 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Medical Image-based Cancer Detection via Text-guided Supervision from Reports
May 23, 2024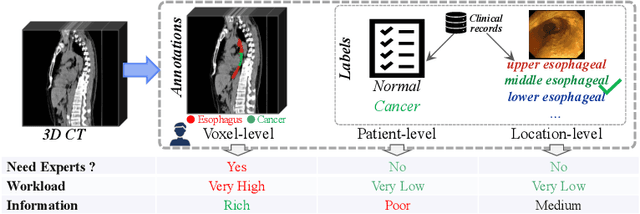
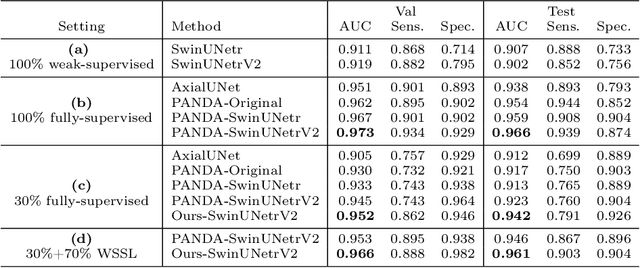
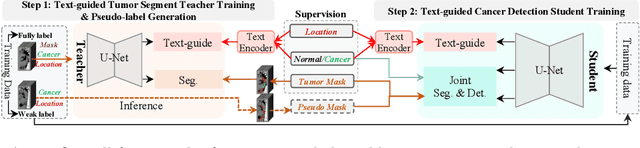
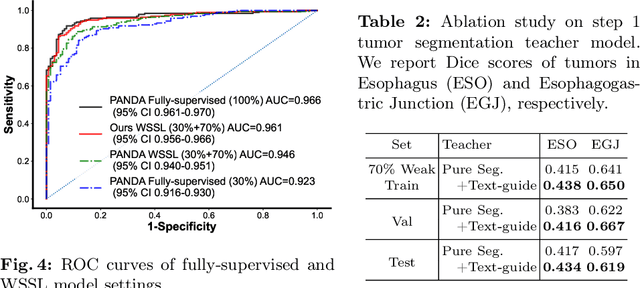
The absence of adequately sufficient expert-level tumor annotations hinders the effectiveness of supervised learning based opportunistic cancer screening on medical imaging. Clinical reports (that are rich in descriptive textual details) can offer a "free lunch'' supervision information and provide tumor location as a type of weak label to cope with screening tasks, thus saving human labeling workloads, if properly leveraged. However, predicting cancer only using such weak labels can be very changeling since tumors are usually presented in small anatomical regions compared to the whole 3D medical scans. Weakly semi-supervised learning (WSSL) utilizes a limited set of voxel-level tumor annotations and incorporates alongside a substantial number of medical images that have only off-the-shelf clinical reports, which may strike a good balance between minimizing expert annotation workload and optimizing screening efficacy. In this paper, we propose a novel text-guided learning method to achieve highly accurate cancer detection results. Through integrating diagnostic and tumor location text prompts into the text encoder of a vision-language model (VLM), optimization of weakly supervised learning can be effectively performed in the latent space of VLM, thereby enhancing the stability of training. Our approach can leverage clinical knowledge by large-scale pre-trained VLM to enhance generalization ability, and produce reliable pseudo tumor masks to improve cancer detection. Our extensive quantitative experimental results on a large-scale cancer dataset, including 1,651 unique patients, validate that our approach can reduce human annotation efforts by at least 70% while maintaining comparable cancer detection accuracy to competing fully supervised methods (AUC value 0.961 versus 0.966).
A deep local attention network for pre-operative lymph node metastasis prediction in pancreatic cancer via multiphase CT imaging
Jan 04, 2023



Lymph node (LN) metastasis status is one of the most critical prognostic and cancer staging factors for patients with resectable pancreatic ductal adenocarcinoma (PDAC), or in general, for any types of solid malignant tumors. Preoperative prediction of LN metastasis from non-invasive CT imaging is highly desired, as it might be straightforwardly used to guide the following neoadjuvant treatment decision and surgical planning. Most studies only capture the tumor characteristics in CT imaging to implicitly infer LN metastasis and very few work exploit direct LN's CT imaging information. To the best of our knowledge, this is the first work to propose a fully-automated LN segmentation and identification network to directly facilitate the LN metastasis status prediction task. Nevertheless LN segmentation/detection is very challenging since LN can be easily confused with other hard negative anatomic structures (e.g., vessels) from radiological images. We explore the anatomical spatial context priors of pancreatic LN locations by generating a guiding attention map from related organs and vessels to assist segmentation and infer LN status. As such, LN segmentation is impelled to focus on regions that are anatomically adjacent or plausible with respect to the specific organs and vessels. The metastasized LN identification network is trained to classify the segmented LN instances into positives or negatives by reusing the segmentation network as a pre-trained backbone and padding a new classification head. More importantly, we develop a LN metastasis status prediction network that combines the patient-wise aggregation results of LN segmentation/identification and deep imaging features extracted from the tumor region. Extensive quantitative nested five-fold cross-validation is conducted on a discovery dataset of 749 patients with PDAC.
Bridging the Gap between Label- and Reference-based Synthesis in Multi-attribute Image-to-Image Translation
Oct 11, 2021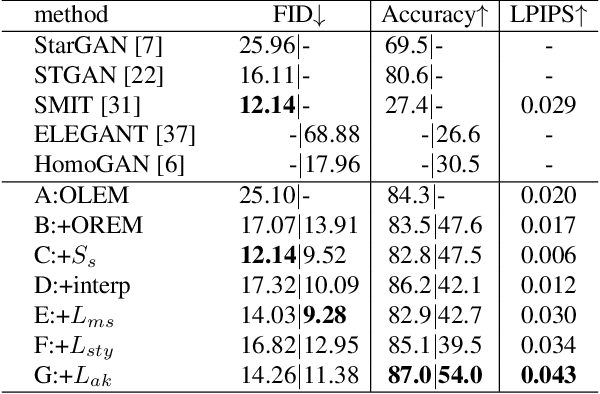
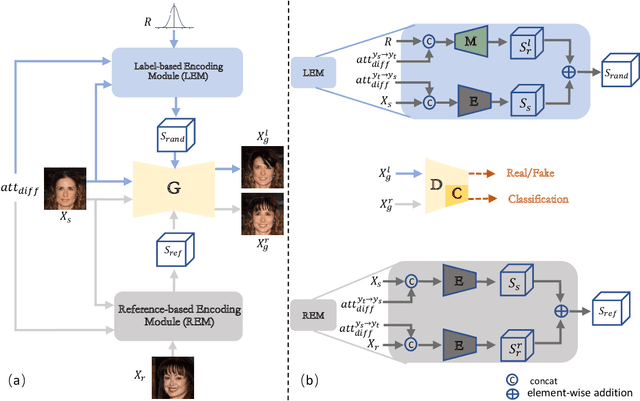


The image-to-image translation (I2IT) model takes a target label or a reference image as the input, and changes a source into the specified target domain. The two types of synthesis, either label- or reference-based, have substantial differences. Particularly, the label-based synthesis reflects the common characteristics of the target domain, and the reference-based shows the specific style similar to the reference. This paper intends to bridge the gap between them in the task of multi-attribute I2IT. We design the label- and reference-based encoding modules (LEM and REM) to compare the domain differences. They first transfer the source image and target label (or reference) into a common embedding space, by providing the opposite directions through the attribute difference vector. Then the two embeddings are simply fused together to form the latent code S_rand (or S_ref), reflecting the domain style differences, which is injected into each layer of the generator by SPADE. To link LEM and REM, so that two types of results benefit each other, we encourage the two latent codes to be close, and set up the cycle consistency between the forward and backward translations on them. Moreover, the interpolation between the S_rand and S_ref is also used to synthesize an extra image. Experiments show that label- and reference-based synthesis are indeed mutually promoted, so that we can have the diverse results from LEM, and high quality results with the similar style of the reference.
Knowledge Distillation with Adaptive Asymmetric Label Sharpening for Semi-supervised Fracture Detection in Chest X-rays
Dec 30, 2020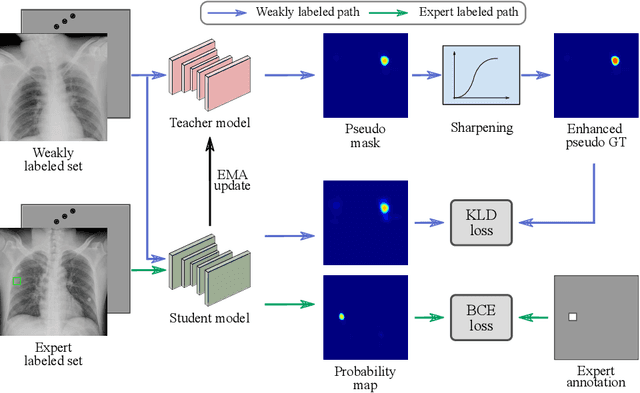
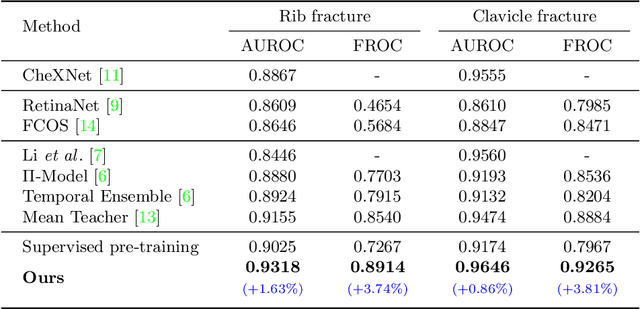
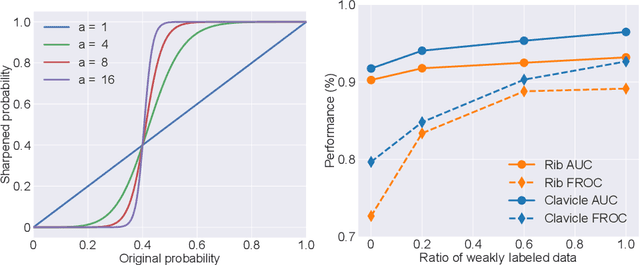
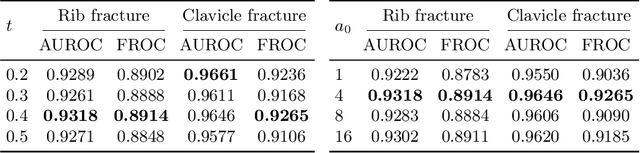
Exploiting available medical records to train high performance computer-aided diagnosis (CAD) models via the semi-supervised learning (SSL) setting is emerging to tackle the prohibitively high labor costs involved in large-scale medical image annotations. Despite the extensive attentions received on SSL, previous methods failed to 1) account for the low disease prevalence in medical records and 2) utilize the image-level diagnosis indicated from the medical records. Both issues are unique to SSL for CAD models. In this work, we propose a new knowledge distillation method that effectively exploits large-scale image-level labels extracted from the medical records, augmented with limited expert annotated region-level labels, to train a rib and clavicle fracture CAD model for chest X-ray (CXR). Our method leverages the teacher-student model paradigm and features a novel adaptive asymmetric label sharpening (AALS) algorithm to address the label imbalance problem that specially exists in medical domain. Our approach is extensively evaluated on all CXR (N = 65,845) from the trauma registry of anonymous hospital over a period of 9 years (2008-2016), on the most common rib and clavicle fractures. The experiment results demonstrate that our method achieves the state-of-the-art fracture detection performance, i.e., an area under receiver operating characteristic curve (AUROC) of 0.9318 and a free-response receiver operating characteristic (FROC) score of 0.8914 on the rib fractures, significantly outperforming previous approaches by an AUROC gap of 1.63% and an FROC improvement by 3.74%. Consistent performance gains are also observed for clavicle fracture detection.
Learning Posterior and Prior for Uncertainty Modeling in Person Re-Identification
Jul 17, 2020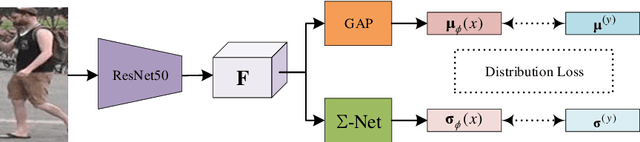
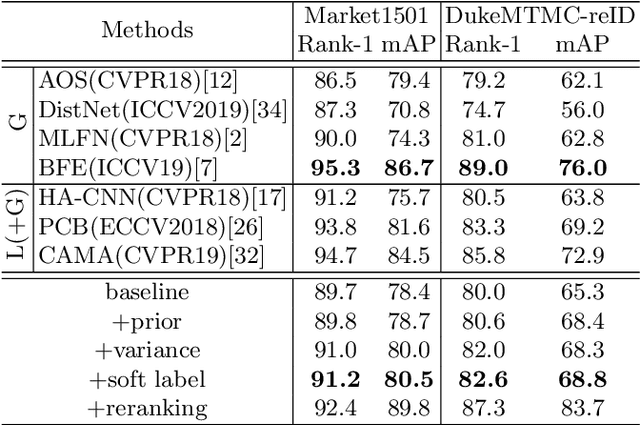
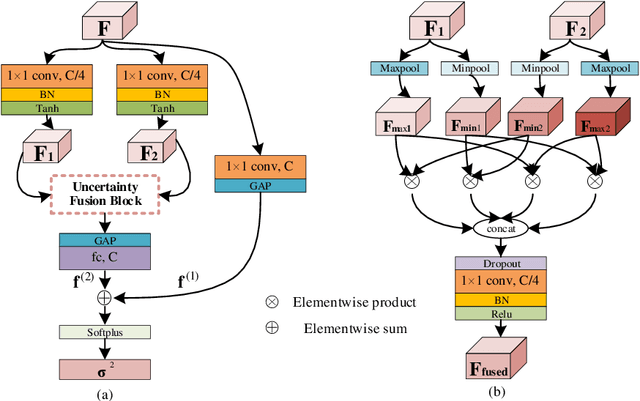
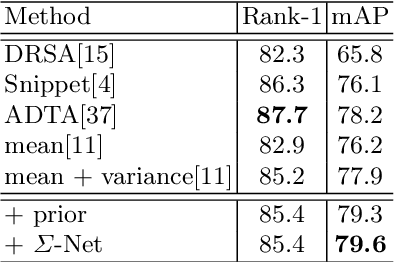
Data uncertainty in practical person reID is ubiquitous, hence it requires not only learning the discriminative features, but also modeling the uncertainty based on the input. This paper proposes to learn the sample posterior and the class prior distribution in the latent space, so that not only representative features but also the uncertainty can be built by the model. The prior reflects the distribution of all data in the same class, and it is the trainable model parameters. While the posterior is the probability density of a single sample, so it is actually the feature defined on the input. We assume that both of them are in Gaussian form. To simultaneously model them, we put forward a distribution loss, which measures the KL divergence from the posterior to the priors in the manner of supervised learning. In addition, we assume that the posterior variance, which is essentially the uncertainty, is supposed to have the second-order characteristic. Therefore, a $\Sigma-$net is proposed to compute it by the high order representation from its input. Extensive experiments have been carried out on Market1501, DukeMTMC, MARS and noisy dataset as well.
Disentangling the Spatial Structure and Style in Conditional VAE
Oct 29, 2019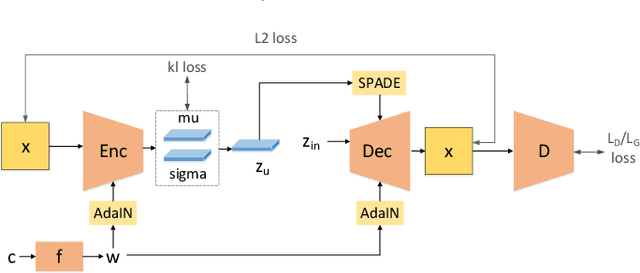


This paper aims to disentangle the latent space in cVAE into the spatial structure and the style code, which are complementary to each other, with one of them $z_s$ being label relevant and the other $z_u$ irrelevant. The generator is built by a connected encoder-decoder and a label condition mapping network. Depending on whether the label is related with the spatial structure, the output $z_s$ from the condition mapping network is used either as a style code or a spatial structure code. The encoder provides the label irrelevant posterior from which $z_u$ is sampled. The decoder employs $z_s$ and $z_u$ in each layer by adaptive normalization like SPADE or AdaIN. Extensive experiments on two datasets with different types of labels show the effectiveness of our method.
Disentangling Latent Space for VAE by Label Relevant/Irrelevant Dimensions
Jan 04, 2019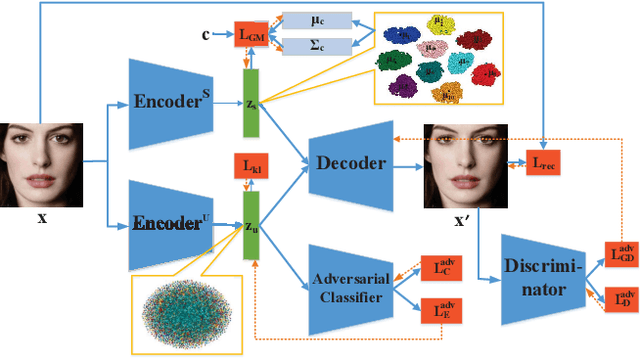
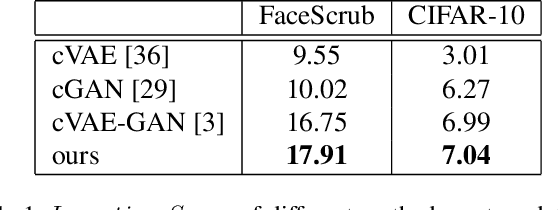
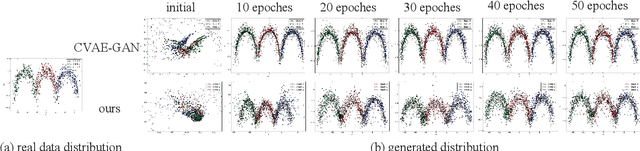
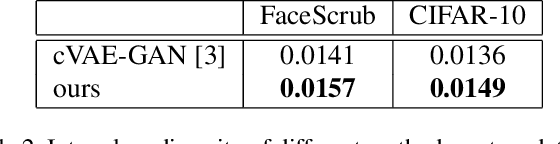
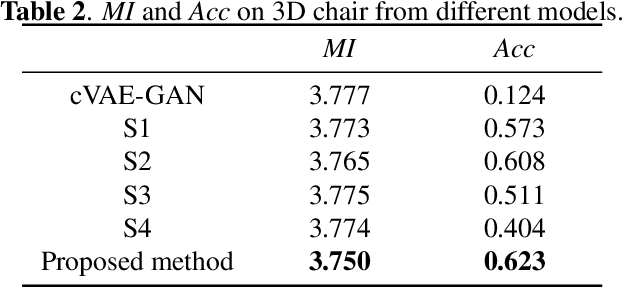
VAE requires the standard Gaussian distribution as a prior in the latent space. Since all codes tend to follow the same prior, it often suffers the so-called "posterior collapse". To avoid this, this paper introduces the class specific distribution for the latent code. But different from CVAE, we present a method for disentangling the latent space into the label relevant and irrelevant dimensions, $\bm{\mathrm{z}}_s$ and $\bm{\mathrm{z}}_u$, for a single input. We apply two separated encoders to map the input into $\bm{\mathrm{z}}_s$ and $\bm{\mathrm{z}}_u$ respectively, and then give the concatenated code to the decoder to reconstruct the input. The label irrelevant code $\bm{\mathrm{z}}_u$ represent the common characteristics of all inputs, hence they are constrained by the standard Gaussian, and their encoder is trained in amortized variational inference way, like VAE. While $\bm{\mathrm{z}}_s$ is assumed to follow the Gaussian mixture distribution in which each component corresponds to a particular class. The parameters for the Gaussian components in $\bm{\mathrm{z}}_s$ encoder are optimized by the label supervision in a global stochastic way. In theory, we show that our method is actually equivalent to adding a KL divergence term on the joint distribution of $\bm{\mathrm{z}}_s$ and the class label $c$, and it can directly increase the mutual information between $\bm{\mathrm{z}}_s$ and the label $c$. Our model can also be extended to GAN by adding a discriminator in the pixel domain so that it produces high quality and diverse images.