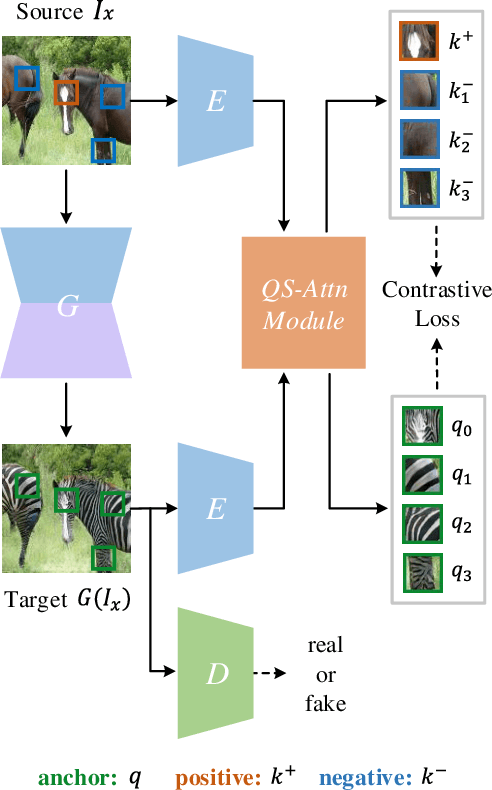
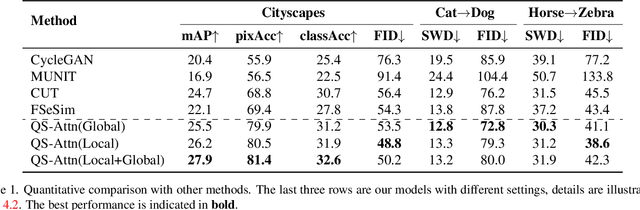

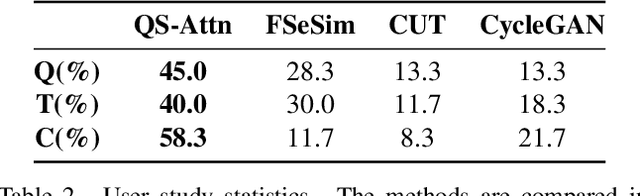
Unpaired image-to-image (I2I) translation often requires to maximize the mutual information between the source and the translated images across different domains, which is critical for the generator to keep the source content and prevent it from unnecessary modifications. The self-supervised contrastive learning has already been successfully applied in the I2I. By constraining features from the same location to be closer than those from different ones, it implicitly ensures the result to take content from the source. However, previous work uses the features from random locations to impose the constraint, which may not be appropriate since some locations contain less information of source domain. Moreover, the feature itself does not reflect the relation with others. This paper deals with these problems by intentionally selecting significant anchor points for contrastive learning. We design a query-selected attention (QS-Attn) module, which compares feature distances in the source domain, giving an attention matrix with a probability distribution in each row. Then we select queries according to their measurement of significance, computed from the distribution. The selected ones are regarded as anchors for contrastive loss. At the same time, the reduced attention matrix is employed to route features in both domains, so that source relations maintain in the synthesis. We validate our proposed method in three different I2I datasets, showing that it increases the image quality without adding learnable parameters.
Style Transformer for Image Inversion and Editing
Mar 15, 2022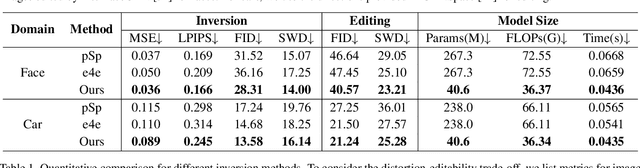
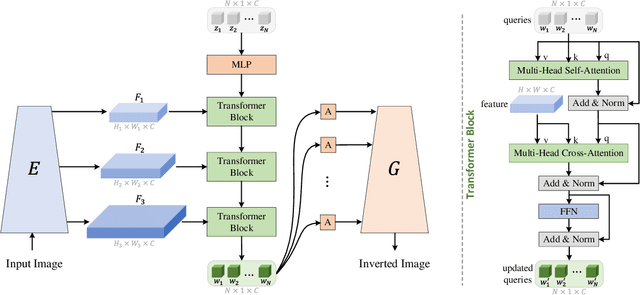
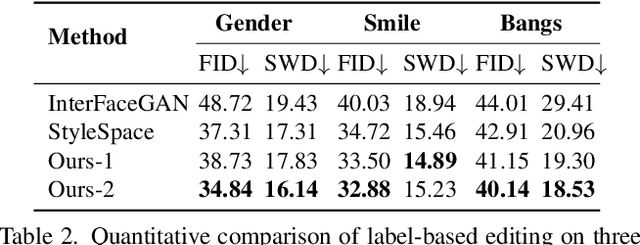
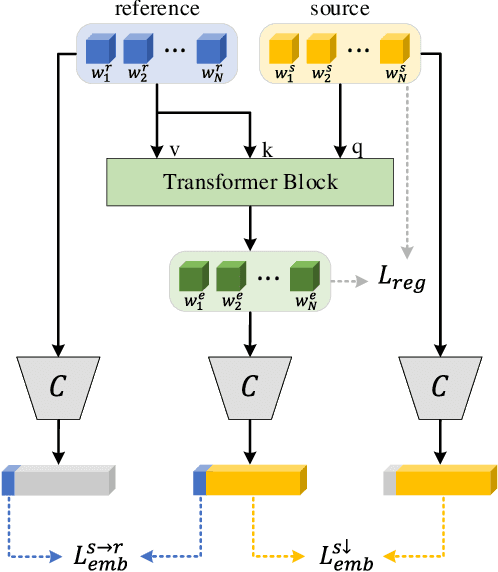
Existing GAN inversion methods fail to provide latent codes for reliable reconstruction and flexible editing simultaneously. This paper presents a transformer-based image inversion and editing model for pretrained StyleGAN which is not only with less distortions, but also of high quality and flexibility for editing. The proposed model employs a CNN encoder to provide multi-scale image features as keys and values. Meanwhile it regards the style code to be determined for different layers of the generator as queries. It first initializes query tokens as learnable parameters and maps them into W+ space. Then the multi-stage alternate self- and cross-attention are utilized, updating queries with the purpose of inverting the input by the generator. Moreover, based on the inverted code, we investigate the reference- and label-based attribute editing through a pretrained latent classifier, and achieve flexible image-to-image translation with high quality results. Extensive experiments are carried out, showing better performances on both inversion and editing tasks within StyleGAN.
Bridging the Gap between Label- and Reference-based Synthesis in Multi-attribute Image-to-Image Translation
Oct 11, 2021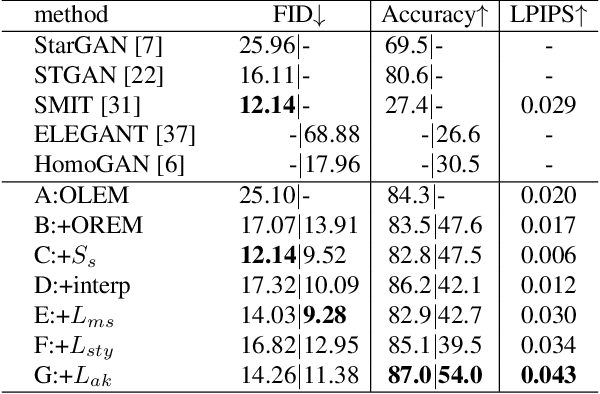
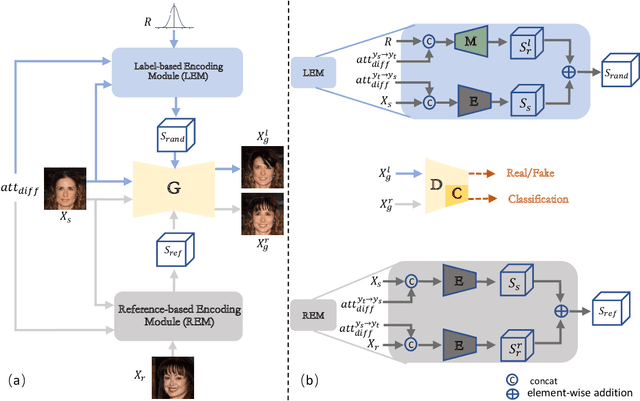


The image-to-image translation (I2IT) model takes a target label or a reference image as the input, and changes a source into the specified target domain. The two types of synthesis, either label- or reference-based, have substantial differences. Particularly, the label-based synthesis reflects the common characteristics of the target domain, and the reference-based shows the specific style similar to the reference. This paper intends to bridge the gap between them in the task of multi-attribute I2IT. We design the label- and reference-based encoding modules (LEM and REM) to compare the domain differences. They first transfer the source image and target label (or reference) into a common embedding space, by providing the opposite directions through the attribute difference vector. Then the two embeddings are simply fused together to form the latent code S_rand (or S_ref), reflecting the domain style differences, which is injected into each layer of the generator by SPADE. To link LEM and REM, so that two types of results benefit each other, we encourage the two latent codes to be close, and set up the cycle consistency between the forward and backward translations on them. Moreover, the interpolation between the S_rand and S_ref is also used to synthesize an extra image. Experiments show that label- and reference-based synthesis are indeed mutually promoted, so that we can have the diverse results from LEM, and high quality results with the similar style of the reference.
LSC-GAN: Latent Style Code Modeling for Continuous Image-to-image Translation
Oct 11, 2021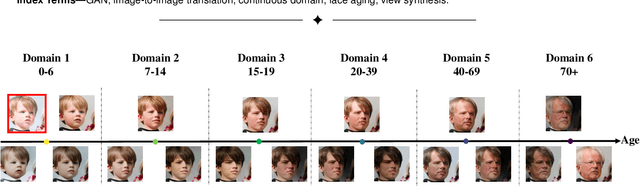

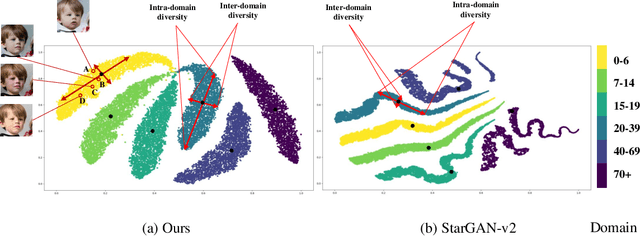
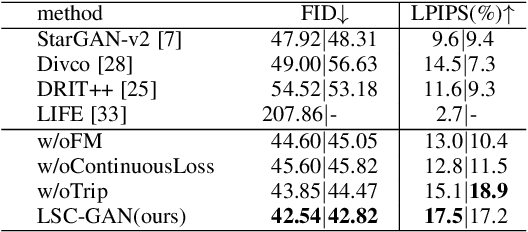
Image-to-image (I2I) translation is usually carried out among discrete domains. However, image domains, often corresponding to a physical value, are usually continuous. In other words, images gradually change with the value, and there exists no obvious gap between different domains. This paper intends to build the model for I2I translation among continuous varying domains. We first divide the whole domain coverage into discrete intervals, and explicitly model the latent style code for the center of each interval. To deal with continuous translation, we design the editing modules, changing the latent style code along two directions. These editing modules help to constrain the codes for domain centers during training, so that the model can better understand the relation among them. To have diverse results, the latent style code is further diversified with either the random noise or features from the reference image, giving the individual style code to the decoder for label-based or reference-based synthesis. Extensive experiments on age and viewing angle translation show that the proposed method can achieve high-quality results, and it is also flexible for users.